Data-Efficient RLVR via Off-Policy Influence Guidance
作者: Erle Zhu, Dazhi Jiang, Yuan Wang, Xujun Li, Jiale Cheng, Yuxian Gu, Yilin Niu, Aohan Zeng, Jie Tang, Minlie Huang, Hongning Wang
分类: cs.LG
发布日期: 2025-10-30
💡 一句话要点
提出CROPI,利用离线影响函数指导RLVR数据选择,提升LLM推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 数据选择 影响函数 离线策略 RLVR 推理能力 课程学习
📋 核心要点
- 现有RLVR的数据选择方法主要基于启发式,缺乏理论保证和泛化能力,难以有效提升LLM的推理能力。
- 论文提出CROPI,利用离线策略的影响函数来估计数据点对学习目标的影响,从而指导数据选择,提升训练效率。
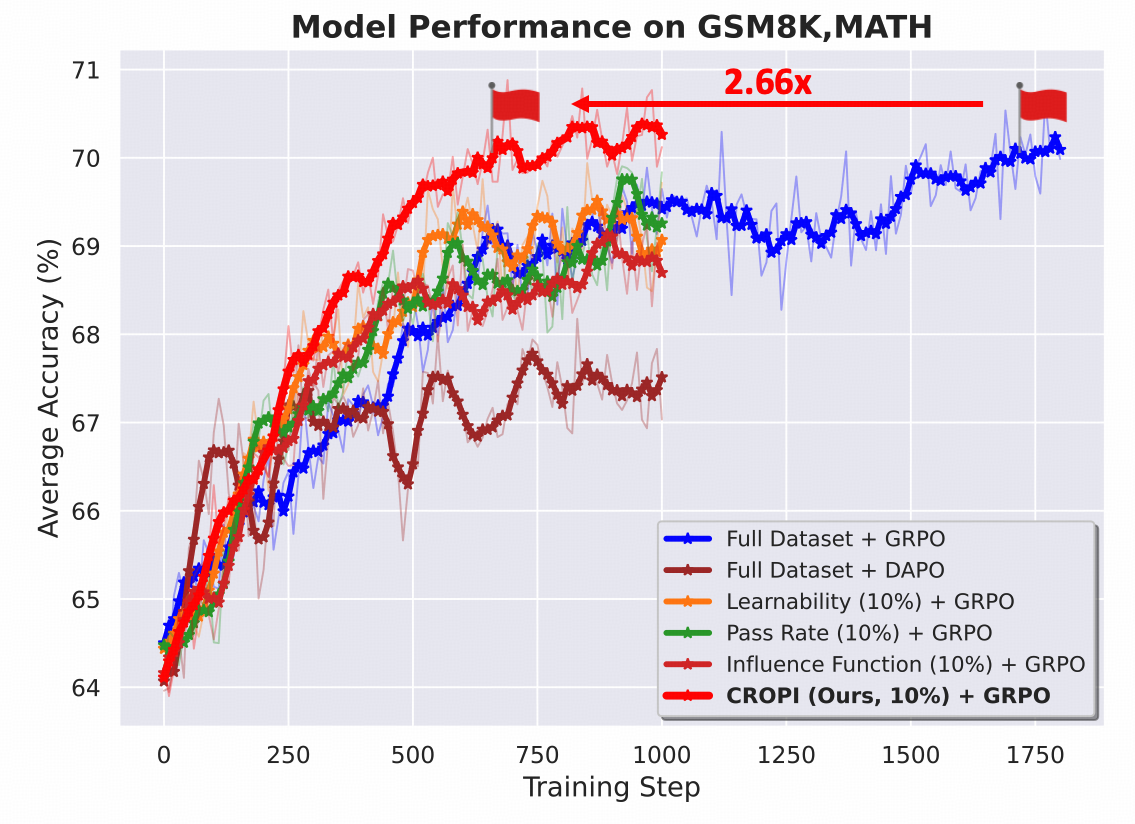
- 实验表明,CROPI在模型训练中显著加速,在1.5B模型上实现了2.66倍的步级加速,同时仅使用10%的数据。
📝 摘要(中文)
本文针对具有可验证奖励的强化学习(RLVR)中,数据选择对提升大型语言模型(LLM)推理能力至关重要的问题,提出了一种基于理论的、使用影响函数的方法来估计每个数据点对学习目标的贡献。为了克服在线影响估计所需的策略rollout带来的巨大计算成本,引入了一种离线影响估计方法,利用预先收集的离线轨迹高效地近似数据影响。此外,为了管理LLM的高维梯度,采用稀疏随机投影来降低维度,提高存储和计算效率。基于这些技术,开发了 extbf{C}urriculum extbf{R}L with extbf{O}ff- extbf{P}olicy ext{I}nfluence guidance ( extbf{CROPI}),这是一个多阶段RL框架,迭代地选择对当前策略最具影响的数据。在高达7B参数的模型上的实验表明,CROPI显著加速了训练。在一个1.5B模型上,与全数据集训练相比,CROPI实现了2.66倍的步级加速,同时每阶段仅使用10%的数据。结果突出了基于影响的数据选择在高效RLVR中的巨大潜力。
🔬 方法详解
问题定义:RLVR旨在利用强化学习提升LLM的推理能力,而数据选择是关键。现有方法依赖启发式规则,缺乏理论基础,难以保证选择的数据对模型训练真正有益,导致训练效率低下。此外,在线计算数据影响需要大量的策略rollout,计算成本高昂。
核心思路:论文的核心在于利用影响函数来量化每个数据点对模型训练的贡献程度,并选择最具影响的数据进行训练。通过离线策略的影响函数估计,避免了在线rollout带来的计算负担。稀疏随机投影则用于降低LLM高维梯度的维度,进一步提升计算效率。
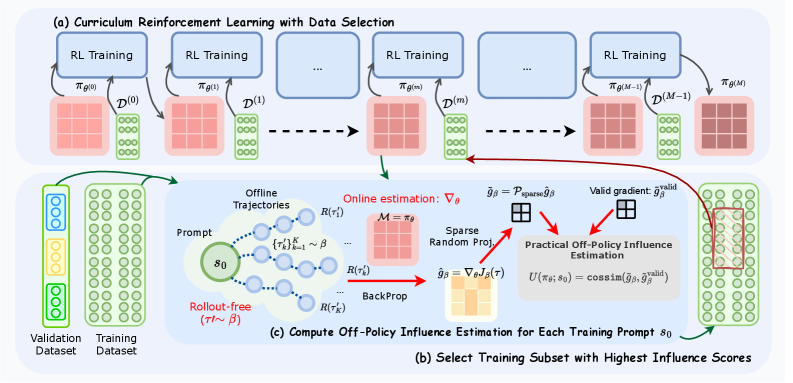
技术框架:CROPI是一个多阶段的RL框架。首先,收集离线轨迹数据。然后,利用离线策略的影响函数估计每个数据点的影响力。接着,根据影响力大小选择数据子集用于训练当前策略。重复以上步骤,迭代地选择最具影响的数据,最终训练得到高性能的LLM。
关键创新:最重要的创新在于提出了离线策略的影响函数估计方法。传统的影响函数估计需要在线rollout,计算量巨大。而CROPI利用预先收集的离线轨迹,通过重要性采样等技术,高效地近似数据影响,大大降低了计算成本。
关键设计:CROPI的关键设计包括:1) 离线影响函数的计算方法,例如使用重要性采样来校正离线数据分布与在线策略分布的差异;2) 稀疏随机投影的参数设置,例如投影矩阵的维度和稀疏度,需要在计算效率和信息损失之间进行权衡;3) 数据选择的策略,例如选择影响力最大的前10%的数据,需要在数据利用率和训练效率之间进行平衡。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CROPI在训练过程中显著加速。在1.5B参数的模型上,与全数据集训练相比,CROPI实现了2.66倍的步级加速,同时每阶段仅使用10%的数据。在更大的7B参数模型上,CROPI也表现出良好的加速效果,验证了其在大规模模型上的有效性。这些结果表明,基于影响的数据选择是提升RLVR效率的有效途径。
