A Game-Theoretic Spatio-Temporal Reinforcement Learning Framework for Collaborative Public Resource Allocation
作者: Songxin Lei, Qiongyan Wang, Yanchen Zhu, Hanyu Yao, Sijie Ruan, Weilin Ruan, Yuyu Luo, Huaming Wu, Yuxuan Liang
分类: cs.LG, cs.CY
发布日期: 2025-10-30
💡 一句话要点
提出基于博弈论时空强化学习的公共资源协同分配框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 公共资源分配 协同优化 博弈论 强化学习 时空动态 势博弈 纳什均衡
📋 核心要点
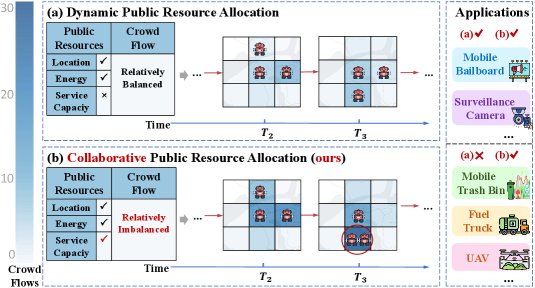
- 现有公共资源分配方法忽略了资源的容量约束和时空动态,导致实际应用受限。
- 论文提出博弈论时空强化学习(GSTRL)框架,将资源分配建模为势博弈,并利用强化学习逼近纳什均衡。
- 在真实数据集上的实验表明,GSTRL框架能够有效捕捉系统时空动态,并取得优越的性能。
📝 摘要(中文)
公共资源分配旨在高效地分配城市基础设施、能源和交通等资源,以有效满足社会需求。现有方法主要关注独立优化单个资源的移动,而忽略了其容量约束。为了解决这一局限性,本文提出了一个更实际的新问题:协同公共资源分配(CPRA),它明确地考虑了现实场景中的容量约束和时空动态。针对CPRA,我们提出了一个名为博弈论时空强化学习(GSTRL)的新框架。我们的贡献包括:1) 将CPRA问题形式化为一个势博弈,并证明了势函数与最优目标之间没有差距,为逼近这个NP-hard问题的纳什均衡奠定了坚实的理论基础;2) 我们设计的GSTRL框架有效地捕捉了整个系统的时空动态。我们在两个真实世界的数据集上评估了GSTRL,实验表明其性能优越。我们的源代码可在补充材料中找到。
🔬 方法详解
问题定义:论文旨在解决协同公共资源分配(CPRA)问题。现有方法主要关注独立优化单个资源的移动,忽略了实际场景中资源容量的限制以及资源分配的时空动态性。这种独立优化方式无法保证整体系统的效率和公平性,尤其是在资源需求高度依赖时间和空间的情况下。
核心思路:论文的核心思路是将CPRA问题建模为一个势博弈。通过将问题转化为势博弈,可以保证存在纳什均衡,并且可以通过优化势函数来逼近纳什均衡。同时,利用强化学习方法来学习每个智能体的策略,从而实现协同资源分配。这种设计能够有效地考虑资源之间的相互影响和容量约束,从而提高整体系统的效率。
技术框架:GSTRL框架主要包含以下几个模块:1) 环境建模:对公共资源分配场景进行建模,包括资源的位置、容量、需求等信息。2) 势博弈建模:将CPRA问题形式化为势博弈,定义智能体的策略空间和收益函数。3) 强化学习训练:使用强化学习算法(如Q-learning或Actor-Critic)训练每个智能体的策略,目标是最大化势函数。4) 纳什均衡逼近:通过迭代更新智能体的策略,最终逼近纳什均衡。
关键创新:论文的关键创新在于将博弈论和强化学习相结合,提出了一种新的解决CPRA问题的框架。具体来说,将CPRA问题建模为势博弈,并证明了势函数与最优目标之间没有差距,为使用强化学习逼近纳什均衡提供了理论基础。此外,GSTRL框架能够有效地捕捉整个系统的时空动态,从而实现更高效的资源分配。
