Enhancing Hierarchical Reinforcement Learning through Change Point Detection in Time Series
作者: Hemanath Arumugam, Falong Fan, Bo Liu
分类: cs.LG
发布日期: 2025-10-28
💡 一句话要点
提出基于Transformer的变点检测模块,增强分层强化学习在长时任务中的可扩展性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分层强化学习 变点检测 Transformer 自监督学习 选项发现
📋 核心要点
- 分层强化学习(HRL)在长时任务中面临自主发现有意义子目标和学习最优选项终止边界的挑战。
- 该论文提出利用Transformer进行变点检测(CPD),自监督地分割轨迹,并将其用于指导选项发现和策略学习。
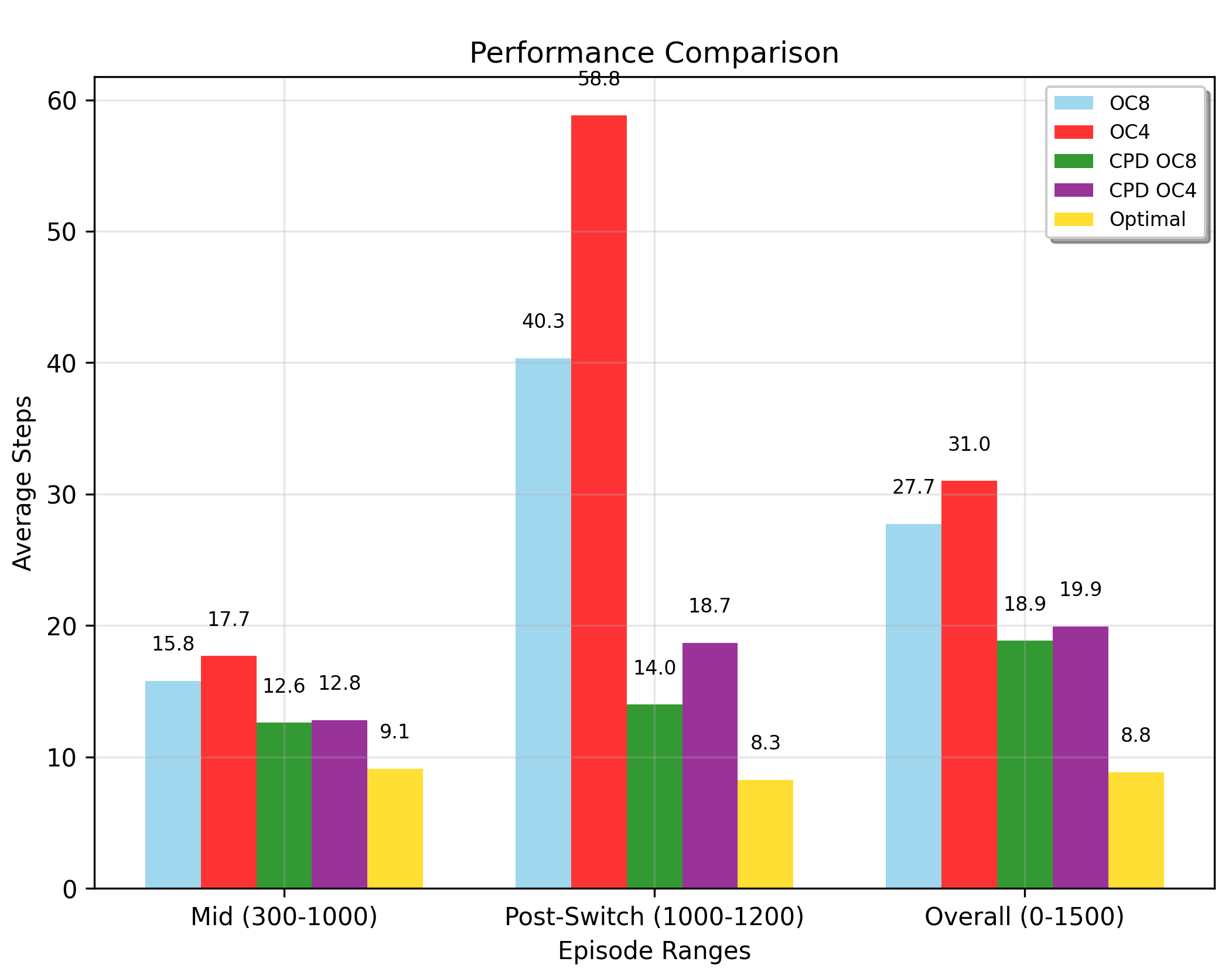
- 实验表明,CPD引导的HRL智能体在收敛速度、累积回报和选项专业化方面均有显著提升。
📝 摘要(中文)
本文提出了一种新颖的架构,该架构将自监督的、基于Transformer的变点检测(CPD)模块集成到Option-Critic框架中,从而能够自适应地分割状态轨迹并发现选项。CPD模块使用从内在信号导出的启发式伪标签进行训练,以推断环境动态中的潜在变化,无需外部监督。这些推断出的变点以三种关键方式被利用:(i)作为稳定终止函数梯度的监督信号,(ii)通过分段行为克隆来预训练选项内策略,以及(iii)通过CPD定义的状态分区上的选项间散度惩罚来强制执行功能专业化。总体优化目标使用结构感知的辅助损失来增强标准actor-critic损失。在我们的框架中,选项发现自然而然地产生,因为CPD定义的轨迹段被映射到不同的选项内策略,使智能体能够自主地将其行为划分为可重用的、语义上有意义的技能。在Four-Rooms和Pinball任务上的实验表明,CPD引导的智能体表现出加速的收敛、更高的累积回报和显著改进的选项专业化。这些发现证实,通过变点分割集成结构先验知识可以带来更可解释、样本效率更高且更稳健的分层策略。
🔬 方法详解
问题定义:分层强化学习(HRL)旨在解决复杂、长时任务中的决策问题。然而,如何自动发现有意义的子目标(选项)以及学习最优的选项终止条件仍然是一个挑战。现有的HRL方法通常依赖于人工设计的子目标或复杂的探索策略,效率较低,且难以泛化到不同的环境。
核心思路:该论文的核心思路是利用时间序列中的变点检测(Change Point Detection, CPD)来自动分割状态轨迹,从而发现潜在的子目标。通过将轨迹分割成不同的片段,每个片段对应一个选项,智能体可以学习在每个片段内执行特定的策略。这种方法的关键在于,变点能够反映环境动态的变化,从而帮助智能体识别有意义的子目标。
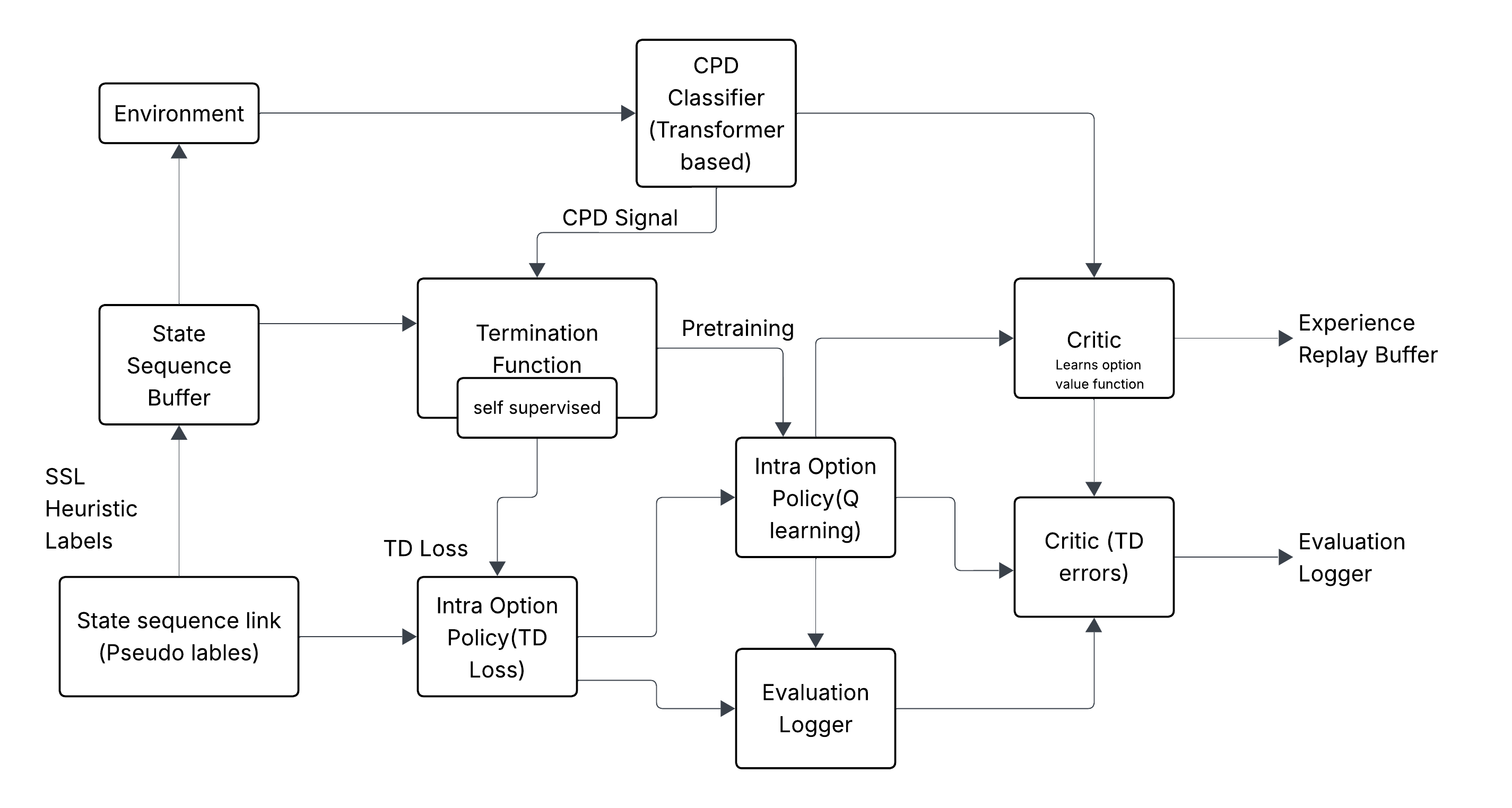
