Generalizing Test-time Compute-optimal Scaling as an Optimizable Graph
作者: Fali Wang, Jihai Chen, Shuhua Yang, Runxue Bao, Tianxiang Zhao, Zhiwei Zhang, Xianfeng Tang, Hui Liu, Qi He, Suhang Wang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-29
备注: Under review
💡 一句话要点
提出Agent-REINFORCE框架,解决测试时计算量约束下多LLM组合与架构的优化问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 测试时缩放 多模型协作 概率图优化 强化学习 LLM代理 架构搜索
📋 核心要点
- 现有测试时缩放方法通常采用固定的模型协作架构,忽略了不同任务下最优架构和模型组合的差异。
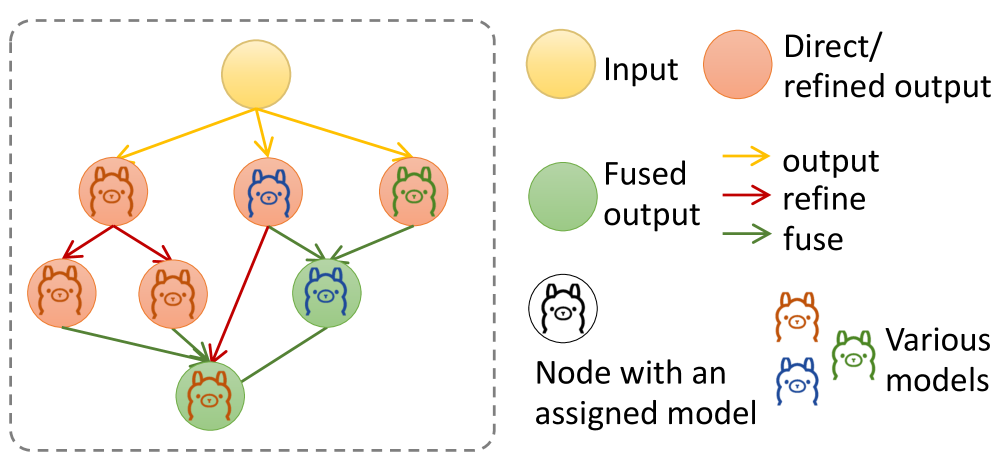
- Agent-REINFORCE将问题转化为概率图优化,利用LLM代理生成和优化多LLM协作图,以寻找计算量约束下的最优模型组合。
- 实验结果表明,Agent-REINFORCE在样本效率和搜索性能上优于传统和LLM基线,能有效平衡准确性和推理延迟。
📝 摘要(中文)
测试时缩放(TTS)通过在推理期间分配额外的计算资源来改进大型语言模型(LLM),通常通过并行、顺序或混合缩放实现。然而,以往的研究通常假设固定的协作架构(例如,拓扑结构)和单一模型的使用,忽略了最佳架构和模型组合可能因任务而异。因此,我们研究了一个新的问题,即在固定预算下搜索TTS中计算最优的模型组合和架构。我们将其形式化为一个多LLM协作图,其中节点编码角色和LLM模型分配,边捕获信息流。这个问题具有挑战性,因为(i)组合搜索空间非常大,并且(ii)特定于任务的需求需要定制设计。为了解决这些问题,我们将问题重新表述为概率图优化,并通过初步实验,获得了关于TTS协作图的三个经验性见解。在这些见解的指导下,我们提出了Agent-REINFORCE,一个LLM代理增强框架,它通过将采样-梯度-更新映射到采样-反馈-更新来镜像REINFORCE流程,其中反馈充当文本梯度来更新概率图,并有效地搜索最优的多LLM协作图。实验表明,Agent-REINFORCE在样本效率和搜索性能方面优于传统和基于LLM的基线,并且有效地识别了在准确性和推理延迟的联合目标下的最优图。
🔬 方法详解
问题定义:论文旨在解决测试时计算量受限情况下,如何自动搜索最优的多LLM协作架构和模型组合的问题。现有方法通常采用固定的协作架构,无法根据任务特性进行调整,导致性能受限。此外,手动设计协作架构需要大量专家知识和实验,效率低下。
核心思路:论文的核心思路是将多LLM协作架构搜索问题转化为概率图优化问题,并利用LLM作为代理来探索和优化这个图。通过学习一个概率图,可以有效地表示不同模型组合和协作方式的概率分布,从而在搜索过程中更高效地找到最优解。这种方法允许根据任务需求动态调整模型组合和架构,从而提高性能。
技术框架:Agent-REINFORCE框架主要包含以下几个阶段:1) 采样 (Sampling):从概率图中采样得到一个多LLM协作图,该图定义了模型组合和协作方式。2) 反馈 (Feedback):使用采样得到的协作图进行推理,并根据推理结果(例如,准确率和延迟)生成文本反馈。3) 更新 (Update):利用文本反馈作为“文本梯度”,更新概率图,使得更有可能产生性能更好的协作图。这个过程类似于强化学习中的REINFORCE算法,但使用文本反馈代替数值梯度。
关键创新:Agent-REINFORCE的关键创新在于使用LLM作为代理来生成和优化多LLM协作图。与传统的基于数值梯度的优化方法不同,Agent-REINFORCE利用LLM的自然语言理解和生成能力,将性能反馈转化为文本信息,从而更有效地指导搜索过程。这种方法可以更好地利用LLM的知识和推理能力,从而找到更优的协作架构。
关键设计:Agent-REINFORCE的关键设计包括:1) 概率图表示:使用概率图来表示多LLM协作架构,其中节点表示模型角色和模型分配,边表示信息流。2) 文本反馈生成:设计合适的提示语,使得LLM能够根据推理结果生成有意义的文本反馈。3) 概率图更新策略:使用文本反馈来更新概率图,例如,增加性能好的协作图的概率,降低性能差的协作图的概率。
