ALMGuard: Safety Shortcuts and Where to Find Them as Guardrails for Audio-Language Models
作者: Weifei Jin, Yuxin Cao, Junjie Su, Minhui Xue, Jie Hao, Ke Xu, Jin Song Dong, Derui Wang
分类: cs.SD, cs.CR, cs.LG
发布日期: 2025-10-30
备注: Accepted to NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出ALMGuard,通过安全捷径激活和Mel梯度稀疏掩码防御音频-语言模型对抗攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频-语言模型 对抗攻击防御 安全捷径 Mel梯度稀疏掩码 多模态安全
📋 核心要点
- 现有音频-语言模型易受特定对抗攻击,传统防御方法效果不佳,缺乏针对性。
- ALMGuard通过寻找并激活模型中固有的安全捷径,实现对对抗攻击的有效防御。
- 实验表明,ALMGuard能显著降低攻击成功率至4.6%,同时保持模型在正常任务上的性能。
📝 摘要(中文)
音频-语言模型(ALM)的最新进展显著提升了多模态理解能力。然而,音频模态的引入也带来了新的和独特的脆弱性。以往的研究表明,直接从传统音频对抗攻击或基于文本的大型语言模型(LLM)越狱攻击中转移过来的防御措施,对于这些ALM特定的威胁在很大程度上是无效的。为了解决这个问题,我们提出了ALMGuard,这是第一个专门为ALM量身定制的防御框架。基于ALM中自然存在安全对齐捷径的假设,我们设计了一种方法来识别通用捷径激活扰动(SAP),这些扰动作为触发器,在推理时激活安全捷径以保护ALM。为了更好地筛选出有效的触发器,同时保持模型在良性任务上的效用,我们进一步提出了Mel-梯度稀疏掩码(M-GSM),它将扰动限制在对越狱敏感但对语音理解不敏感的Mel频率箱中。理论分析和实验结果都表明了我们的方法对于已知和未知攻击的鲁棒性。总的来说,ALMGuard将高级ALM特定越狱攻击的平均成功率降低到4.6%,同时保持了在良性基准上的可比效用,使其成为新的最先进水平。我们的代码和数据可在https://github.com/WeifeiJin/ALMGuard获得。
🔬 方法详解
问题定义:论文旨在解决音频-语言模型(ALM)容易受到对抗性攻击的问题,特别是针对ALM设计的越狱攻击。现有的防御方法,例如直接从音频对抗攻击或文本LLM越狱攻击中迁移过来的方法,在防御这些ALM特定的攻击时效果不佳。因此,需要一种专门为ALM设计的防御框架。
核心思路:论文的核心思路是假设ALM中存在“安全捷径”,即模型在训练过程中学习到的一些能够快速识别并响应安全相关输入的模式。通过找到并激活这些安全捷径,可以有效地防御对抗性攻击。论文设计了一种方法来识别通用捷径激活扰动(SAP),这些扰动可以作为触发器来激活安全捷径。
技术框架:ALMGuard的整体框架包括两个主要部分:1) 识别通用捷径激活扰动(SAP)。2) 使用Mel-梯度稀疏掩码(M-GSM)来优化这些扰动,使其对越狱攻击敏感,但对语音理解不敏感。该框架在推理阶段使用,通过将SAP添加到输入音频中,激活安全捷径,从而防御对抗性攻击。
关键创新:该论文的关键创新在于提出了“安全捷径”的概念,并设计了一种方法来识别和激活这些捷径。与传统的对抗防御方法不同,ALMGuard不是直接对抗对抗性扰动,而是通过激活模型自身的安全机制来防御攻击。此外,M-GSM的使用进一步提高了防御的有效性和实用性。
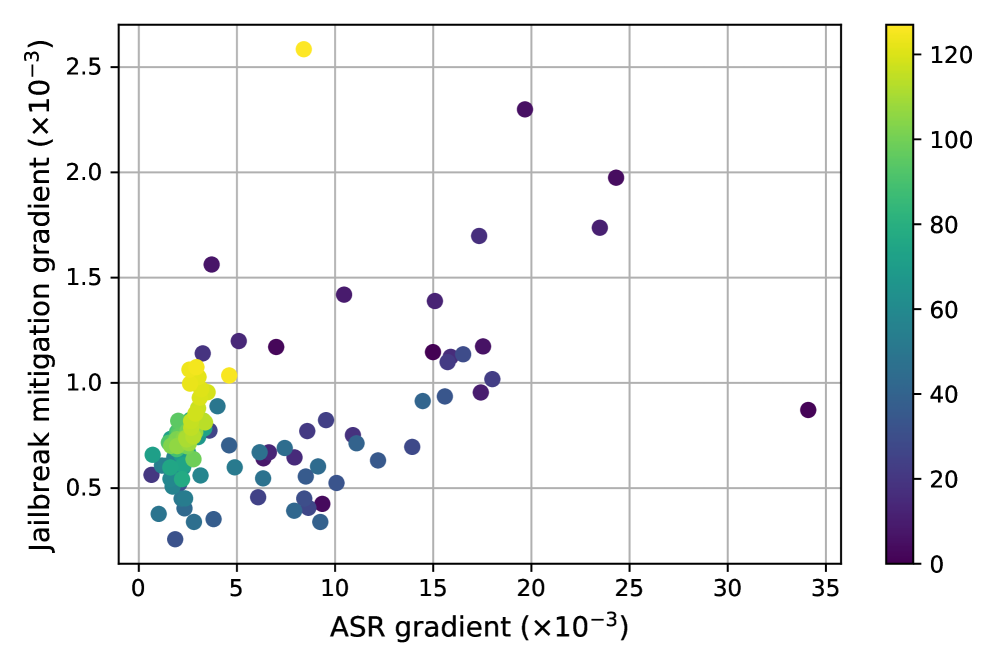
关键设计:M-GSM通过计算Mel频率箱的梯度,并应用稀疏掩码,来限制扰动只作用于对越狱攻击敏感的频率箱。具体来说,论文计算了模型输出关于Mel频率箱的梯度,并使用这些梯度来确定哪些频率箱对越狱攻击最敏感。然后,论文应用一个稀疏掩码,只允许在这些敏感的频率箱中添加扰动。这种设计可以有效地激活安全捷径,同时避免对语音理解造成干扰。
🖼️ 关键图片

📊 实验亮点
