Greedy Sampling Is Provably Efficient for RLHF
作者: Di Wu, Chengshuai Shi, Jing Yang, Cong Shen
分类: cs.LG, cs.AI, cs.IT, stat.ML
发布日期: 2025-10-28
备注: NeurIPS 2025
💡 一句话要点
针对通用偏好模型的RLHF,提出贪婪采样算法并证明其高效性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RLHF 强化学习 人类反馈 贪婪采样 通用偏好模型 Bradley-Terry模型 KL正则化 策略优化
📋 核心要点
- 现有RLHF方法在理论理解上存在局限,尤其是在通用偏好模型下,性能提升面临挑战。
- 论文提出一种基于贪婪采样的RLHF算法,直接利用经验估计,避免了构建乐观或悲观估计。
- 理论分析表明,该算法在通用偏好模型下具有优越的性能保证,并在BT模型下验证了贪婪采样的有效性。
📝 摘要(中文)
本文研究了基于人类反馈的强化学习(RLHF)这一后训练大型语言模型的关键技术。尽管RLHF在实践中取得了成功,但其理论理解仍然有限,因为仅通过偏好反馈学习KL正则化的目标相比于标准的强化学习提出了额外的挑战。现有工作主要研究基于奖励的Bradley-Terry(BT)偏好模型,并扩展了利用乐观或悲观估计的经典设计。本文则考虑了通用偏好模型(其在实践中的相关性最近已被观察到),并获得了性能保证,在数量级上优于现有方法。令人惊讶的是,这些结果来源于直接使用经验估计的算法(即贪婪采样),而不是像先前工作那样构建乐观或悲观估计。这种洞察深刻地根植于KL正则化目标下最优策略类的独特结构属性,并且我们进一步将其专门化到BT模型,突出了贪婪采样在RLHF中的惊人充分性。
🔬 方法详解
问题定义:现有RLHF方法,特别是针对通用偏好模型,在理论保证和算法效率上存在不足。以往工作主要集中在基于奖励的Bradley-Terry模型,并依赖于乐观或悲观估计来探索策略空间,这可能导致次优的性能和较高的计算复杂度。因此,如何设计一种更高效且具有理论保证的RLHF算法,尤其是在通用偏好模型下,是一个关键问题。
核心思路:本文的核心思路是利用KL正则化目标下最优策略类的结构特性,证明贪婪采样在RLHF中的有效性。贪婪采样直接使用经验估计,避免了构建复杂的乐观或悲观估计,从而降低了计算复杂度。这种方法基于一个关键的观察:在KL正则化下,最优策略具有一定的平滑性,使得贪婪采样能够有效地探索策略空间并找到接近最优的策略。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 定义通用偏好模型下的RLHF问题,包括状态空间、动作空间、奖励函数和偏好反馈;2) 提出基于贪婪采样的RLHF算法,该算法直接使用经验估计来选择策略;3) 对算法进行理论分析,证明其在通用偏好模型下具有性能保证,并给出收敛速度的界限;4) 将算法专门化到BT模型,验证贪婪采样在BT模型下的有效性。
关键创新:本文最重要的技术创新点在于证明了贪婪采样在RLHF中的有效性,这与以往依赖乐观或悲观估计的方法形成了鲜明对比。这种创新基于对KL正则化目标下最优策略类结构特性的深刻理解,并为RLHF算法的设计提供了一种新的思路。
关键设计:该研究的关键设计在于贪婪采样算法的具体实现。算法的核心是根据经验估计的偏好概率来选择策略,并使用KL散度作为正则化项来约束策略的变化。具体的参数设置包括KL散度的系数、采样次数等。此外,论文还针对BT模型对算法进行了专门化,并给出了相应的参数设置。
🖼️ 关键图片


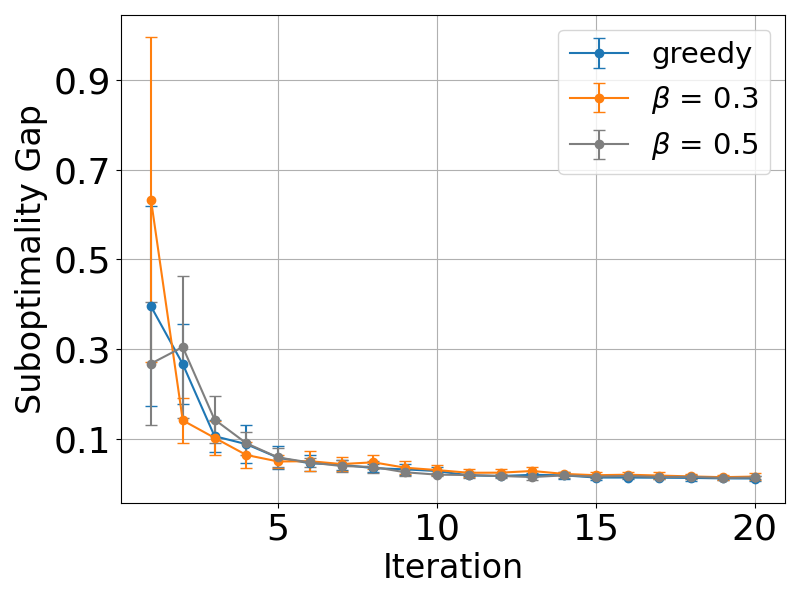
📊 实验亮点
论文的主要实验结果表明,基于贪婪采样的RLHF算法在通用偏好模型下具有优越的性能保证,并且在BT模型下验证了贪婪采样的有效性。与现有方法相比,该算法在数量级上提高了性能,并降低了计算复杂度。这些结果突出了贪婪采样在RLHF中的潜力,并为未来的研究提供了新的方向。
🎯 应用场景
该研究成果可应用于各种需要从人类反馈中学习的场景,例如对话系统、文本生成、推荐系统等。通过使用贪婪采样算法,可以更高效地训练这些系统,并提高其性能和用户满意度。此外,该研究的理论分析也为RLHF算法的设计提供了指导,有助于开发更鲁棒和高效的RLHF算法。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) has emerged as a key technique for post-training large language models. Despite its empirical success, the theoretical understanding of RLHF is still limited, as learning the KL-regularized target with only preference feedback poses additional challenges compared with canonical RL. Existing works mostly study the reward-based Bradley-Terry (BT) preference model, and extend classical designs utilizing optimism or pessimism. This work, instead, considers the general preference model (whose practical relevance has been observed recently) and obtains performance guarantees with major, order-wise improvements over existing ones. Surprisingly, these results are derived from algorithms that directly use the empirical estimates (i.e., greedy sampling), as opposed to constructing optimistic or pessimistic estimates in previous works. This insight has a deep root in the unique structural property of the optimal policy class under the KL-regularized target, and we further specialize it to the BT model, highlighting the surprising sufficiency of greedy sampling in RLHF.