🎯 应用场景
该研究成果可应用于各种需要利用强化学习提升大型语言模型推理能力的场景,例如问答系统、对话生成、代码生成等。通过高效的数据选择,可以显著降低训练成本,加速模型迭代,并提升模型的性能和泛化能力。该方法还可能推广到其他机器学习任务中,用于指导数据选择和模型训练。
📄 摘要(原文)
Data selection is a critical aspect of Reinforcement Learning with Verifiable Rewards (RLVR) for enhancing the reasoning capabilities of large language models (LLMs). Current data selection methods are largely heuristic-based, lacking theoretical guarantees and generalizability. This work proposes a theoretically-grounded approach using influence functions to estimate the contribution of each data point to the learning objective. To overcome the prohibitive computational cost of policy rollouts required for online influence estimation, we introduce an off-policy influence estimation method that efficiently approximates data influence using pre-collected offline trajectories. Furthermore, to manage the high-dimensional gradients of LLMs, we employ sparse random projection to reduce dimensionality and improve storage and computation efficiency. Leveraging these techniques, we develop \textbf{C}urriculum \textbf{R}L with \textbf{O}ff-\textbf{P}olicy \text{I}nfluence guidance (\textbf{CROPI}), a multi-stage RL framework that iteratively selects the most influential data for the current policy. Experiments on models up to 7B parameters demonstrate that CROPI significantly accelerates training. On a 1.5B model, it achieves a 2.66x step-level acceleration while using only 10\% of the data per stage compared to full-dataset training. Our results highlight the substantial potential of influence-based data selection for efficient RLVR.