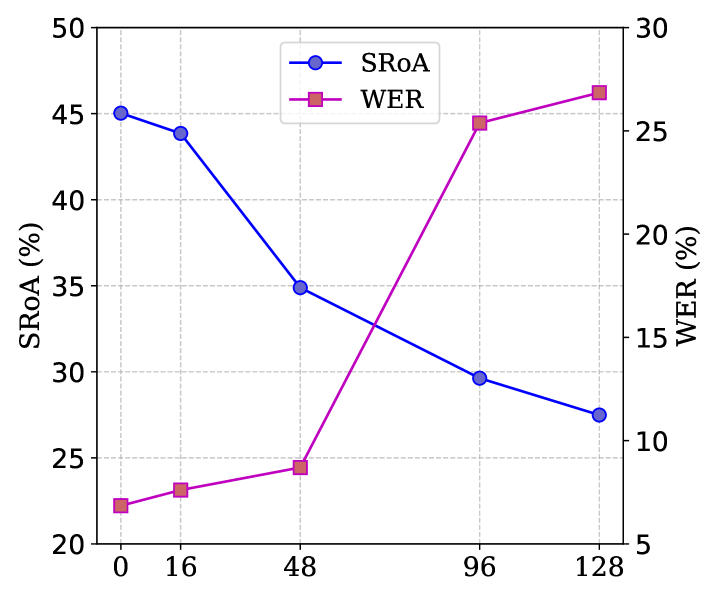
ALMGuard在四个不同的音频-语言模型上进行了评估,实验结果表明,该方法能够将高级ALM特定越狱攻击的平均成功率降低到4.6%,显著优于现有的防御方法。同时,ALMGuard在良性基准测试中保持了与原始模型相当的性能,表明其在防御攻击的同时,不会对模型的正常使用造成显著影响。
🎯 应用场景
ALMGuard可应用于各种需要安全可靠的音频-语言模型应用场景,例如智能助手、语音识别系统、多模态内容审核等。该研究有助于提升多模态AI系统的安全性,降低恶意攻击的风险,为构建更值得信赖的人工智能系统奠定基础。
📄 摘要(原文)
Recent advances in Audio-Language Models (ALMs) have significantly improved multimodal understanding capabilities. However, the introduction of the audio modality also brings new and unique vulnerability vectors. Previous studies have proposed jailbreak attacks that specifically target ALMs, revealing that defenses directly transferred from traditional audio adversarial attacks or text-based Large Language Model (LLM) jailbreaks are largely ineffective against these ALM-specific threats. To address this issue, we propose ALMGuard, the first defense framework tailored to ALMs. Based on the assumption that safety-aligned shortcuts naturally exist in ALMs, we design a method to identify universal Shortcut Activation Perturbations (SAPs) that serve as triggers that activate the safety shortcuts to safeguard ALMs at inference time. To better sift out effective triggers while preserving the model's utility on benign tasks, we further propose Mel-Gradient Sparse Mask (M-GSM), which restricts perturbations to Mel-frequency bins that are sensitive to jailbreaks but insensitive to speech understanding. Both theoretical analyses and empirical results demonstrate the robustness of our method against both seen and unseen attacks. Overall, \MethodName reduces the average success rate of advanced ALM-specific jailbreak attacks to 4.6% across four models, while maintaining comparable utility on benign benchmarks, establishing it as the new state of the art. Our code and data are available at https://github.com/WeifeiJin/ALMGuard.