PaTaRM: Bridging Pairwise and Pointwise Signals via Preference-Aware Task-Adaptive Reward Modeling
作者: Ai Jian, Jingqing Ruan, Xing Ma, Dailin Li, Weipeng Zhang, Ke Zeng, Xunliang Cai
分类: cs.LG, cs.AI
发布日期: 2025-10-28 (更新: 2026-01-22)
🔗 代码/项目: GITHUB
💡 一句话要点
PaTaRM:通过偏好感知任务自适应奖励建模桥接成对和点式信号,提升RLHF性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 人类反馈强化学习 偏好学习 生成式奖励模型 任务自适应 点式学习 成对学习 大型语言模型
📋 核心要点
- 现有奖励模型在RLHF中存在训练-推理不匹配(成对方法)或标注成本高昂(点式方法)的问题。
- PaTaRM通过偏好感知奖励机制,利用成对数据进行点式训练,无需显式评分标签,降低标注成本。
- 实验表明,PaTaRM在多个基准测试中显著提升了奖励模型的性能,并有效改善了下游RLHF任务。
📝 摘要(中文)
奖励模型(RMs)是人类反馈强化学习(RLHF)的核心,它提供了关键的监督信号,使大型语言模型(LLMs)与人类偏好对齐。生成式奖励模型(GRMs)比传统的标量RM具有更好的可解释性,但同时也面临着一个关键的权衡:成对方法受到训练-推理不匹配的阻碍,而点式方法需要昂贵的绝对标注。为了弥合这一差距,我们提出了偏好感知任务自适应奖励模型(PaTaRM)。与先前的方法不同,PaTaRM通过一种新颖的偏好感知奖励(PAR)机制,使用现成的成对数据实现稳健的点式训练,从而消除了对显式评分标签的需求。此外,它还包含一个任务自适应规则系统,该系统动态生成特定于实例的标准以进行精确评估。大量实验表明,在Qwen3-8B/14B模型上,PATRM在RewardBench和RMBench上实现了平均8.7%的改进。至关重要的是,它在IFEval和InFoBench上将下游RLHF性能平均相对提高了13.6%,验证了其对策略对齐的有效性。我们的代码可在https://github.com/JaneEyre0530/PaTaRM 获得。
🔬 方法详解
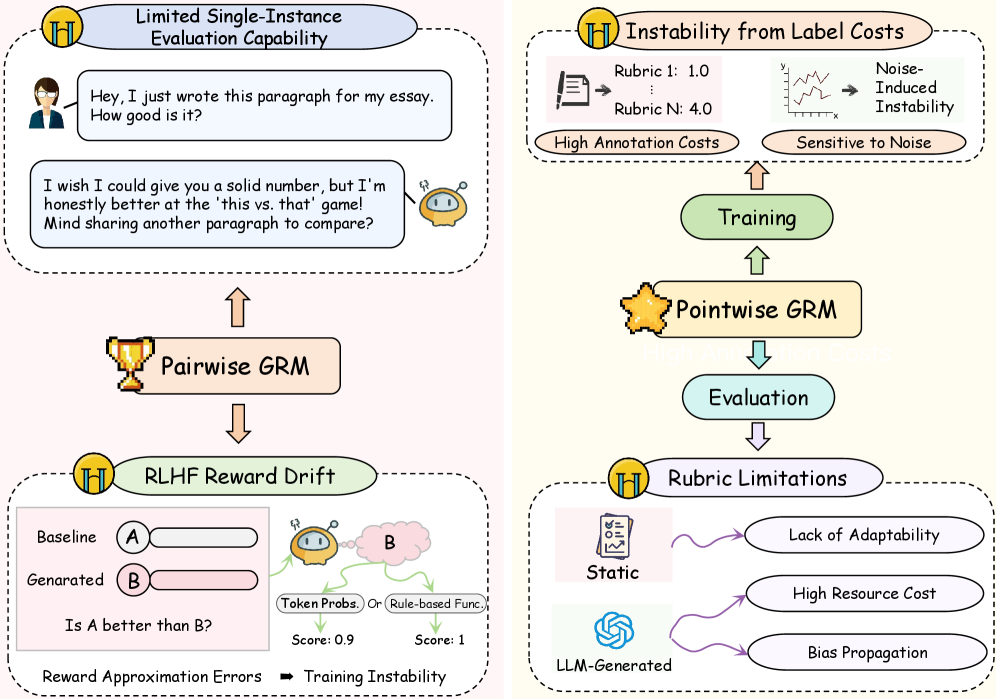
