Bayesian Neural Networks vs. Mixture Density Networks: Theoretical and Empirical Insights for Uncertainty-Aware Nonlinear Modeling
作者: Riddhi Pratim Ghosh, Ian Barnett
分类: stat.CO, cs.LG
发布日期: 2025-10-28
备注: 20 pages, 2 figures
💡 一句话要点
对比贝叶斯神经网络与混合密度网络,用于不确定性非线性建模
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 贝叶斯神经网络 混合密度网络 不确定性建模 非线性回归 变分推理
📋 核心要点
- 现有非线性回归方法难以有效量化模型的不确定性,尤其是在数据有限或存在多模态输出时。
- 论文对比研究了贝叶斯神经网络(BNNs)和混合密度网络(MDNs),分别从后验和似然角度建模不确定性。
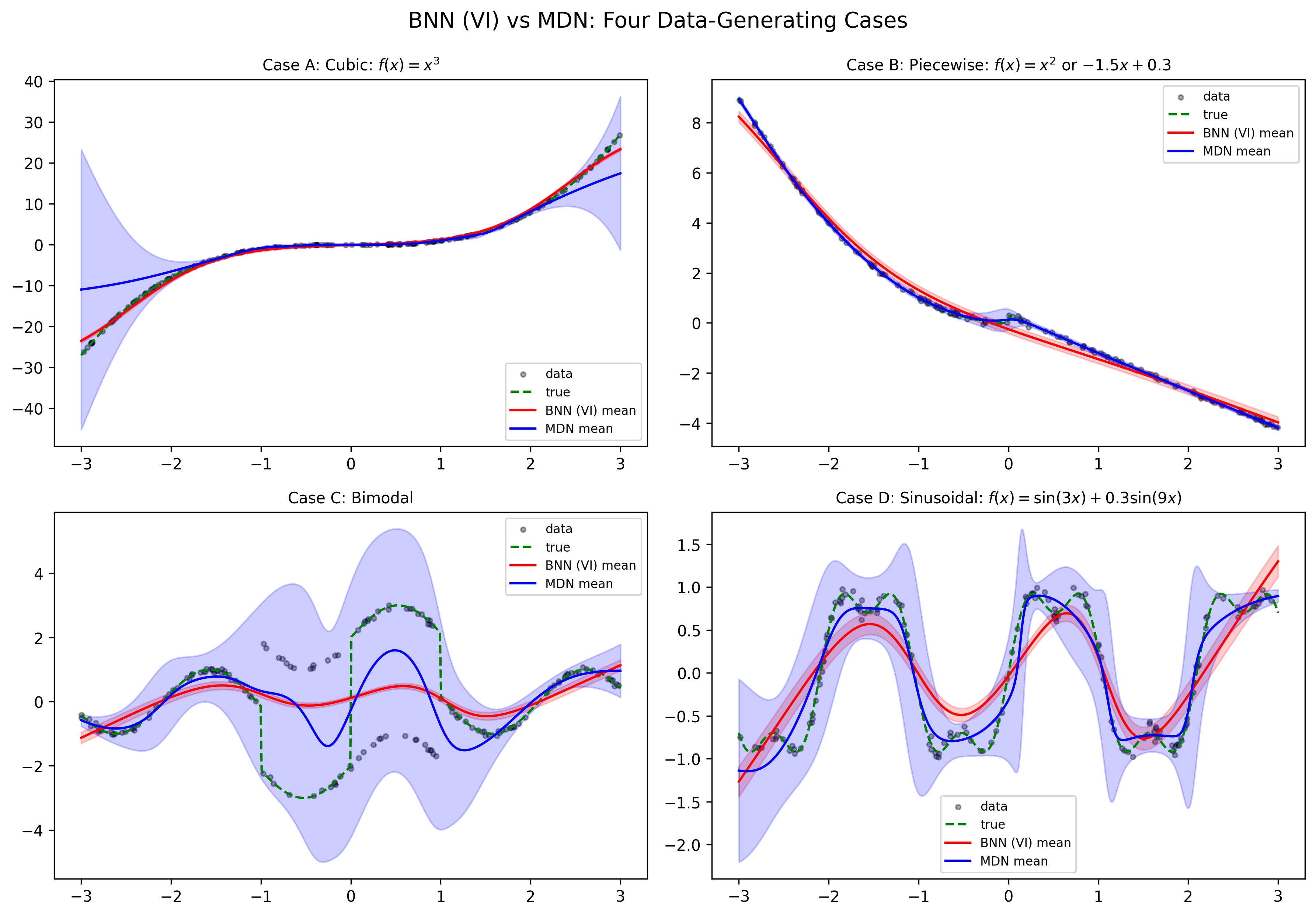
- 实验表明,MDNs更擅长捕获多模态响应和自适应不确定性,而BNNs在数据有限时提供更可解释的认知不确定性。
📝 摘要(中文)
本文研究了两种重要的概率神经建模范式:贝叶斯神经网络(BNNs)和混合密度网络(MDNs),用于不确定性非线性回归。BNNs通过在网络参数上设置先验分布来整合认知不确定性,而MDNs直接对条件输出分布进行建模,从而捕获多模态和异方差数据生成机制。我们提出了一个统一的理论和实证框架来比较这两种方法。在理论方面,我们推导了Hölder平滑条件下的收敛速度和误差界限,表明MDNs由于其基于似然的性质,实现了更快的Kullback-Leibler(KL)散度收敛,而BNNs表现出由变分推理引起的额外近似偏差。在经验方面,我们在合成非线性数据集和一个放射基准(RSNA儿科骨龄挑战赛)上评估了这两种架构。定量和定性结果表明,MDNs更有效地捕获多模态响应和自适应不确定性,而BNNs在有限数据下提供更可解释的认知不确定性。我们的发现阐明了基于后验和基于似然的概率学习的互补优势,为非线性系统中不确定性建模提供了指导。
🔬 方法详解
问题定义:论文旨在解决非线性回归问题中不确定性的有效建模问题。传统方法在处理数据量有限、输出分布复杂(如多模态)或异方差性时,难以准确估计模型的不确定性,导致预测结果的可靠性降低。
核心思路:论文的核心思路是对比研究两种概率神经建模方法:贝叶斯神经网络(BNNs)和混合密度网络(MDNs),分别从后验概率和似然函数的角度来建模不确定性。BNNs通过对网络权重引入先验分布,利用贝叶斯推断来估计后验分布,从而量化认知不确定性;MDNs则直接学习条件输出分布,能够捕获数据中的多模态和异方差性。
技术框架:整体框架包括理论分析和实证评估两部分。理论分析部分,论文推导了BNNs和MDNs在Hölder平滑条件下的收敛速度和误差界限,从理论上比较了两种方法的优劣。实证评估部分,论文在合成数据集和真实数据集(RSNA儿科骨龄挑战赛)上进行了实验,比较了两种方法在不确定性建模方面的性能。
关键创新:论文的关键创新在于:1) 提出了一个统一的理论框架,用于比较BNNs和MDNs在不确定性建模方面的性能;2) 从理论上证明了MDNs具有更快的KL散度收敛速度,而BNNs存在由变分推理引起的额外近似偏差;3) 通过实验验证了MDNs更擅长捕获多模态响应和自适应不确定性,而BNNs在数据有限时提供更可解释的认知不确定性。
