What do vision-language models see in the context? Investigating multimodal in-context learning
作者: Gabriel O. dos Santos, Esther Colombini, Sandra Avila
分类: cs.LG, cs.CV
发布日期: 2025-10-28
💡 一句话要点
系统性研究视觉-语言模型中的上下文学习能力,揭示其多模态融合的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 上下文学习 多模态融合 注意力机制 图像字幕
📋 核心要点
- 现有视觉-语言模型(VLMs)的上下文学习(ICL)能力研究不足,尤其是在多模态信息融合方面。
- 通过系统性实验,分析提示设计、架构选择和训练策略对VLMs中ICL的影响,关注注意力模式的变化。
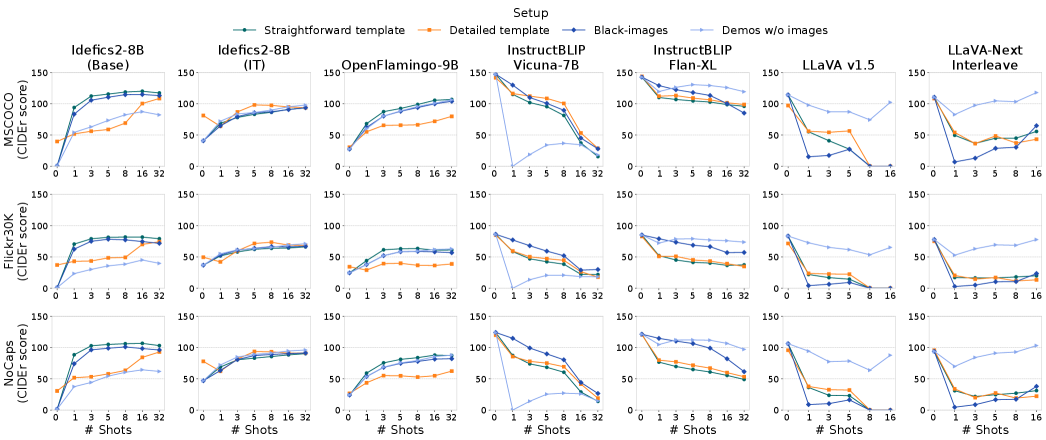
- 实验结果表明,VLMs在多模态信息融合方面存在局限性,主要依赖文本线索,未能充分利用视觉信息。
📝 摘要(中文)
上下文学习(ICL)使大型语言模型(LLMs)能够从演示示例中学习任务,而无需更新参数。虽然它已经在LLMs中得到了广泛的研究,但它在视觉-语言模型(VLMs)中的有效性仍未得到充分探索。本文对VLMs中的ICL进行了系统研究,在三个图像字幕基准上评估了跨越四种架构的七个模型。我们分析了提示设计、架构选择和训练策略如何影响多模态ICL。据我们所知,我们是第一个分析VLMs中注意力模式如何随着上下文中演示数量的增加而变化的研究。我们的结果表明,在图像-文本交错数据上进行训练可以提高ICL性能,但并不意味着有效地整合来自演示示例的视觉和文本信息。相比之下,指令调优可以提高指令遵循能力,但会降低对上下文中演示的依赖,这表明指令对齐和上下文适应之间存在权衡。注意力分析进一步表明,当前的VLMs主要关注文本线索,而未能利用视觉信息,这表明多模态整合能力有限。这些发现突出了当前VLMs在ICL能力方面的关键局限性,并为提高它们从多模态上下文示例中学习的能力提供了见解。
🔬 方法详解
问题定义:论文旨在研究视觉-语言模型(VLMs)在上下文学习(ICL)中的表现,特别是它们如何利用视觉和文本信息进行多模态融合。现有方法在LLMs中对ICL进行了广泛研究,但在VLMs中,尤其是多模态ICL方面,研究较少。现有VLMs可能无法有效整合上下文中的视觉信息,导致性能瓶颈。
核心思路:论文的核心思路是通过系统性的实验分析,评估不同架构和训练策略的VLMs在ICL中的表现,并深入研究其注意力机制,从而揭示VLMs在多模态信息融合方面的局限性。通过分析注意力模式,可以了解VLMs如何利用上下文中的视觉和文本信息,并找出改进的方向。
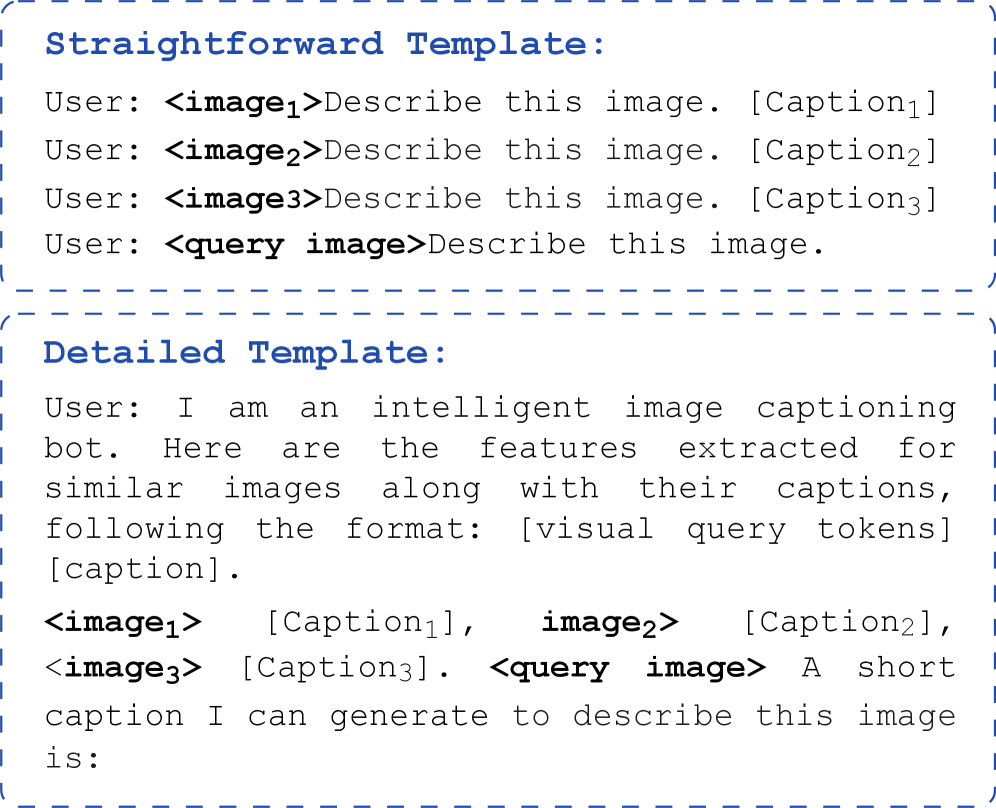
技术框架:论文的整体框架包括以下几个主要步骤:1) 选择多个具有代表性的VLMs,涵盖不同的架构和训练策略。2) 在多个图像字幕基准数据集上进行ICL实验,评估模型的性能。3) 设计不同的提示方式,分析提示设计对ICL性能的影响。4) 分析VLMs的注意力模式,观察模型如何利用上下文中的视觉和文本信息。5) 对实验结果进行深入分析,总结VLMs在多模态ICL方面的优势和不足。
关键创新:论文的关键创新在于首次系统性地研究了VLMs中的ICL,并深入分析了其注意力模式。通过实验,揭示了现有VLMs在多模态信息融合方面的局限性,并提出了改进的方向。此外,论文还分析了训练策略(如图像-文本交错训练和指令调优)对ICL性能的影响,为未来的研究提供了有价值的参考。
