Co-Evolving Latent Action World Models
作者: Yucen Wang, Fengming Zhang, De-Chuan Zhan, Li Zhao, Kaixin Wang, Jiang Bian
分类: cs.LG
发布日期: 2025-10-30
💡 一句话要点
提出CoLA-World,通过协同进化学习潜在动作世界模型,提升视频生成质量和视觉规划能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 潜在动作模型 协同进化学习 视频生成 视觉规划
📋 核心要点
- 现有方法通常分两阶段训练潜在动作模型和世界模型,导致训练冗余,限制了协同适应的潜力。
- CoLA-World通过协同进化学习,利用世界模型指导潜在动作模型,反过来潜在动作模型为世界模型提供更精确的控制。
- 实验表明,CoLA-World在视频模拟质量和下游视觉规划任务中优于现有两阶段方法。
📝 摘要(中文)
本文提出了一种协同进化潜在动作世界模型(CoLA-World),旨在将预训练的视频生成模型适配为可控的世界模型。与主流的两阶段训练方法不同,CoLA-World将潜在动作模型(LAM)和世界模型联合训练,避免了冗余训练并促进了二者的协同适应。该方法直接用强大的世界模型替换LAM中的前向动态模型,并通过关键的预热阶段对齐从头开始训练的LAM与预训练世界模型的表征,解决了联合学习中的表征坍塌问题。这种协同进化循环使得世界模型能够指导LAM的学习,而LAM为世界模型提供更精确和适应性更强的控制接口。实验结果表明,CoLA-World在视频模拟质量和下游视觉规划任务中均达到或超过了现有两阶段方法,为该领域建立了一种鲁棒而高效的新范式。
🔬 方法详解
问题定义:现有方法,即两阶段训练潜在动作模型(LAM)和世界模型,存在训练冗余的问题,并且限制了LAM和世界模型之间的协同适应。直接联合训练LAM和世界模型是一个有吸引力的想法,但容易出现表征坍塌的问题。
核心思路:CoLA-World的核心思路是通过协同进化学习,让世界模型和LAM相互促进。世界模型作为“导师”,利用其先验知识指导LAM的学习,而LAM则为世界模型提供更精确和适应性更强的控制接口。通过这种方式,可以避免两阶段训练的冗余,并实现更好的性能。
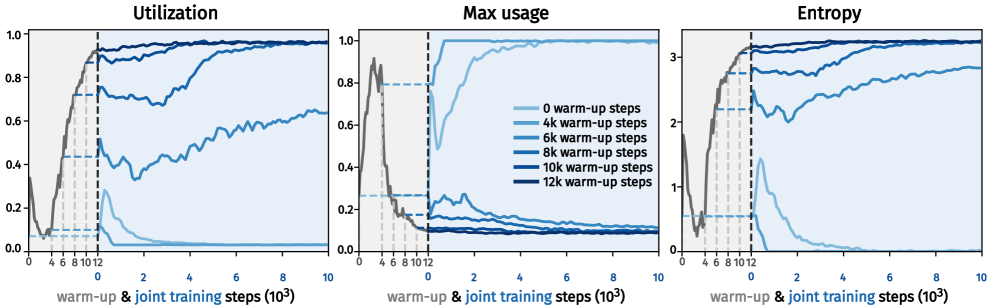
技术框架:CoLA-World的整体框架包含一个预训练的世界模型和一个从头开始训练的潜在动作模型(LAM)。关键在于一个预热(warm-up)阶段,该阶段旨在对齐LAM和世界模型的表征空间,从而避免联合训练中的表征坍塌。在预热阶段之后,LAM和世界模型进行联合训练,形成一个协同进化循环。
关键创新:CoLA-World最重要的创新点在于成功实现了LAM和世界模型的协同进化学习。通过预热阶段解决了联合训练中的表征坍塌问题,使得世界模型能够有效地指导LAM的学习,同时LAM也能够为世界模型提供更精确的控制。这是与现有两阶段方法最本质的区别。
关键设计:预热阶段是CoLA-World的关键设计。具体来说,预热阶段的目标是最小化LAM生成的潜在动作和世界模型预测的潜在状态之间的差异。损失函数可能包括KL散度或MSE等。此外,LAM的网络结构和训练方式也需要仔细设计,以确保其能够有效地学习到与世界模型兼容的表征。
🖼️ 关键图片


📊 实验亮点
CoLA-World在多个视频模拟和视觉规划任务上取得了显著的成果。实验结果表明,CoLA-World在视频生成质量和下游视觉规划任务中均达到或超过了现有两阶段方法。具体的性能提升幅度取决于具体的任务和数据集,但总体而言,CoLA-World展现了其在学习可控世界模型方面的优越性。
🎯 应用场景
CoLA-World具有广泛的应用前景,例如在机器人控制、游戏AI、自动驾驶等领域。通过学习可控的世界模型,可以使智能体更好地理解和预测环境的变化,从而做出更明智的决策。此外,该方法还可以用于生成逼真的视频内容,例如用于电影制作或虚拟现实。
📄 摘要(原文)
Adapting pre-trained video generation models into controllable world models via latent actions is a promising step towards creating generalist world models. The dominant paradigm adopts a two-stage approach that trains latent action model (LAM) and the world model separately, resulting in redundant training and limiting their potential for co-adaptation. A conceptually simple and appealing idea is to directly replace the forward dynamic model in LAM with a powerful world model and training them jointly, but it is non-trivial and prone to representational collapse. In this work, we propose CoLA-World, which for the first time successfully realizes this synergistic paradigm, resolving the core challenge in joint learning through a critical warm-up phase that effectively aligns the representations of the from-scratch LAM with the pre-trained world model. This unlocks a co-evolution cycle: the world model acts as a knowledgeable tutor, providing gradients to shape a high-quality LAM, while the LAM offers a more precise and adaptable control interface to the world model. Empirically, CoLA-World matches or outperforms prior two-stage methods in both video simulation quality and downstream visual planning, establishing a robust and efficient new paradigm for the field.