The Kinetics of Reasoning: How Chain-of-Thought Shapes Learning in Transformers?
作者: Zihan Pengmei, Costas Mavromatis, Zhengyuan Shen, Yunyi Zhang, Vassilis N. Ioannidis, Huzefa Rangwala
分类: cs.LG, cs.AI
发布日期: 2025-10-28
备注: 10 pages, 7 figures, with appendix
💡 一句话要点
研究CoT如何影响Transformer学习,揭示其加速泛化但受限于任务复杂度的特性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链 Transformer 泛化能力 学习动力学 轨迹忠实性
📋 核心要点
- 现有方法对CoT如何影响Transformer学习的机制理解不足,尤其是在泛化能力方面。
- 通过控制任务复杂度、数据分布和CoT监督,研究CoT对Transformer学习速度和泛化能力的影响。
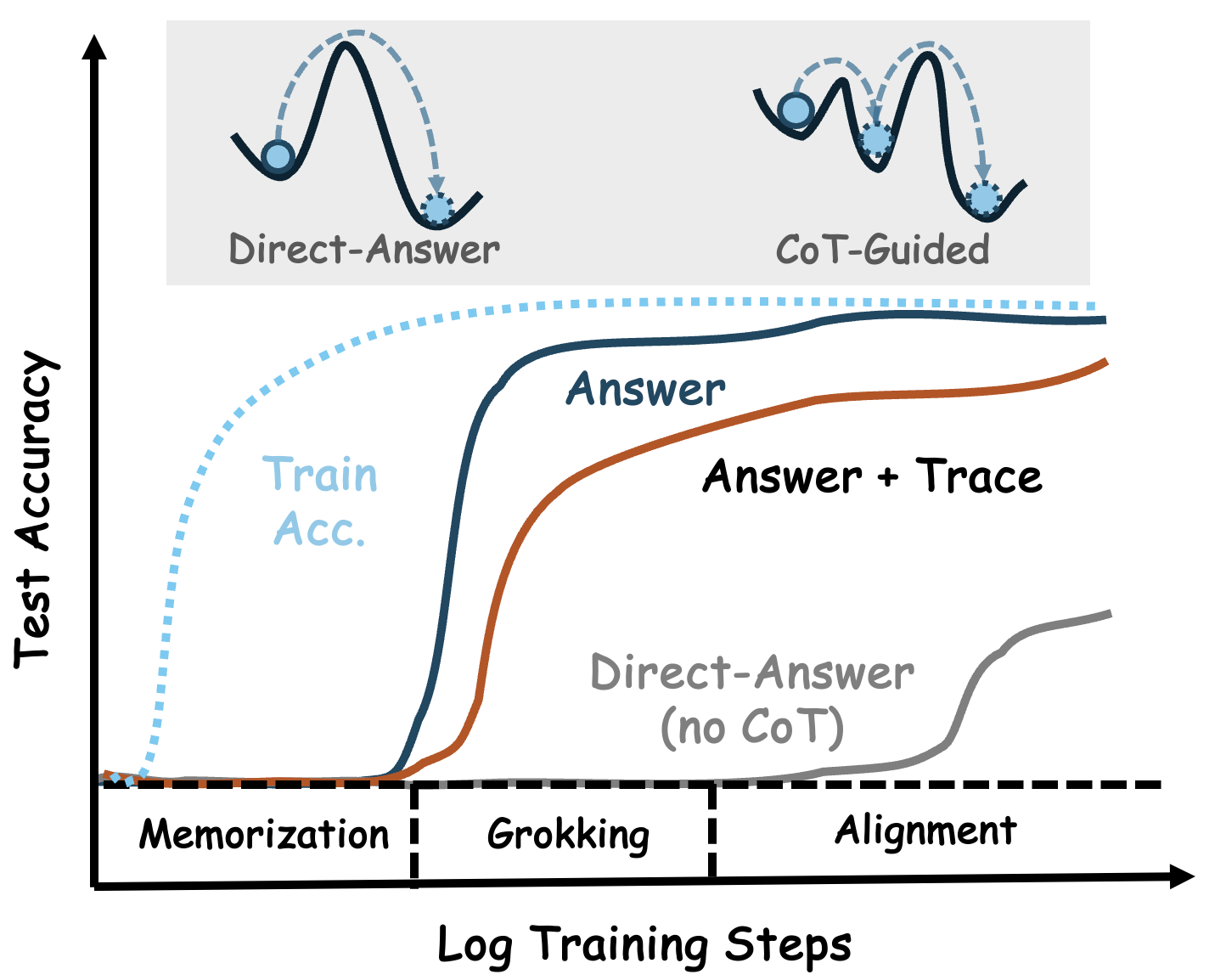
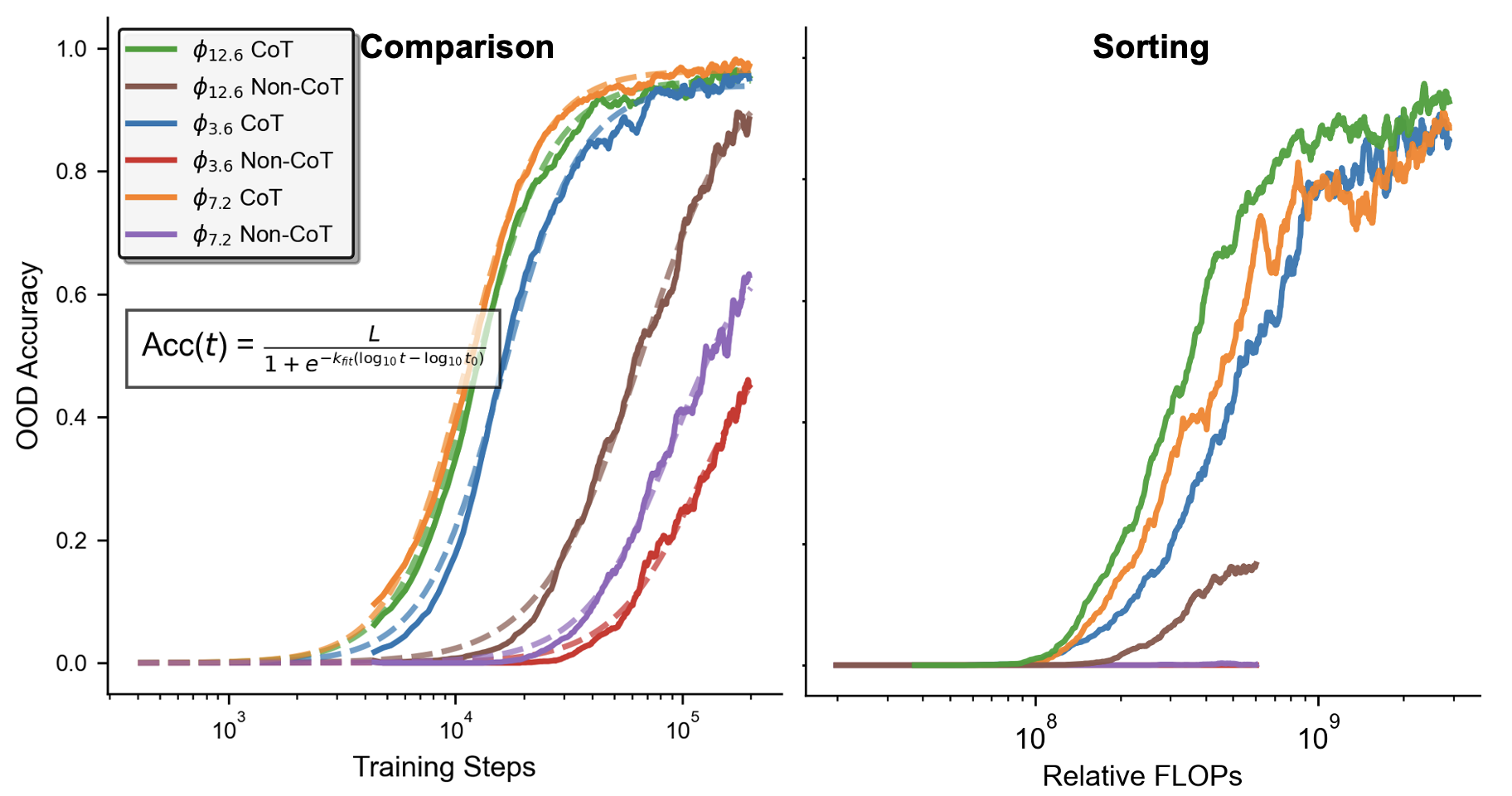
- 实验表明CoT加速泛化,但无法克服高复杂度任务,并揭示了训练早期轨迹不忠实现象。
📝 摘要(中文)
思维链(CoT)监督可以显著提高Transformer的性能,但模型学习遵循CoT并从中受益的机制仍然知之甚少。本文通过在具有可调算法复杂度和可控数据组成的符号推理任务上预训练Transformer来研究这些学习动态,并以grokking为视角来研究其泛化能力。模型在两种设置下进行训练:(i)仅生成最终答案,以及(ii)在回答之前发出显式的CoT轨迹。结果表明,虽然CoT通常可以提高任务性能,但其益处取决于任务的复杂性。为了量化这些影响,我们使用一个三参数logistic曲线对数训练步骤的准确性进行建模,揭示了学习速度和形状如何随任务复杂性、数据分布以及CoT监督的存在而变化。我们还发现了一个瞬态的轨迹不忠实阶段:在训练的早期,模型经常在跳过或矛盾CoT步骤的同时产生正确的答案,然后在稍后将其推理轨迹与答案对齐。