Sample-efficient and Scalable Exploration in Continuous-Time RL
作者: Klemens Iten, Lenart Treven, Bhavya Sukhija, Florian Dörfler, Andreas Krause
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-10-28
备注: 26 pages, 6 figures, 6 tables
💡 一句话要点
提出COMBRL算法,解决连续时间强化学习中的样本效率和可扩展性问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 连续时间强化学习 模型强化学习 高斯过程 贝叶斯神经网络 不确定性量化
📋 核心要点
- 传统强化学习算法主要针对离散时间动态系统设计,难以直接应用于实际的连续时间控制系统。
- COMBRL算法利用概率模型学习连续时间动态系统的不确定性,并通过最大化奖励和不确定性的加权和进行探索。
- 实验结果表明,COMBRL算法在样本效率和可扩展性方面优于现有方法,并在多个深度强化学习任务中取得了更好的性能。
📝 摘要(中文)
本文研究了连续时间强化学习问题,其中未知的系统动力学用非线性常微分方程(ODE)表示。利用高斯过程和贝叶斯神经网络等概率模型,学习底层ODE的不确定性感知模型。论文提出的COMBRL算法,贪婪地最大化外在奖励和模型认知不确定性的加权和。这产生了一种可扩展且样本高效的连续时间模型强化学习方法。论文证明了COMBRL在奖励驱动设置中实现了次线性遗憾,并且在无监督强化学习设置(即,没有外在奖励)中,提供了样本复杂度界限。实验表明,COMBRL在标准和无监督强化学习设置中都表现良好,比以前的方法具有更好的可扩展性和样本效率,并且在多个深度强化学习任务中优于基线。
🔬 方法详解
问题定义:论文旨在解决连续时间强化学习中样本效率低和可扩展性差的问题。现有方法通常基于离散时间假设,或者在连续时间领域需要大量的样本才能学习到精确的模型,限制了其在实际复杂系统中的应用。
核心思路:COMBRL的核心思路是利用概率模型(如高斯过程或贝叶斯神经网络)来学习连续时间动态系统的不确定性感知模型。通过同时考虑外在奖励和模型认知不确定性,算法能够更有效地探索环境,并在样本有限的情况下快速学习到最优策略。这种方法鼓励算法探索模型不确定性高的区域,从而提高学习效率。
技术框架:COMBRL算法的整体框架包括以下几个主要步骤:1) 使用概率模型学习连续时间动态系统模型;2) 基于当前模型,计算每个状态-动作对的奖励和模型不确定性;3) 通过最大化奖励和不确定性的加权和,选择下一个动作;4) 执行选定的动作,并收集新的样本;5) 使用新的样本更新概率模型。这个过程迭代进行,直到学习到最优策略。
关键创新:COMBRL的关键创新在于将模型认知不确定性纳入到探索策略中。通过显式地考虑模型的不确定性,算法能够更有效地探索环境,避免陷入局部最优解。此外,使用概率模型能够更好地处理连续时间动态系统的复杂性,并提供对模型预测的置信度估计。
关键设计:COMBRL算法的关键设计包括:1) 使用高斯过程或贝叶斯神经网络作为概率模型,学习连续时间动态系统模型;2) 定义一个奖励函数,用于衡量每个状态-动作对的价值;3) 定义一个不确定性度量,用于衡量模型对每个状态-动作对预测的不确定性;4) 使用一个加权系数,用于平衡奖励和不确定性之间的权重。具体的损失函数取决于所使用的概率模型和不确定性度量。
🖼️ 关键图片
