Non-myopic Matching and Rebalancing in Large-Scale On-Demand Ride-Pooling Systems Using Simulation-Informed Reinforcement Learning
作者: Farnoosh Namdarpour, Joseph Y. J. Chow
分类: cs.LG, cs.AI, cs.CY
发布日期: 2025-10-28
💡 一句话要点
提出基于模拟增强强化学习的非近视匹配与重平衡算法,提升大规模按需拼车系统效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 按需拼车 强化学习 模拟增强 非近视决策 车辆重平衡
📋 核心要点
- 现有拼车系统决策短视,忽略长期影响,导致效率降低和资源浪费。
- 利用模拟增强强化学习,学习长期状态价值,实现非近视的车辆匹配和重平衡策略。
- 实验表明,该方法能显著提升服务率,降低等待时间,并减少所需车队规模。
📝 摘要(中文)
拼车服务能够降低乘客和运营商的成本,并减少交通拥堵和环境影响。然而,现有拼车系统决策通常是短视的,忽略了调度决策的长期影响。为了解决这个问题,我们提出了一种基于模拟增强的强化学习(RL)方法。虽然强化学习已广泛应用于网约车系统,但在拼车系统中的应用相对较少。本研究将Xu等人(2018)的学习和规划框架从网约车扩展到拼车,通过在学习机制中嵌入拼车模拟,实现非近视决策。此外,我们还提出了一种互补的空闲车辆重平衡策略。通过对模拟经验进行n步时序差分学习,我们推导出时空状态值,并使用纽约市出租车请求数据评估非近视策略的有效性。结果表明,与短视策略相比,非近视匹配策略可以将服务率提高高达8.4%,同时减少乘客的车内时间和等待时间。此外,在保持相同性能水平的情况下,所提出的非近视策略可以将车队规模减少超过25%,从而为运营商节省大量成本。将重平衡操作纳入所提出的框架,与仅使用该框架进行匹配决策相比,等待时间最多可减少27.3%,车内时间减少12.5%,服务率提高15.1%,但代价是每位乘客的车辆行驶里程增加。
🔬 方法详解
问题定义:论文旨在解决大规模按需拼车系统中,由于决策的短视性导致的效率低下问题。现有方法通常只考虑当前的需求和车辆状态,而忽略了未来的潜在需求和车辆分布变化,导致服务率不高、乘客等待时间长、车辆利用率低等问题。
核心思路:论文的核心思路是利用强化学习来学习一个非近视的车辆匹配和重平衡策略。通过模拟拼车系统的运行,强化学习智能体可以学习到不同状态下的长期价值,从而做出更优的决策。这种方法能够考虑到未来一段时间内的需求变化和车辆分布情况,从而提高系统的整体效率。
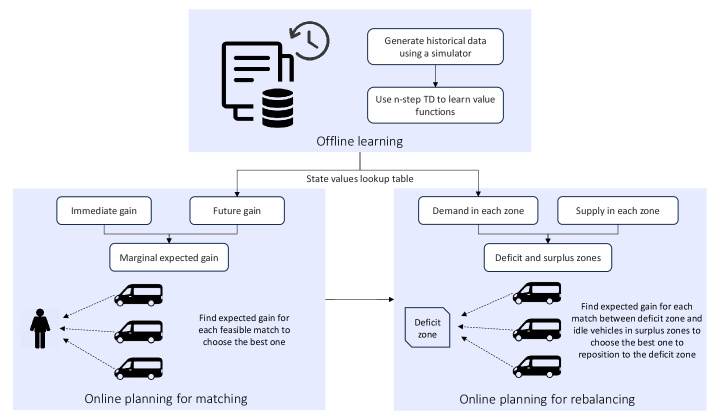
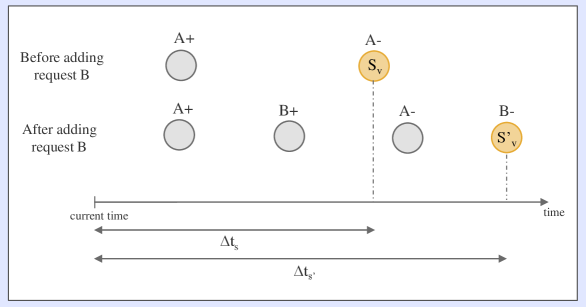
技术框架:整体框架包含以下几个主要模块:1) 拼车系统模拟器:用于模拟拼车系统的运行,包括乘客请求的生成、车辆的调度和行驶等。2) 强化学习智能体:负责学习车辆匹配和重平衡策略。3) 状态表示:将拼车系统的状态表示为强化学习智能体的输入。4) 奖励函数:用于评估强化学习智能体的行为。5) 学习算法:使用n步时序差分学习算法来更新强化学习智能体的策略。
关键创新:最重要的技术创新点在于将拼车系统模拟器嵌入到强化学习的训练过程中,从而使智能体能够学习到非近视的策略。与传统的强化学习方法相比,这种方法能够更好地考虑到拼车系统的动态性和复杂性。此外,论文还提出了一种互补的空闲车辆重平衡策略,进一步提高了系统的效率。
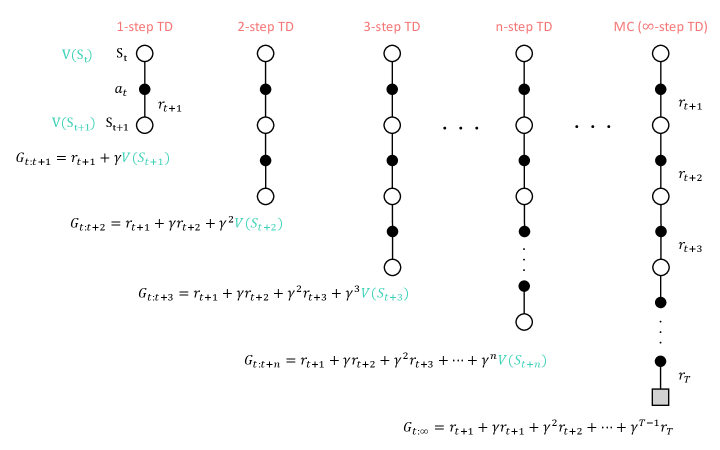
关键设计:论文使用了n步时序差分学习算法,其中n是一个重要的参数,控制了智能体考虑的未来时间步数。状态表示包括车辆的位置、乘客的需求、时间等信息。奖励函数的设计目标是最大化服务率、最小化乘客等待时间和车内时间,并最小化车辆的行驶里程。
🖼️ 关键图片
📊 实验亮点
实验结果表明,与短视策略相比,该方法可以将服务率提高高达8.4%,同时减少乘客的车内时间和等待时间。此外,在保持相同性能水平的情况下,该方法可以将车队规模减少超过25%。结合重平衡策略后,等待时间最多可减少27.3%,车内时间减少12.5%,服务率提高15.1%。
🎯 应用场景