关键设计:在BNNs中,使用了变分推理来近似后验分布。在MDNs中,输出层被设计为混合高斯模型,其参数(均值、方差、混合系数)由神经网络预测。损失函数方面,BNNs使用变分下界(ELBO),MDNs使用负对数似然函数。实验中,对网络结构、优化器、学习率等超参数进行了调整,以获得最佳性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在合成数据集上,MDNs能够更好地拟合多模态数据分布,并提供更准确的不确定性估计。在RSNA儿科骨龄挑战赛数据集上,MDNs在捕获异方差性方面表现更优,而BNNs在数据量有限的情况下,提供了更稳定的不确定性估计。定量指标和可视化结果均验证了理论分析的结论。
🎯 应用场景
该研究成果可应用于对预测结果的可靠性有较高要求的领域,例如医疗诊断、金融风险评估、自动驾驶等。通过准确量化模型的不确定性,可以帮助决策者更好地理解预测结果的置信度,从而做出更明智的决策。未来的研究可以探索将BNNs和MDNs结合起来,以充分利用两种方法的优势。
📄 摘要(原文)
This paper investigates two prominent probabilistic neural modeling paradigms: Bayesian Neural Networks (BNNs) and Mixture Density Networks (MDNs) for uncertainty-aware nonlinear regression. While BNNs incorporate epistemic uncertainty by placing prior distributions over network parameters, MDNs directly model the conditional output distribution, thereby capturing multimodal and heteroscedastic data-generating mechanisms. We present a unified theoretical and empirical framework comparing these approaches. On the theoretical side, we derive convergence rates and error bounds under Hölder smoothness conditions, showing that MDNs achieve faster Kullback-Leibler (KL) divergence convergence due to their likelihood-based nature, whereas BNNs exhibit additional approximation bias induced by variational inference. Empirically, we evaluate both architectures on synthetic nonlinear datasets and a radiographic benchmark (RSNA Pediatric Bone Age Challenge). Quantitative and qualitative results demonstrate that MDNs more effectively capture multimodal responses and adaptive uncertainty, whereas BNNs provide more interpretable epistemic uncertainty under limited data. Our findings clarify the complementary strengths of posterior-based and likelihood-based probabilistic learning, offering guidance for uncertainty-aware modeling in nonlinear systems.