关键设计:论文的关键设计包括:1) 选择了多个具有代表性的VLMs,包括不同架构(如Transformer、CNN)和训练策略(如图像-文本交错训练、指令调优)的模型。2) 使用了多个图像字幕基准数据集,以保证实验结果的泛化性。3) 设计了不同的提示方式,包括不同数量的上下文示例和不同的提示文本,以评估提示设计对ICL性能的影响。4) 通过注意力可视化技术,深入分析了VLMs的注意力模式,观察模型如何利用上下文中的视觉和文本信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,图像-文本交错训练可以提高ICL性能,但并不意味着有效地整合了视觉和文本信息。指令调优可以提高指令遵循能力,但会降低对上下文演示的依赖。注意力分析表明,VLMs主要关注文本线索,未能充分利用视觉信息。这些发现揭示了当前VLMs在多模态ICL方面的局限性。
🎯 应用场景
该研究成果可应用于提升视觉-语言模型在图像理解、视频分析、机器人导航等领域的性能。通过改进多模态上下文学习能力,可以使模型更好地理解复杂场景,并做出更准确的决策。例如,在机器人导航中,机器人可以根据上下文中的视觉和语言信息,更好地理解人类指令,并完成相应的任务。
📄 摘要(原文)
In-context learning (ICL) enables Large Language Models (LLMs) to learn tasks from demonstration examples without parameter updates. Although it has been extensively studied in LLMs, its effectiveness in Vision-Language Models (VLMs) remains underexplored. In this work, we present a systematic study of ICL in VLMs, evaluating seven models spanning four architectures on three image captioning benchmarks. We analyze how prompt design, architectural choices, and training strategies influence multimodal ICL. To our knowledge, we are the first to analyze how attention patterns in VLMs vary with an increasing number of in-context demonstrations. Our results reveal that training on imag-text interleaved data enhances ICL performance but does not imply effective integration of visual and textual information from demonstration examples. In contrast, instruction tuning improves instruction-following but can reduce reliance on in-context demonstrations, suggesting a trade-off between instruction alignment and in-context adaptation. Attention analyses further show that current VLMs primarily focus on textual cues and fail to leverage visual information, suggesting a limited capacity for multimodal integration. These findings highlight key limitations in the ICL abilities of current VLMs and provide insights for enhancing their ability to learn from multimodal in-context examples.