技术框架:整体框架包括三个主要模块:1) 基于Transformer的变点检测(CPD)模块,用于自监督地分割状态轨迹;2) Option-Critic框架,用于学习选项策略和终止函数;3) 结构感知的辅助损失,用于增强标准actor-critic损失。CPD模块首先使用内在奖励信号生成的伪标签进行训练,然后将检测到的变点用于指导选项策略的预训练和终止函数的学习。
关键创新:该论文的关键创新在于将变点检测技术引入到分层强化学习中,并提出了一种自监督的训练方法,无需人工标注的子目标。通过利用Transformer强大的序列建模能力,CPD模块能够有效地检测环境动态的变化,从而发现有意义的子目标。此外,该论文还提出了一种结构感知的辅助损失,用于增强选项之间的差异性,从而提高选项的专业化程度。
关键设计:CPD模块采用Transformer编码器结构,输入为状态序列,输出为每个状态对应的变点概率。使用内在奖励信号(如状态访问频率)生成伪标签,用于训练CPD模块。选项策略采用神经网络表示,使用actor-critic算法进行训练。终止函数也采用神经网络表示,其梯度通过CPD检测到的变点进行稳定。选项间散度惩罚采用KL散度,用于鼓励选项之间的差异性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CPD引导的HRL智能体在Four-Rooms和Pinball任务中均表现出显著的性能提升。与基线方法相比,CPD引导的智能体收敛速度更快,累积回报更高,并且选项之间的专业化程度也更高。例如,在Four-Rooms任务中,CPD引导的智能体能够更快地学会到达各个房间的策略,从而更快地完成整个任务。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、任务规划等领域。通过自动发现子目标和学习分层策略,智能体可以更有效地解决复杂任务,提高决策效率和泛化能力。例如,在机器人导航中,智能体可以自动学习如何避开障碍物、到达目标地点等子任务,从而实现更智能的导航。
📄 摘要(原文)
Hierarchical Reinforcement Learning (HRL) enhances the scalability of decision-making in long-horizon tasks by introducing temporal abstraction through options-policies that span multiple timesteps. Despite its theoretical appeal, the practical implementation of HRL suffers from the challenge of autonomously discovering semantically meaningful subgoals and learning optimal option termination boundaries. This paper introduces a novel architecture that integrates a self-supervised, Transformer-based Change Point Detection (CPD) module into the Option-Critic framework, enabling adaptive segmentation of state trajectories and the discovery of options. The CPD module is trained using heuristic pseudo-labels derived from intrinsic signals to infer latent shifts in environment dynamics without external supervision. These inferred change-points are leveraged in three critical ways: (i) to serve as supervisory signals for stabilizing termination function gradients, (ii) to pretrain intra-option policies via segment-wise behavioral cloning, and (iii) to enforce functional specialization through inter-option divergence penalties over CPD-defined state partitions. The overall optimization objective enhances the standard actor-critic loss using structure-aware auxiliary losses. In our framework, option discovery arises naturally as CPD-defined trajectory segments are mapped to distinct intra-option policies, enabling the agent to autonomously partition its behavior into reusable, semantically meaningful skills. Experiments on the Four-Rooms and Pinball tasks demonstrate that CPD-guided agents exhibit accelerated convergence, higher cumulative returns, and significantly improved option specialization. These findings confirm that integrating structural priors via change-point segmentation leads to more interpretable, sample-efficient, and robust hierarchical policies in complex environments.