GIFT: Group-relative Implicit Fine Tuning Integrates GRPO with DPO and UNA
作者: Zhichao Wang
分类: cs.LG, cs.CL
发布日期: 2025-10-27 (更新: 2026-01-05)
💡 一句话要点
提出GIFT框架,结合GRPO、DPO和UNA优势,高效对齐LLM。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型对齐 强化学习 隐式奖励 显式奖励 在线学习 均方误差损失
📋 核心要点
- 现有强化学习方法(如PPO)在对齐LLM时,直接最大化累积奖励,面临探索效率和超参数敏感等问题。
- GIFT框架通过最小化隐式和显式奖励模型之间的差异,将复杂的奖励最大化问题转化为简单的均方误差损失。
- 实验结果表明,GIFT在数学推理和对齐任务上表现出色,同时降低了计算成本和过拟合风险。
📝 摘要(中文)
本文提出了一种名为Group-relative Implicit Fine Tuning (GIFT) 的新型强化学习框架,用于对齐大型语言模型(LLM)。GIFT并非像PPO或GRPO那样直接最大化累积奖励,而是最小化隐式和显式奖励模型之间的差异。它结合了三个关键思想:(1) GRPO的在线多响应生成和归一化,(2) DPO的隐式奖励公式,以及(3) UNA的隐式-显式奖励对齐原则。通过联合归一化隐式和显式奖励,GIFT消除了一个原本难以处理的项,从而有效利用隐式奖励。这种归一化将复杂的奖励最大化目标转化为归一化奖励函数之间简单的均方误差(MSE)损失,将非凸优化问题转化为凸、稳定且可解析微分的公式。与DPO和UNA等离线方法不同,GIFT保持在线策略,从而保留了探索能力。与GRPO相比,它需要的超参数更少,收敛速度更快,并且泛化能力更好,同时显著减少了训练过拟合。