FaCT: Faithful Concept Traces for Explaining Neural Network Decisions
作者: Amin Parchami-Araghi, Sukrut Rao, Jonas Fischer, Bernt Schiele
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-10-29
备注: Accepted to NeurIPS 2025; Code is available at https://github.com/m-parchami/FaCT
💡 一句话要点
FaCT:提出可信的概念追踪方法,用于解释神经网络决策过程
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经网络解释性 概念学习 模型忠实性 可解释人工智能 图像分类
📋 核心要点
- 现有基于概念的神经网络解释方法通常不够忠实,且对概念的性质有诸多限制性假设。
- FaCT提出一种模型内在的概念解释方法,概念跨类别共享,并可忠实追踪其对logit的贡献。
- 引入C$^2$-Score评估概念一致性,实验表明FaCT在概念一致性和可解释性上优于现有方法,同时保持了ImageNet性能。
📝 摘要(中文)
深度网络在各种任务中表现出卓越的性能,但从全局概念层面理解它们如何运作仍然是一个关键挑战。许多事后基于概念的方法被引入来理解它们的工作原理,但它们并不总是忠实于模型。此外,它们对模型学习的概念做出了限制性假设,例如类别特异性、小空间范围或与人类期望的对齐。在这项工作中,我们强调了这种基于概念的解释的忠实性,并提出了一种具有模型内在机制概念解释的新模型。我们的概念在类之间共享,并且从任何层,它们对logit的贡献和它们的输入可视化都可以被忠实地追踪。我们还利用基础模型提出了一种新的概念一致性度量,C$^2$-Score,可以用来评估基于概念的方法。我们表明,与之前的工作相比,我们的概念在数量上更加一致,用户发现我们的概念更易于解释,同时保持了具有竞争力的ImageNet性能。
🔬 方法详解
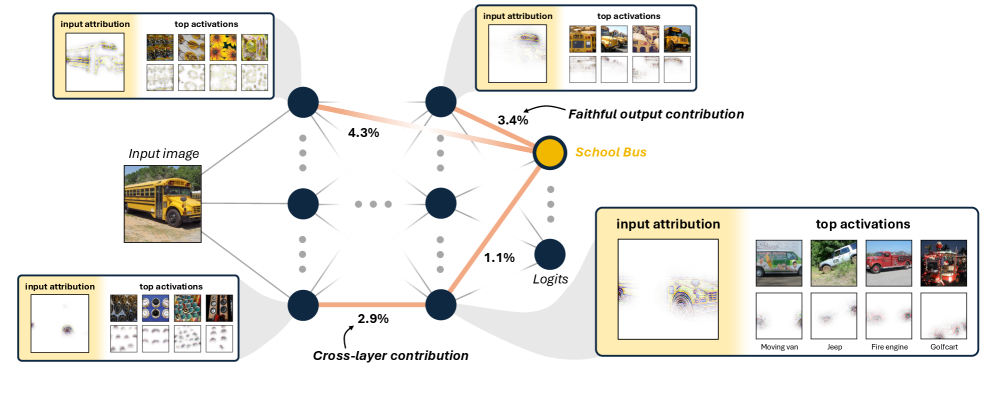
问题定义:现有基于概念的神经网络解释方法存在不忠实于模型本身的问题,并且对模型学习到的概念做出了诸多限制性假设,例如概念的类别特异性、空间范围较小以及与人类期望对齐等。这些限制使得模型难以提供全局且准确的概念层面的理解。
核心思路:FaCT的核心思路是设计一种模型内在的机制,使得概念的解释与模型的决策过程紧密结合,从而保证解释的忠实性。通过跨类别共享概念,并允许从任何层追踪概念对logit的贡献,从而提供更全面的解释。利用预训练的foundation model来评估概念的一致性,确保概念的合理性。
技术框架:FaCT的技术框架主要包含以下几个部分:1) 模型内在的概念表示学习模块,用于学习跨类别的共享概念;2) 概念追踪模块,用于追踪每个概念对logit的贡献,并可视化其输入;3) 基于foundation model的概念一致性评估模块,使用C$^2$-Score评估概念的合理性。整体流程是从输入图像开始,通过模型学习概念表示,然后追踪概念对logit的贡献,最后使用C$^2$-Score评估概念的一致性。
关键创新:FaCT最重要的技术创新点在于其模型内在的概念解释机制,这种机制保证了解释的忠实性,避免了事后解释方法可能存在的不一致性问题。此外,C$^2$-Score的引入提供了一种新的评估概念一致性的方法,可以更客观地评估不同解释方法的优劣。与现有方法的本质区别在于,FaCT不是事后分析,而是将概念解释融入到模型训练过程中。
关键设计:FaCT的关键设计包括:1) 跨类别共享的概念表示,允许模型学习更通用的概念;2) 可追踪的概念贡献,使得可以清晰地了解每个概念对最终决策的影响;3) C$^2$-Score的计算方法,利用预训练的foundation model来评估概念的一致性。具体的损失函数和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FaCT在概念一致性方面优于现有方法,用户也认为FaCT的概念更易于理解。同时,FaCT在ImageNet数据集上保持了具有竞争力的性能,表明其在提高可解释性的同时,没有牺牲模型的准确性。C$^2$-Score被证明是一个有效的概念一致性评估指标(具体数值未知)。
🎯 应用场景
该研究成果可应用于提升神经网络的可解释性和可信度,尤其是在医疗诊断、自动驾驶等高风险领域。通过理解模型决策背后的概念,可以更好地诊断模型的潜在问题,并提高用户对模型的信任度。未来,该方法可以扩展到其他类型的模型和任务中,例如自然语言处理和强化学习。
📄 摘要(原文)
Deep networks have shown remarkable performance across a wide range of tasks, yet getting a global concept-level understanding of how they function remains a key challenge. Many post-hoc concept-based approaches have been introduced to understand their workings, yet they are not always faithful to the model. Further, they make restrictive assumptions on the concepts a model learns, such as class-specificity, small spatial extent, or alignment to human expectations. In this work, we put emphasis on the faithfulness of such concept-based explanations and propose a new model with model-inherent mechanistic concept-explanations. Our concepts are shared across classes and, from any layer, their contribution to the logit and their input-visualization can be faithfully traced. We also leverage foundation models to propose a new concept-consistency metric, C$^2$-Score, that can be used to evaluate concept-based methods. We show that, compared to prior work, our concepts are quantitatively more consistent and users find our concepts to be more interpretable, all while retaining competitive ImageNet performance.