经验上,我们(1)证明CoT加速了泛化,但不能克服具有更高算法复杂度的任务,例如查找列表交集;(2)引入了一个用于理解Transformer学习的动力学建模框架;(3)将轨迹忠实性描述为在训练过程中出现的动态属性;以及(4)展示了CoT从机制上改变了Transformer的内部计算。
🔬 方法详解
问题定义:论文旨在理解思维链(CoT)监督如何影响Transformer模型的学习过程,特别是在泛化能力方面。现有方法缺乏对CoT如何影响模型学习速度、轨迹忠实性以及处理不同复杂度任务能力的深入理解。现有方法难以解释CoT在何种情况下有效,以及CoT如何改变Transformer的内部计算。
核心思路:论文的核心思路是通过控制任务的算法复杂度、数据分布以及是否使用CoT监督,来研究Transformer在符号推理任务上的学习动态。通过观察模型在不同条件下的学习曲线、轨迹忠实性以及内部计算的变化,来揭示CoT对模型学习过程的影响。使用动力学建模框架来量化学习过程,并分析轨迹忠实性随训练的变化。
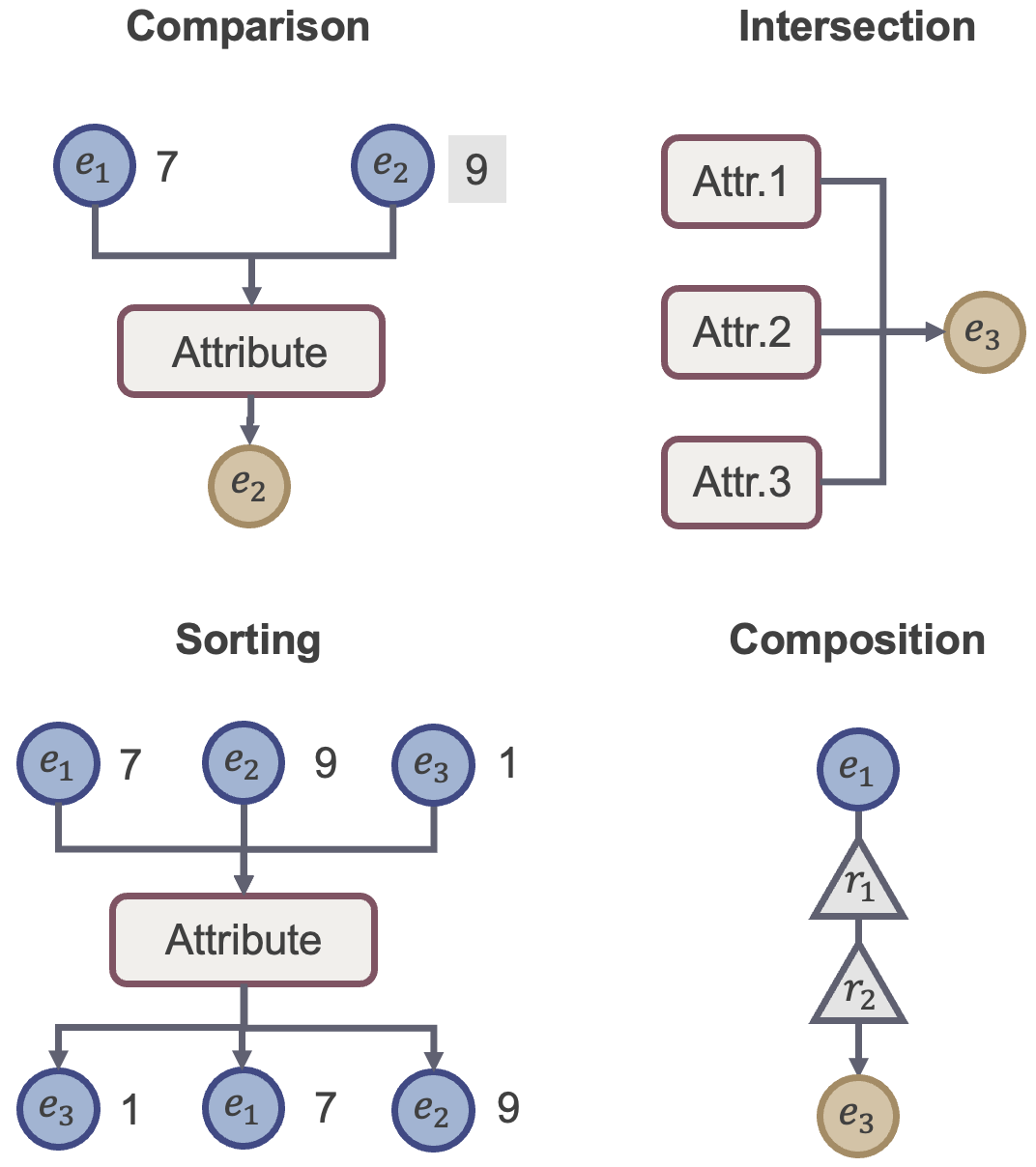
技术框架:论文的技术框架主要包括以下几个部分: 1. 任务设计:设计具有可调算法复杂度的符号推理任务,例如加法、乘法和列表交集。 2. 数据生成:生成具有可控数据分布的训练数据,例如改变训练数据的范围。 3. 模型训练:训练Transformer模型,分别在有CoT监督和无CoT监督的情况下进行训练。 4. 学习曲线建模:使用三参数logistic曲线对学习曲线进行建模,分析学习速度和形状的变化。 5. 轨迹忠实性分析:分析模型生成的CoT轨迹与最终答案的一致性,揭示轨迹不忠实现象。
关键创新:论文的关键创新点在于: 1. 动力学建模框架:引入了一种新的动力学建模框架,用于理解Transformer的学习过程,可以量化学习速度和形状的变化。 2. 轨迹忠实性分析:揭示了训练早期存在的轨迹不忠实现象,即模型在产生正确答案的同时,CoT轨迹可能不正确。 3. CoT影响机制:从机制上展示了CoT如何改变Transformer的内部计算。