关键设计:在势博弈建模方面,需要仔细设计智能体的收益函数,以反映资源之间的相互影响和容量约束。在强化学习训练方面,需要选择合适的强化学习算法和探索策略,以保证算法的收敛性和效率。此外,还需要设计合适的奖励函数,以引导智能体学习到最优的策略。具体的参数设置、损失函数和网络结构等技术细节在论文的补充材料中提供。
🖼️ 关键图片

📊 实验亮点
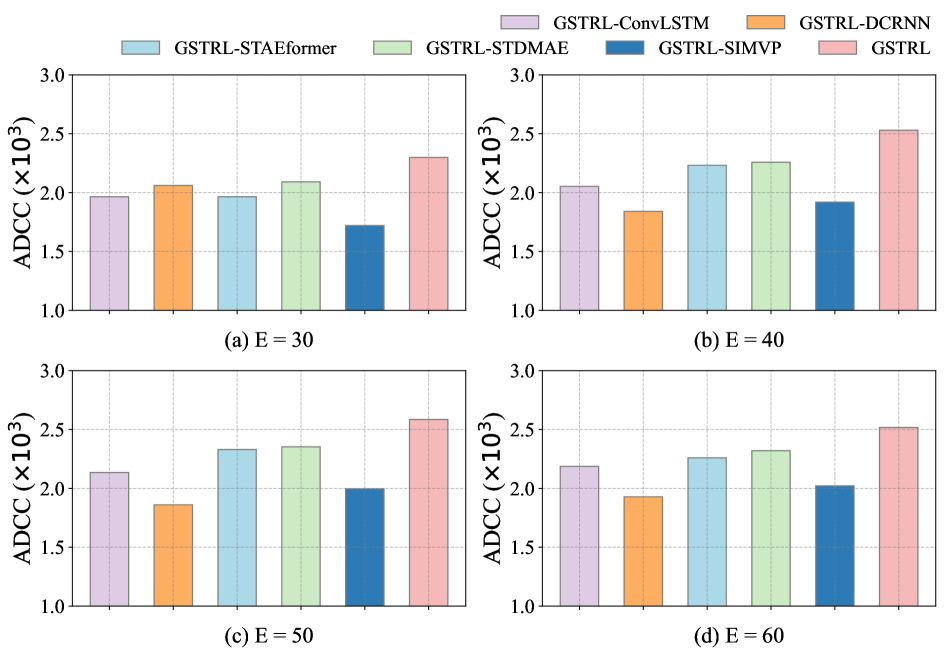
实验结果表明,GSTRL框架在两个真实世界的数据集上均取得了优越的性能。相较于现有方法,GSTRL能够更有效地捕捉系统的时空动态,并实现更高效的资源分配。具体性能提升数据在论文正文和补充材料中给出。
🎯 应用场景
该研究成果可应用于城市交通管理、能源分配、公共设施调度等领域。通过优化公共资源的分配,可以提高资源利用率,降低运营成本,提升服务质量,并最终改善城市居民的生活质量。未来,该方法可以扩展到更复杂的资源分配场景,例如多类型资源的协同分配、动态环境下的资源分配等。
📄 摘要(原文)
Public resource allocation involves the efficient distribution of resources, including urban infrastructure, energy, and transportation, to effectively meet societal demands. However, existing methods focus on optimizing the movement of individual resources independently, without considering their capacity constraints. To address this limitation, we propose a novel and more practical problem: Collaborative Public Resource Allocation (CPRA), which explicitly incorporates capacity constraints and spatio-temporal dynamics in real-world scenarios. We propose a new framework called Game-Theoretic Spatio-Temporal Reinforcement Learning (GSTRL) for solving CPRA. Our contributions are twofold: 1) We formulate the CPRA problem as a potential game and demonstrate that there is no gap between the potential function and the optimal target, laying a solid theoretical foundation for approximating the Nash equilibrium of this NP-hard problem; and 2) Our designed GSTRL framework effectively captures the spatio-temporal dynamics of the overall system. We evaluate GSTRL on two real-world datasets, where experiments show its superior performance. Our source codes are available in the supplementary materials.