On the Fundamental Limitations of Decentralized Learnable Reward Shaping in Cooperative Multi-Agent Reinforcement Learning
作者: Aditya Akella
分类: cs.MA, cs.LG
发布日期: 2025-10-27
备注: 8 pages, 5 figures, 2 tables
💡 一句话要点
DMARL-RSA揭示了去中心化可学习奖励塑造在合作多智能体强化学习中的局限性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 去中心化学习 奖励塑造 合作博弈 非平稳性
📋 核心要点
- 现有去中心化多智能体强化学习方法在奖励塑造方面面临挑战,难以有效协调智能体行为。
- 论文提出DMARL-RSA,一种完全去中心化的奖励塑造系统,每个智能体独立学习奖励函数。
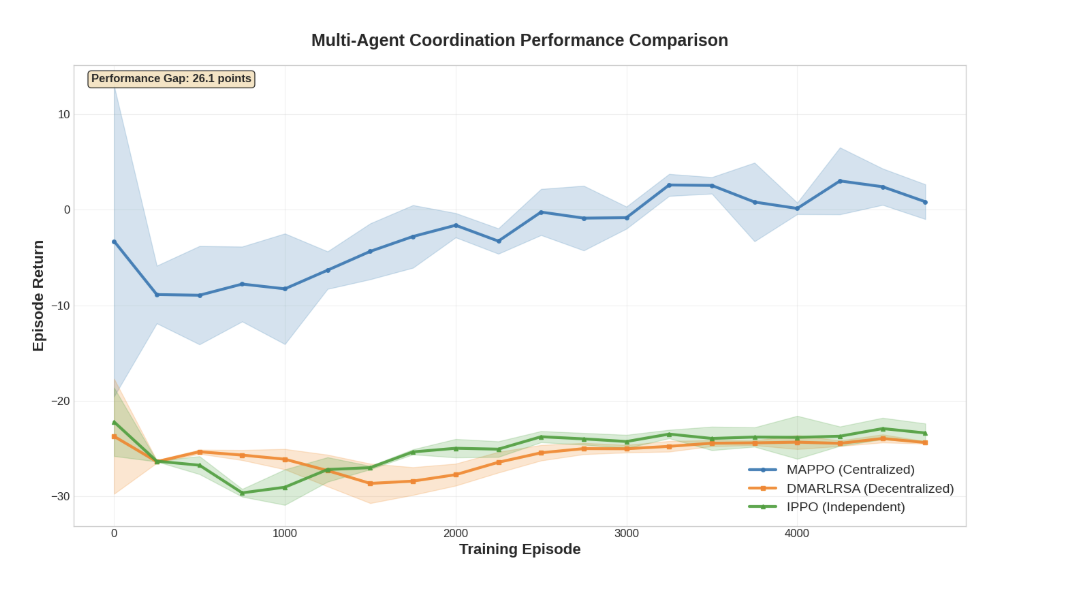
- 实验表明,DMARL-RSA性能远低于集中式MAPPO,揭示了去中心化奖励学习的根本局限性。
📝 摘要(中文)
近来,可学习奖励塑造在单智能体强化学习中展现出潜力,能够自动发现有效的反馈信号。然而,去中心化可学习奖励塑造在合作多智能体环境中的有效性仍然知之甚少。本文提出了DMARL-RSA,一个完全去中心化的系统,其中每个智能体学习独立的奖励塑造。我们在simple_spread_v3环境中的合作导航任务上评估了该系统。尽管使用了复杂的奖励学习,DMARL-RSA仅实现了-24.20 +/- 0.09的平均奖励,而集中式训练的MAPPO达到了1.92 +/- 0.87,差距为26.12。DMARL-RSA的性能与简单的独立学习(IPPO:-23.19 +/- 0.96)相似,表明高级奖励塑造无法克服根本的去中心化协调限制。有趣的是,去中心化方法实现了更高的地标覆盖率(DMARL-RSA为0.888 +/- 0.029,IPPO为0.960 +/- 0.045,总共3个),但总体性能比集中式MAPPO(0.273 +/- 0.008地标覆盖率)差,揭示了局部优化和全局性能之间的协调悖论。分析确定了三个关键障碍:(1)并发策略更新带来的非平稳性,(2)指数级的信用分配复杂性,以及(3)个体奖励优化与全局目标之间的不一致。这些结果确立了去中心化奖励学习的经验限制,并强调了集中式协调对于有效多智能体合作的必要性。
🔬 方法详解
问题定义:论文旨在研究去中心化可学习奖励塑造在合作多智能体强化学习中的局限性。现有方法在去中心化环境中难以实现有效的智能体协调,导致全局性能不佳。痛点在于个体智能体的局部优化与全局合作目标之间存在冲突,以及非平稳环境带来的学习困难。
核心思路:论文的核心思路是构建一个完全去中心化的奖励塑造系统DMARL-RSA,让每个智能体独立学习自己的奖励函数,从而在没有中心协调的情况下实现合作。这种设计旨在探索去中心化奖励塑造的上限,并识别其固有的局限性。
技术框架:DMARL-RSA的整体架构是每个智能体都配备一个独立的奖励塑造模块,该模块基于智能体的局部观察学习一个额外的奖励信号。智能体使用局部观察和学习到的奖励信号进行策略学习。整个系统是完全去中心化的,智能体之间没有直接的通信或共享信息。训练过程是并发的,每个智能体独立更新其策略和奖励塑造模块。
关键创新:论文最重要的技术创新在于对去中心化可学习奖励塑造的局限性进行了实证分析。通过DMARL-RSA,论文揭示了即使使用先进的奖励学习技术,去中心化方法仍然难以克服固有的协调问题。与现有方法不同,论文侧重于揭示去中心化方法的根本限制,而不是提出新的改进算法。
关键设计:DMARL-RSA的关键设计包括:(1) 使用独立的神经网络来学习每个智能体的奖励函数;(2) 采用简单的奖励塑造形式,例如基于状态的奖励塑造;(3) 使用标准的多智能体强化学习算法(如IPPO)作为基础策略学习器;(4) 在合作导航任务(simple_spread_v3)上进行评估,该任务需要智能体之间进行协调以覆盖所有地标。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DMARL-RSA的平均奖励为-24.20 +/- 0.09,远低于集中式MAPPO的1.92 +/- 0.87,差距高达26.12。DMARL-RSA的性能与简单的独立学习(IPPO:-23.19 +/- 0.96)相似,表明高级奖励塑造无法有效提升去中心化多智能体系统的性能。虽然DMARL-RSA和IPPO在地标覆盖率上优于MAPPO,但整体性能却更差,揭示了局部优化与全局性能之间的协调悖论。