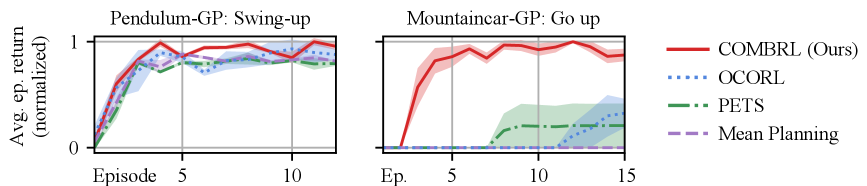
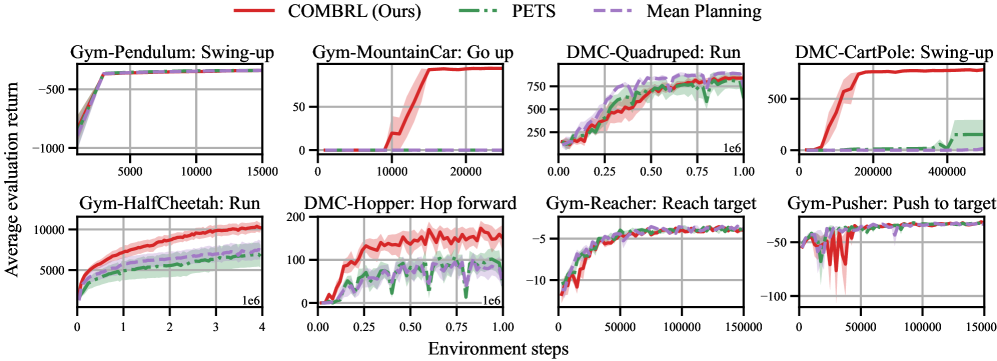
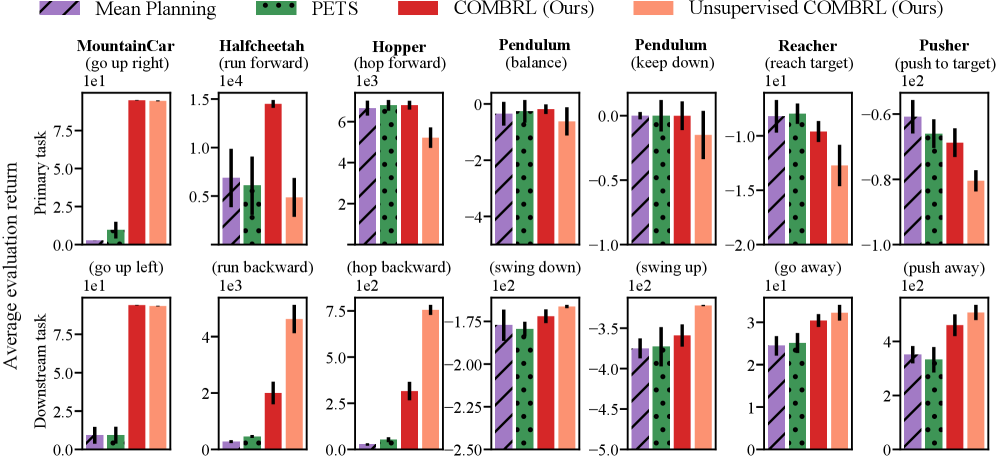
📊 实验亮点
实验结果表明,COMBRL算法在多个连续时间强化学习任务中优于现有方法。例如,在CartPole和Pendulum等标准控制任务中,COMBRL算法能够更快地学习到最优策略,并且需要的样本数量更少。此外,COMBRL算法在无监督强化学习任务中也表现出色,能够有效地探索环境并学习到有用的表示。
🎯 应用场景
COMBRL算法具有广泛的应用前景,例如机器人控制、自动驾驶、金融交易等领域。在这些领域中,系统通常是连续时间的,并且难以获得大量的训练数据。COMBRL算法的样本效率和可扩展性使其成为解决这些问题的有力工具。未来,该算法可以进一步扩展到更复杂的连续时间系统,并与其他强化学习技术相结合,以实现更强大的控制能力。
📄 摘要(原文)
Reinforcement learning algorithms are typically designed for discrete-time dynamics, even though the underlying real-world control systems are often continuous in time. In this paper, we study the problem of continuous-time reinforcement learning, where the unknown system dynamics are represented using nonlinear ordinary differential equations (ODEs). We leverage probabilistic models, such as Gaussian processes and Bayesian neural networks, to learn an uncertainty-aware model of the underlying ODE. Our algorithm, COMBRL, greedily maximizes a weighted sum of the extrinsic reward and model epistemic uncertainty. This yields a scalable and sample-efficient approach to continuous-time model-based RL. We show that COMBRL achieves sublinear regret in the reward-driven setting, and in the unsupervised RL setting (i.e., without extrinsic rewards), we provide a sample complexity bound. In our experiments, we evaluate COMBRL in both standard and unsupervised RL settings and demonstrate that it scales better, is more sample-efficient than prior methods, and outperforms baselines across several deep RL tasks.