Eigenfunction Extraction for Ordered Representation Learning
作者: Burak Varıcı, Che-Ping Tsai, Ritabrata Ray, Nicholas M. Boffi, Pradeep Ravikumar
分类: cs.LG, stat.ML
发布日期: 2025-10-28
💡 一句话要点
提出特征函数提取框架,用于有序表征学习,提升特征选择的效率和准确性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 表征学习 特征函数提取 谱分解 上下文核 特征选择
📋 核心要点
- 现有对比和非对比学习方法仅能恢复上下文核的部分特征函数,无法完整理解特征的排序和重要性。
- 论文提出通用框架,通过模块化构建块提取有序且可识别的特征函数,兼容上下文核并具备可扩展性。
- 实验表明,恢复的特征值可作为特征选择的有效重要性评分,实现效率与准确性的平衡。
📝 摘要(中文)
近期的表征学习进展表明,对比学习和非对比学习等常用目标函数隐式地执行了上下文核的谱分解,该核由输入及其上下文之间的关系诱导产生。然而,这些方法仅恢复了核的前几个特征函数的线性跨度,而精确的谱分解对于理解特征排序和重要性至关重要。本文提出了一个通用框架,用于提取有序且可识别的特征函数,该框架基于模块化构建块,旨在满足关键需求,包括与上下文核的兼容性以及对现代设置的可扩展性。然后,我们展示了低秩近似和瑞利商优化这两种主要的方法范式如何与该特征函数提取框架对齐。最后,我们在合成核上验证了我们的方法,并在真实世界的图像数据集上证明,恢复的特征值可以作为特征选择的有效重要性评分,从而通过自适应维度表征实现有原则的效率-准确性权衡。
🔬 方法详解
问题定义:现有对比学习和非对比学习方法在表征学习中取得了显著进展,但它们通常只能恢复上下文核(由输入及其上下文关系定义)的顶部几个特征向量的线性组合。这导致无法精确地进行谱分解,从而难以理解特征的完整排序和重要性,限制了特征选择和降维等下游任务的性能。因此,需要一种能够提取有序且可识别的特征函数的方法,以更全面地理解数据的内在结构。
核心思路:论文的核心思路是设计一个通用的特征函数提取框架,该框架能够执行上下文核的精确谱分解,从而获得有序且可识别的特征函数。通过提取这些特征函数,可以更好地理解特征的排序和重要性,并将其用于特征选择、降维等任务。该框架的设计目标是与现有的上下文核兼容,并能够扩展到现代大规模数据集。
技术框架:该框架基于模块化构建块,主要包含以下几个阶段:1) 上下文核构建:利用输入及其上下文信息构建上下文核。2) 特征函数提取:使用低秩近似或瑞利商优化等方法,从上下文核中提取有序的特征函数。3) 特征值评估:评估每个特征函数对应的特征值,作为特征重要性的度量。4) 特征选择/降维:根据特征值选择重要的特征,或进行降维操作。
关键创新:该论文的关键创新在于提出了一个通用的特征函数提取框架,该框架能够提取有序且可识别的特征函数,从而更全面地理解数据的内在结构。与现有方法相比,该框架不仅能够恢复顶部几个特征向量的线性组合,还能够提取完整的特征函数谱,从而更好地进行特征选择和降维。此外,该框架的设计具有模块化和可扩展性,可以方便地应用于不同的上下文核和大规模数据集。
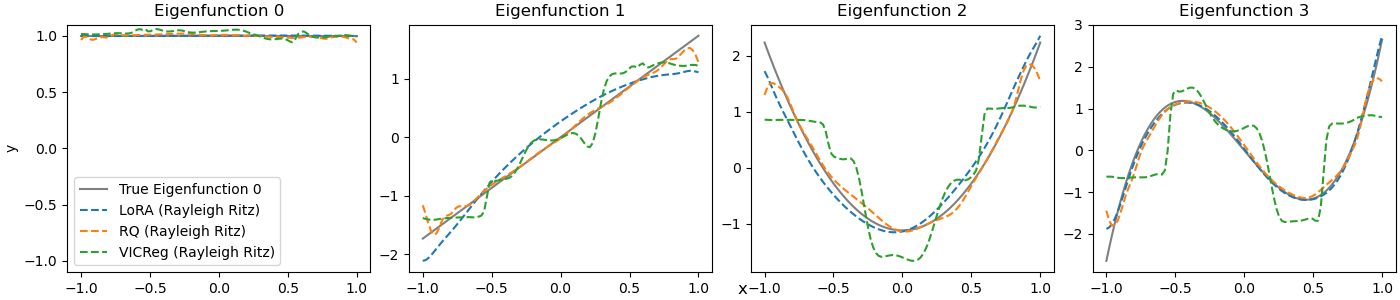
关键设计:论文中,低秩近似方法通过对上下文核进行低秩分解来提取特征函数。瑞利商优化方法则通过迭代优化瑞利商来提取特征函数。具体而言,瑞利商被定义为特征函数与上下文核的乘积的积分与特征函数平方的积分之比。通过最大化瑞利商,可以找到与上下文核相关的最重要的特征函数。此外,论文还考虑了如何选择合适的低秩近似的秩,以及如何有效地优化瑞利商。