🎯 应用场景
该研究结果对于多智能体系统设计具有重要指导意义,尤其是在通信受限或隐私敏感的应用场景中。它强调了在设计去中心化多智能体系统时,需要充分考虑个体奖励与全局目标之间的对齐问题,以及非平稳环境带来的学习挑战。未来的研究可以探索更有效的去中心化协调机制,例如基于通信的协商或基于模型的规划。
📄 摘要(原文)
Recent advances in learnable reward shaping have shown promise in single-agent reinforcement learning by automatically discovering effective feedback signals. However, the effectiveness of decentralized learnable reward shaping in cooperative multi-agent settings remains poorly understood. We propose DMARL-RSA, a fully decentralized system where each agent learns individual reward shaping, and evaluate it on cooperative navigation tasks in the simple_spread_v3 environment. Despite sophisticated reward learning, DMARL-RSA achieves only -24.20 +/- 0.09 average reward, compared to MAPPO with centralized training at 1.92 +/- 0.87 -- a 26.12-point gap. DMARL-RSA performs similarly to simple independent learning (IPPO: -23.19 +/- 0.96), indicating that advanced reward shaping cannot overcome fundamental decentralized coordination limitations. Interestingly, decentralized methods achieve higher landmark coverage (0.888 +/- 0.029 for DMARL-RSA, 0.960 +/- 0.045 for IPPO out of 3 total) but worse overall performance than centralized MAPPO (0.273 +/- 0.008 landmark coverage) -- revealing a coordination paradox between local optimization and global performance. Analysis identifies three critical barriers: (1) non-stationarity from concurrent policy updates, (2) exponential credit assignment complexity, and (3) misalignment between individual reward optimization and global objectives. These results establish empirical limits for decentralized reward learning and underscore the necessity of centralized coordination for effective multi-agent cooperation.