问题定义:论文旨在解决奖励模型训练中成对方法与点式方法之间的矛盾。成对方法虽然易于获取数据,但训练和推理方式不一致;点式方法需要绝对评分,标注成本高昂。现有方法难以兼顾数据效率和模型准确性。
核心思路:PaTaRM的核心思路是利用现有的成对偏好数据,通过一种偏好感知奖励(PAR)机制,模拟点式奖励的训练过程。通过学习成对数据中的偏好关系,推断出每个样本的绝对奖励值,从而实现高效的点式训练。
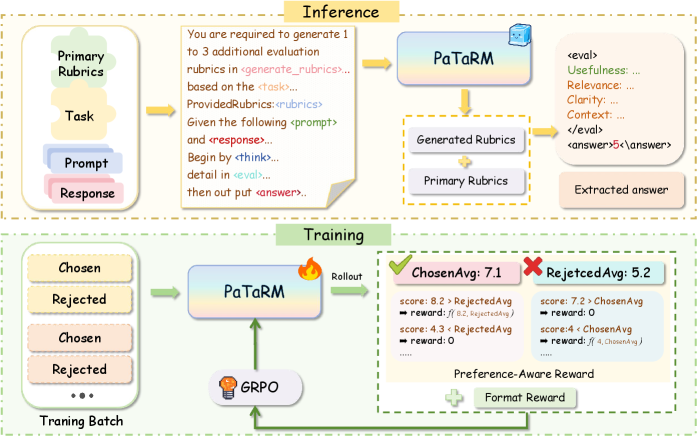
技术框架:PaTaRM包含两个主要模块:偏好感知奖励(PAR)机制和任务自适应规则系统。PAR机制负责将成对偏好数据转换为点式奖励信号,任务自适应规则系统则根据具体任务动态生成评估标准,以提高奖励模型的准确性。整体流程是:输入成对数据,PAR机制生成点式奖励,任务自适应规则系统生成评估标准,两者共同训练奖励模型。
关键创新:PaTaRM的关键创新在于偏好感知奖励(PAR)机制,它能够从成对数据中学习到隐含的点式奖励分布,从而避免了对昂贵的绝对评分标注的依赖。此外,任务自适应规则系统能够根据不同的任务动态调整评估标准,进一步提升了奖励模型的泛化能力。
关键设计:PAR机制通过一个神经网络学习成对数据中的偏好关系,并将其转化为点式奖励。损失函数的设计考虑了偏好关系的一致性,即如果A优于B,则A的奖励值应该高于B的奖励值。任务自适应规则系统则利用大型语言模型生成特定于实例的评估标准,并将其作为奖励模型的输入。
🖼️ 关键图片
📊 实验亮点
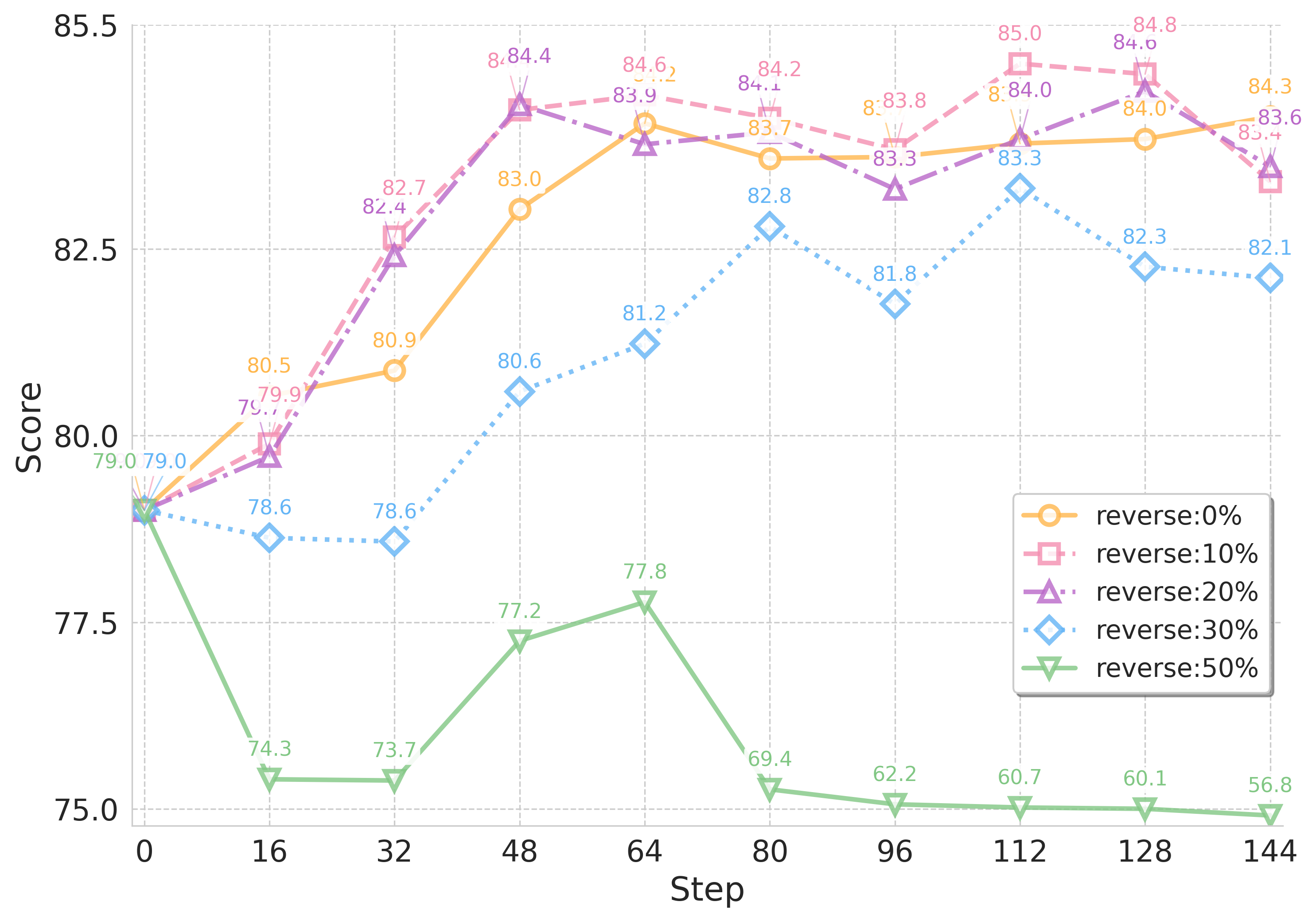
PaTaRM在RewardBench和RMBench上相比现有方法平均提升了8.7%。更重要的是,在下游RLHF任务中,PaTaRM在IFEval和InFoBench上实现了平均13.6%的相对改进,表明其能够有效提升策略对齐的效果。这些结果验证了PaTaRM在奖励模型训练方面的优越性。
🎯 应用场景
PaTaRM可应用于各种需要人类反馈的强化学习任务,例如对话系统、文本生成、代码生成等。通过降低奖励模型的标注成本,可以更高效地训练出与人类偏好对齐的智能体,从而提升用户体验和系统性能。该方法还可以应用于其他需要从相对比较中学习绝对价值的场景。
📄 摘要(原文)
Reward models (RMs) are central to reinforcement learning from human feedback (RLHF), providing the critical supervision signals that align large language models (LLMs) with human preferences. Generative reward models (GRMs) provide greater interpretability than traditional scalar RMs, but they come with a critical trade-off: pairwise methods are hindered by a training-inference mismatch, while pointwise methods require expensive absolute annotations. To bridge this gap, we propose the Preference-aware Task-adaptive Reward Model (PaTaRM). Unlike prior approaches, PaTaRM enables robust pointwise training using readily available pairwise data via a novel Preference-Aware Reward (PAR) mechanism, eliminating the need for explicit rating labels. Furthermore, it incorporates a Task-Adaptive Rubric system that dynamically generates instance-specific criteria for precise evaluation. Extensive experiments demonstrate that PATRM achieves a 8.7% average improvement on RewardBench and RMBench across Qwen3-8B/14B models. Crucially, it boosts downstream RLHF performance by an average relative improvement of 13.6% across IFEval and InFoBench, validating its effectiveness for policy alignment. Our code is available at https://github.com/JaneEyre0530/PaTaRM.