🖼️ 关键图片
📊 实验亮点
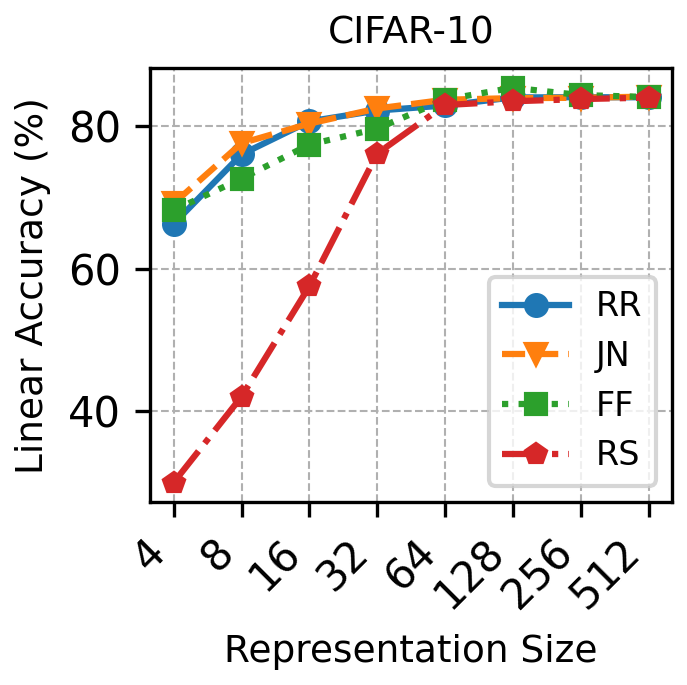
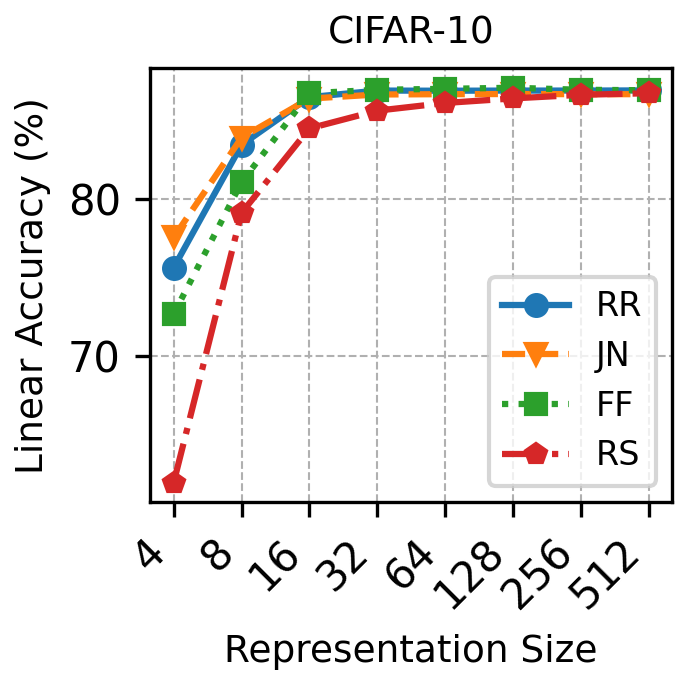
实验结果表明,该方法在合成核和真实图像数据集上均表现良好。在图像数据集上,恢复的特征值可以作为特征选择的有效重要性评分,通过自适应维度表征,实现了效率和准确性的有效权衡。具体而言,使用该方法选择的特征在图像分类任务中取得了与使用全部特征相近的性能,但计算量显著降低。
🎯 应用场景
该研究成果可应用于图像识别、自然语言处理等领域,通过提取有序特征函数,实现更有效的特征选择和降维,提升模型性能和效率。例如,在图像识别中,可以根据特征值选择重要的图像特征,从而减少计算量并提高识别准确率。该方法还可用于推荐系统,通过分析用户行为数据提取用户偏好特征。
📄 摘要(原文)
Recent advances in representation learning reveal that widely used objectives, such as contrastive and non-contrastive, implicitly perform spectral decomposition of a contextual kernel, induced by the relationship between inputs and their contexts. Yet, these methods recover only the linear span of top eigenfunctions of the kernel, whereas exact spectral decomposition is essential for understanding feature ordering and importance. In this work, we propose a general framework to extract ordered and identifiable eigenfunctions, based on modular building blocks designed to satisfy key desiderata, including compatibility with the contextual kernel and scalability to modern settings. We then show how two main methodological paradigms, low-rank approximation and Rayleigh quotient optimization, align with this framework for eigenfunction extraction. Finally, we validate our approach on synthetic kernels and demonstrate on real-world image datasets that the recovered eigenvalues act as effective importance scores for feature selection, enabling principled efficiency-accuracy tradeoffs via adaptive-dimensional representations.