该研究成果可应用于实际的按需拼车服务平台,提升运营效率和服务质量。通过更智能的车辆匹配和重平衡策略,可以减少乘客等待时间,降低运营成本,并提高车辆利用率。此外,该方法还可以扩展到其他交通运输领域,如公共交通调度、物流配送等。
📄 摘要(原文)
Ride-pooling, also known as ride-sharing, shared ride-hailing, or microtransit, is a service wherein passengers share rides. This service can reduce costs for both passengers and operators and reduce congestion and environmental impacts. A key limitation, however, is its myopic decision-making, which overlooks long-term effects of dispatch decisions. To address this, we propose a simulation-informed reinforcement learning (RL) approach. While RL has been widely studied in the context of ride-hailing systems, its application in ride-pooling systems has been less explored. In this study, we extend the learning and planning framework of Xu et al. (2018) from ride-hailing to ride-pooling by embedding a ride-pooling simulation within the learning mechanism to enable non-myopic decision-making. In addition, we propose a complementary policy for rebalancing idle vehicles. By employing n-step temporal difference learning on simulated experiences, we derive spatiotemporal state values and subsequently evaluate the effectiveness of the non-myopic policy using NYC taxi request data. Results demonstrate that the non-myopic policy for matching can increase the service rate by up to 8.4% versus a myopic policy while reducing both in-vehicle and wait times for passengers. Furthermore, the proposed non-myopic policy can decrease fleet size by over 25% compared to a myopic policy, while maintaining the same level of performance, thereby offering significant cost savings for operators. Incorporating rebalancing operations into the proposed framework cuts wait time by up to 27.3%, in-vehicle time by 12.5%, and raises service rate by 15.1% compared to using the framework for matching decisions alone at the cost of increased vehicle minutes traveled per passenger.