🖼️ 关键图片

📊 实验亮点
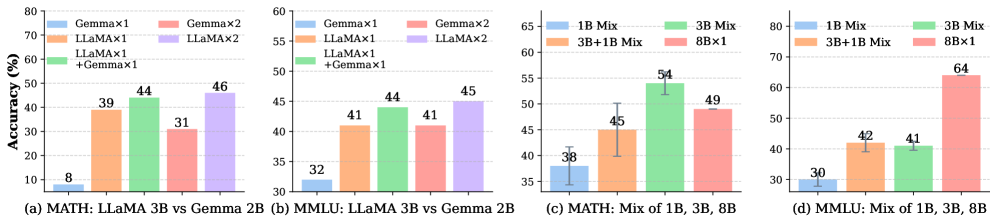
实验结果表明,Agent-REINFORCE在多个任务上都优于传统和基于LLM的基线方法。例如,在某些任务上,Agent-REINFORCE的准确率比最佳基线提高了5%以上,同时显著降低了推理延迟。此外,Agent-REINFORCE在样本效率方面也表现出色,能够在较少的迭代次数内找到最优的协作架构。
🎯 应用场景
该研究成果可应用于各种需要利用多个LLM进行推理的场景,例如智能客服、内容生成、知识问答等。通过自动优化模型组合和协作架构,可以提高推理准确率、降低延迟,并降低人工设计成本。未来,该方法有望推广到更广泛的多智能体协作领域。
📄 摘要(原文)
Test-Time Scaling (TTS) improves large language models (LLMs) by allocating additional computation during inference, typically through parallel, sequential, or hybrid scaling. However, prior studies often assume fixed collaboration architectures (e.g., topologies) and single-model usage, overlooking that optimal architectures and model combinations can vary across tasks. Therefore, we study the novel problem of searching for compute-optimal model combinations and architectures in TTS under a fixed budget. We formalize it as a multi-LLM collaboration graph, where nodes encode roles and LLM model assignments, and edges capture information flow. This problem is challenging because (i) the combinatorial search space is prohibitively large, and (ii) task-specific requirements demand tailored designs. To address these, we reformulate the problem as probabilistic graph optimization and, through pilot experiments, derive three empirical insights into TTS collaboration graphs. Guided by these insights, we propose Agent-REINFORCE, an LLM-agent-augmented framework that mirrors the REINFORCE pipeline by mapping sampling-gradient-update to sampling-feedback-update, where feedback serves as a textual gradient to update the probabilistic graph and efficiently search for optimal multi-LLM collaboration graphs. Experiments show that Agent-REINFORCE outperforms both traditional and LLM-based baselines in sample efficiency and search performance, and effectively identifies optimal graphs under joint objectives of accuracy and inference latency.