关键设计:论文的关键设计包括: 1. 任务复杂度控制:通过选择不同类型的符号推理任务(如加法、乘法、列表交集)来控制任务的算法复杂度。 2. 数据分布控制:通过改变训练数据的范围来控制数据分布。 3. Logistic曲线建模:使用三参数logistic曲线来拟合学习曲线,参数包括学习速度、学习形状和最终性能。 4. 轨迹忠实性度量:设计指标来衡量模型生成的CoT轨迹与最终答案的一致性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CoT监督可以加速Transformer模型的泛化,但在处理高算法复杂度的任务(如列表交集)时,CoT的优势并不明显。研究还发现,在训练初期存在一个轨迹不忠实阶段,模型可能在CoT推理错误的情况下给出正确答案。通过动力学建模,论文量化了CoT对学习速度和形状的影响。
🎯 应用场景
该研究成果可应用于提升大型语言模型的推理能力和泛化性能,尤其是在需要复杂推理步骤的任务中。通过理解CoT如何影响模型学习,可以设计更有效的训练策略,提高模型在实际应用中的可靠性和准确性。例如,可以应用于问答系统、代码生成和数学问题求解等领域。
📄 摘要(原文)
Chain-of-thought (CoT) supervision can substantially improve transformer performance, yet the mechanisms by which models learn to follow and benefit from CoT remain poorly understood. We investigate these learning dynamics through the lens of grokking by pretraining transformers on symbolic reasoning tasks with tunable algorithmic complexity and controllable data composition to study their generalization. Models were trained under two settings: (i) producing only final answers, and (ii) emitting explicit CoT traces before answering. Our results show that while CoT generally improves task performance, its benefits depend on task complexity. To quantify these effects, we model the accuracy of the logarithmic training steps with a three-parameter logistic curve, revealing how the learning speed and shape vary with task complexity, data distribution, and the presence of CoT supervision. We also uncover a transient trace unfaithfulness phase: early in training, models often produce correct answers while skipping or contradicting CoT steps, before later aligning their reasoning traces with answers. Empirically, we (1) demonstrate that CoT accelerates generalization but does not overcome tasks with higher algorithmic complexity, such as finding list intersections; (2) introduce a kinetic modeling framework for understanding transformer learning; (3) characterize trace faithfulness as a dynamic property that emerges over training; and (4) show CoT alters internal transformer computation mechanistically.