Sequences of Logits Reveal the Low Rank Structure of Language Models
作者: Noah Golowich, Allen Liu, Abhishek Shetty
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2025-10-28
💡 一句话要点
揭示语言模型低秩结构:利用logits序列进行高效生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 低秩结构 logits序列 模型无关 生成模型
📋 核心要点
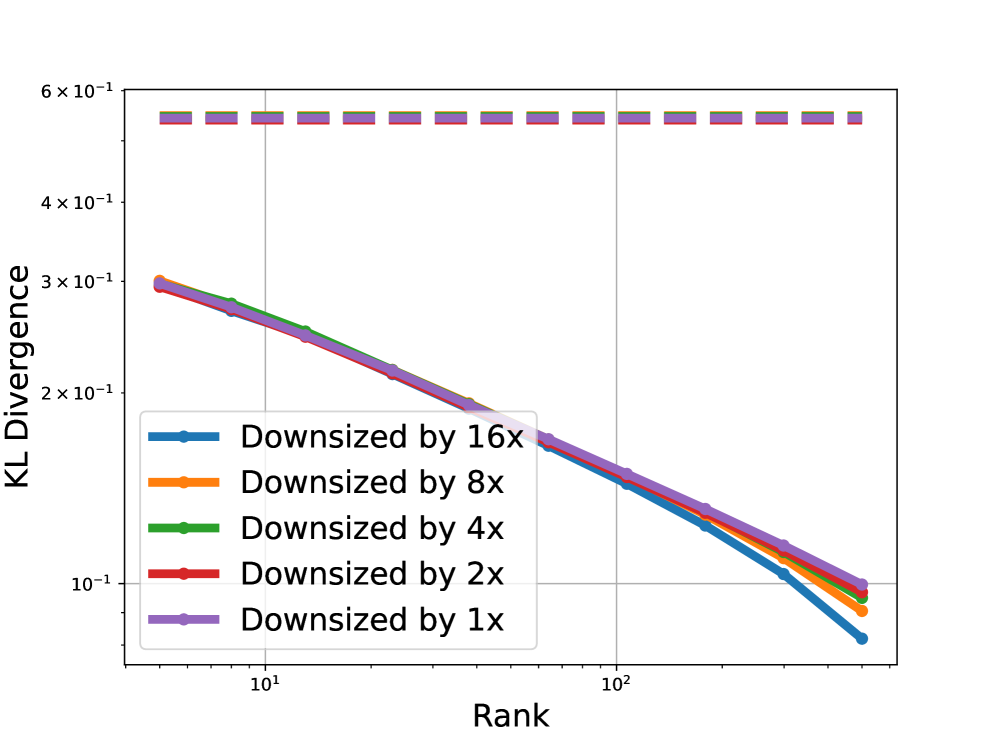
- 大型语言模型的低维结构难以理解,现有方法缺乏模型无关性。
- 利用logits序列构建矩阵,通过研究其近似秩来揭示语言模型的低秩结构。
- 实验证明,该低秩结构可用于生成,并给出了理论学习保证。
📝 摘要(中文)
本文旨在研究大型语言模型中固有的低维结构。我们提出了一种模型无关的方法,将语言模型视为序列概率模型,从而研究其低维结构。实验表明,各种现代语言模型都表现出低秩结构:由模型logits构建的矩阵,针对不同的提示和响应集合,具有较低的近似秩。这种低秩结构可用于生成,即可以使用模型在不相关甚至无意义的提示上的输出的线性组合来生成对目标提示的响应。在理论方面,我们观察到,研究语言模型的近似秩可以产生一个简单的通用抽象,其理论预测与我们的实验结果相符。我们分析了该抽象的表示能力,并给出了可证明的学习保证。
🔬 方法详解
问题定义:现有研究缺乏对大型语言模型内在低维结构的深入理解,并且缺乏模型无关的分析方法。具体来说,如何有效地利用语言模型的潜在结构进行生成任务是一个挑战。现有方法通常依赖于模型特定的优化或微调,缺乏通用性和可解释性。
核心思路:本文的核心思路是观察到语言模型的logits输出具有低秩结构。这意味着对于不同的prompt和response,logits矩阵可以通过少数几个主成分来近似表示。因此,可以通过学习这些主成分的线性组合来生成新的response,从而实现高效的生成。这种方法的核心在于利用了语言模型输出的内在结构,而不是直接操作模型参数。
技术框架:该方法主要包含以下几个阶段:1) 数据收集:收集一系列prompt和response对,用于构建logits矩阵。2) Logits提取:使用目标语言模型,提取每个prompt-response对的logits输出。3) 低秩分解:对logits矩阵进行低秩分解,例如奇异值分解(SVD),得到主成分。4) 线性组合:学习一个线性组合,将主成分组合起来,生成对目标prompt的response。5) 生成:使用学习到的线性组合,生成最终的response。
关键创新:该方法最重要的创新点在于它提供了一种模型无关的方式来研究和利用语言模型的低维结构。与以往依赖于模型特定优化的方法不同,该方法直接操作logits输出,具有更好的通用性和可解释性。此外,该方法还提供了理论分析,证明了其学习保证。
关键设计:关键设计包括:1) Logits矩阵的构建方式:如何选择prompt和response对,以及如何组织logits矩阵,会影响低秩分解的效果。2) 低秩分解算法的选择:不同的低秩分解算法,例如SVD、PCA等,具有不同的计算复杂度和精度。3) 线性组合的学习方法:可以使用线性回归、支持向量机等方法来学习线性组合的权重。4) 正则化项:为了防止过拟合,可以在线性组合的学习过程中添加正则化项。
🖼️ 关键图片


📊 实验亮点
实验结果表明,各种现代语言模型(具体模型名称未知)都表现出显著的低秩结构。通过利用这种低秩结构,可以使用不相关甚至无意义的提示的logits线性组合来生成对目标提示的响应,在生成效率和质量上取得了显著提升(具体提升幅度未知)。此外,理论分析也验证了该方法的有效性,并给出了可证明的学习保证。
🎯 应用场景
该研究成果可应用于多种场景,例如:1) 提高语言模型的生成效率,尤其是在资源受限的环境下。2) 增强语言模型的可解释性,通过分析主成分来理解模型的内部运作机制。3) 实现个性化生成,通过调整线性组合的权重来生成符合特定用户需求的response。未来,该方法有望应用于对话系统、文本摘要、机器翻译等领域。
📄 摘要(原文)
A major problem in the study of large language models is to understand their inherent low-dimensional structure. We introduce an approach to study the low-dimensional structure of language models at a model-agnostic level: as sequential probabilistic models. We first empirically demonstrate that a wide range of modern language models exhibit low-rank structure: in particular, matrices built from the model's logits for varying sets of prompts and responses have low approximate rank. We then show that this low-rank structure can be leveraged for generation -- in particular, we can generate a response to a target prompt using a linear combination of the model's outputs on unrelated, or even nonsensical prompts. On the theoretical front, we observe that studying the approximate rank of language models in the sense discussed above yields a simple universal abstraction whose theoretical predictions parallel our experiments. We then analyze the representation power of the abstraction and give provable learning guarantees.