Secure Retrieval-Augmented Generation against Poisoning Attacks
作者: Zirui Cheng, Jikai Sun, Anjun Gao, Yueyang Quan, Zhuqing Liu, Xiaohua Hu, Minghong Fang
分类: cs.CR, cs.IR, cs.LG
发布日期: 2025-10-28 (更新: 2025-11-10)
备注: To appear in IEEE BigData 2025
💡 一句话要点
提出RAGuard框架,增强检索增强生成模型抵抗数据投毒攻击的安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 数据投毒攻击 安全防御 困惑度过滤 文本相似度 非参数化方法 大型语言模型 信息安全
📋 核心要点
- 现有检索增强生成模型易受数据投毒攻击,攻击者通过污染知识库操纵模型输出,防御方法在高级攻击面前表现不佳。
- RAGuard框架通过扩大检索范围增加干净文本比例,并结合困惑度过滤和文本相似度过滤来检测投毒文本。
- 实验结果表明,RAGuard能有效检测和缓解包括自适应攻击在内的多种投毒攻击,提升了RAG模型的安全性。
📝 摘要(中文)
大型语言模型(LLMs)已经改变了自然语言处理(NLP)领域,实现了从内容生成到决策支持等多种应用。检索增强生成(RAG)通过整合外部知识来改进LLMs,但也引入了安全风险,特别是来自数据投毒的风险,攻击者将投毒文本注入知识数据库以操纵系统输出。虽然已经提出了各种防御措施,但它们通常难以应对高级攻击。为了解决这个问题,我们引入了RAGuard,这是一个旨在识别投毒文本的检测框架。RAGuard首先扩大检索范围以增加干净文本的比例,从而降低检索到投毒内容的可能性。然后,它应用chunk-wise困惑度过滤来检测异常变化,并应用文本相似度过滤来标记高度相似的文本。这种非参数方法增强了RAG的安全性,并且在大型数据集上的实验证明了其在检测和缓解投毒攻击(包括强大的自适应攻击)方面的有效性。
🔬 方法详解
问题定义:论文旨在解决检索增强生成(RAG)模型在面对数据投毒攻击时的脆弱性问题。攻击者通过向RAG模型使用的知识库中注入恶意或带有偏见的文本,从而操纵模型的输出,使其产生不准确、有害或具有误导性的内容。现有的防御方法通常难以有效应对高级的、自适应的投毒攻击,无法充分保障RAG系统的安全性。
核心思路:RAGuard的核心思路是通过一种非参数化的检测框架,在RAG模型检索阶段识别并过滤掉潜在的投毒文本,从而提高RAG模型输出的可靠性和安全性。该框架不依赖于预先训练的模型或特定的投毒模式,而是基于文本的内在特征进行检测,使其能够应对各种类型的投毒攻击。
技术框架:RAGuard框架主要包含两个阶段:1) 扩大检索范围:通过增加检索的文档数量,提高检索到的干净文本的比例,降低恶意文本被选中的概率。2) 过滤阶段:该阶段包含两个主要的过滤步骤:a) Chunk-wise困惑度过滤:将检索到的文本分割成小块,计算每个小块的困惑度,通过检测困惑度的异常变化来识别潜在的投毒文本。b) 文本相似度过滤:计算检索到的文本之间的相似度,标记高度相似的文本,因为投毒攻击者通常会注入大量相似的恶意文本。
关键创新:RAGuard的关键创新在于其非参数化的检测方法,它不依赖于任何预先训练的模型或特定的投毒模式,而是直接基于文本的内在特征(如困惑度和相似度)进行检测。这种方法使其能够应对各种类型的投毒攻击,包括那些针对特定防御机制的自适应攻击。此外,通过扩大检索范围,RAGuard进一步降低了恶意文本被选中的概率,提高了防御的有效性。
关键设计:RAGuard的关键设计包括:1) 困惑度过滤的chunk大小:选择合适的chunk大小对于检测异常变化至关重要。2) 困惑度阈值和相似度阈值的设定:这些阈值需要根据具体的数据集和攻击类型进行调整,以达到最佳的检测效果。3) 检索范围的扩大策略:需要权衡检索范围的扩大与计算成本之间的关系,选择合适的检索数量。
🖼️ 关键图片
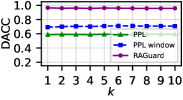
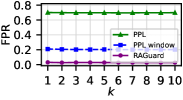
📊 实验亮点
实验结果表明,RAGuard在检测和缓解数据投毒攻击方面表现出色,尤其是在面对强大的自适应攻击时。与现有方法相比,RAGuard能够显著提高RAG模型的安全性,降低恶意文本对模型输出的影响。具体性能数据(例如检测准确率、召回率等)和对比基线的详细信息需要在论文中查找。
🎯 应用场景
RAGuard可应用于各种依赖检索增强生成模型的场景,例如问答系统、内容生成平台、智能客服等。通过提高RAG模型抵抗数据投毒攻击的能力,RAGuard能够保障这些系统的可靠性和安全性,防止恶意信息传播,维护用户信任,并为构建更安全可信的AI应用奠定基础。
📄 摘要(原文)
Large language models (LLMs) have transformed natural language processing (NLP), enabling applications from content generation to decision support. Retrieval-Augmented Generation (RAG) improves LLMs by incorporating external knowledge but also introduces security risks, particularly from data poisoning, where the attacker injects poisoned texts into the knowledge database to manipulate system outputs. While various defenses have been proposed, they often struggle against advanced attacks. To address this, we introduce RAGuard, a detection framework designed to identify poisoned texts. RAGuard first expands the retrieval scope to increase the proportion of clean texts, reducing the likelihood of retrieving poisoned content. It then applies chunk-wise perplexity filtering to detect abnormal variations and text similarity filtering to flag highly similar texts. This non-parametric approach enhances RAG security, and experiments on large-scale datasets demonstrate its effectiveness in detecting and mitigating poisoning attacks, including strong adaptive attacks.