实验表明,GIFT在数学基准测试中实现了卓越的推理和对齐性能,同时保持了计算效率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的对齐问题,即如何使LLM的行为符合人类的意图和价值观。现有方法,如PPO和GRPO,通常直接最大化累积奖励,但存在探索效率低、超参数敏感以及容易过拟合等问题。离线方法,如DPO和UNA,虽然稳定,但缺乏探索能力。
核心思路:GIFT的核心思路是最小化隐式和显式奖励模型之间的差异。隐式奖励模型基于模型的行为推断奖励,而显式奖励模型由人工标注或规则定义。通过对齐这两个奖励模型,GIFT可以有效地引导LLM学习符合人类意图的行为,同时避免直接最大化累积奖励带来的问题。
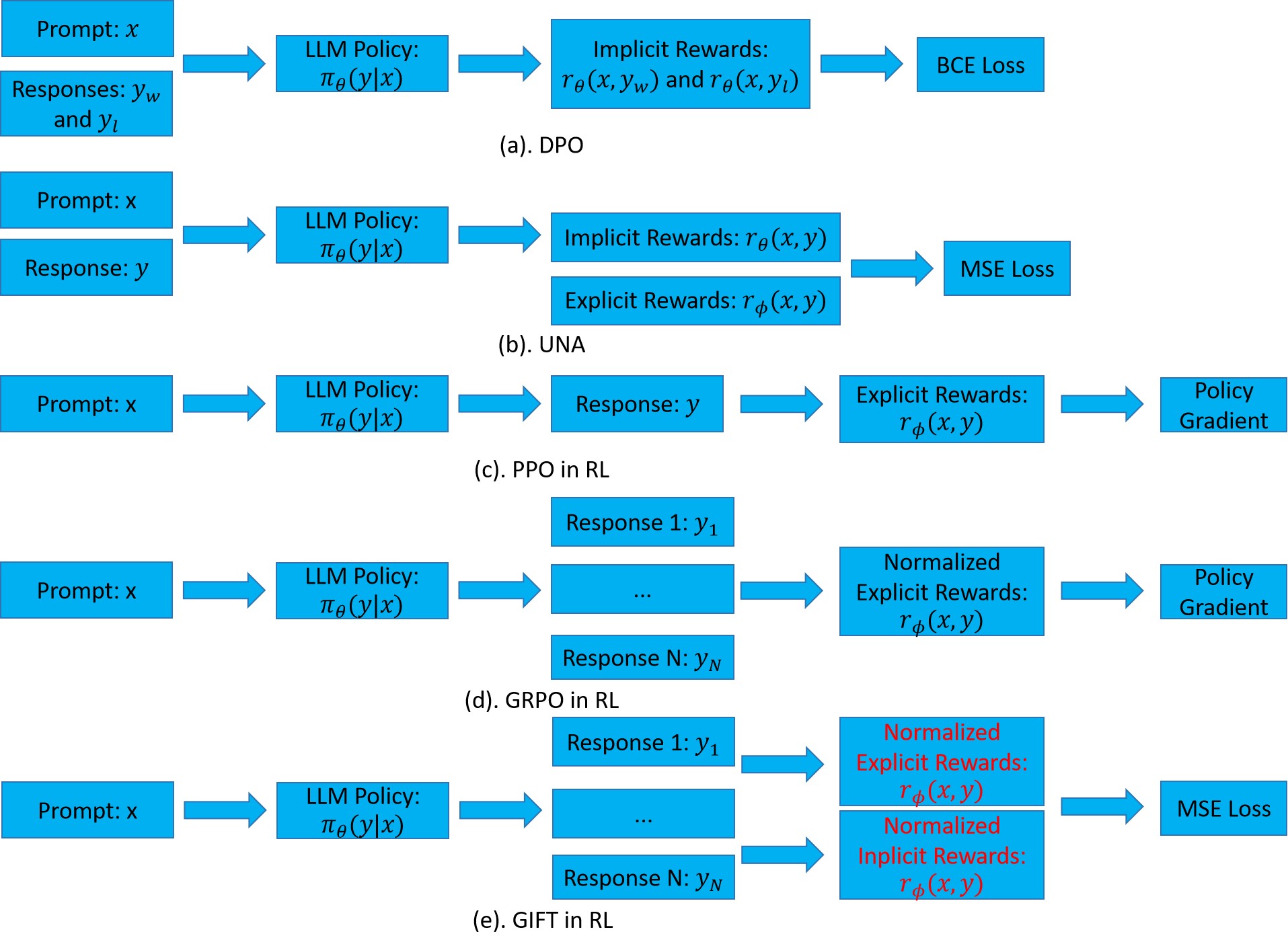
技术框架:GIFT框架主要包含以下几个模块:(1) 在线多响应生成:类似于GRPO,GIFT在线生成多个响应,以增加探索的多样性。(2) 隐式奖励计算:基于DPO的思想,GIFT利用模型的行为推断隐式奖励。(3) 显式奖励计算:GIFT使用人工标注或规则定义显式奖励。(4) 奖励归一化:GIFT联合归一化隐式和显式奖励,消除了一个难以处理的项。(5) 损失函数:GIFT使用均方误差(MSE)损失函数,最小化归一化后的隐式和显式奖励之间的差异。
关键创新:GIFT的关键创新在于将复杂的奖励最大化目标转化为简单的均方误差损失。通过联合归一化隐式和显式奖励,GIFT消除了一个原本难以处理的项,使得隐式奖励能够被有效利用。此外,GIFT保持在线策略,从而保留了探索能力,克服了离线方法的局限性。
关键设计:GIFT的关键设计包括:(1) 奖励归一化方法:具体采用何种归一化方法(例如,均值方差归一化)对性能有重要影响。(2) 隐式奖励的计算方式:如何有效地从模型的行为中推断隐式奖励是关键。(3) 损失函数的权重:如何平衡隐式和显式奖励之间的权重需要仔细调整。(4) 探索策略:如何设计有效的探索策略,以增加探索的多样性。
🖼️ 关键图片

📊 实验亮点
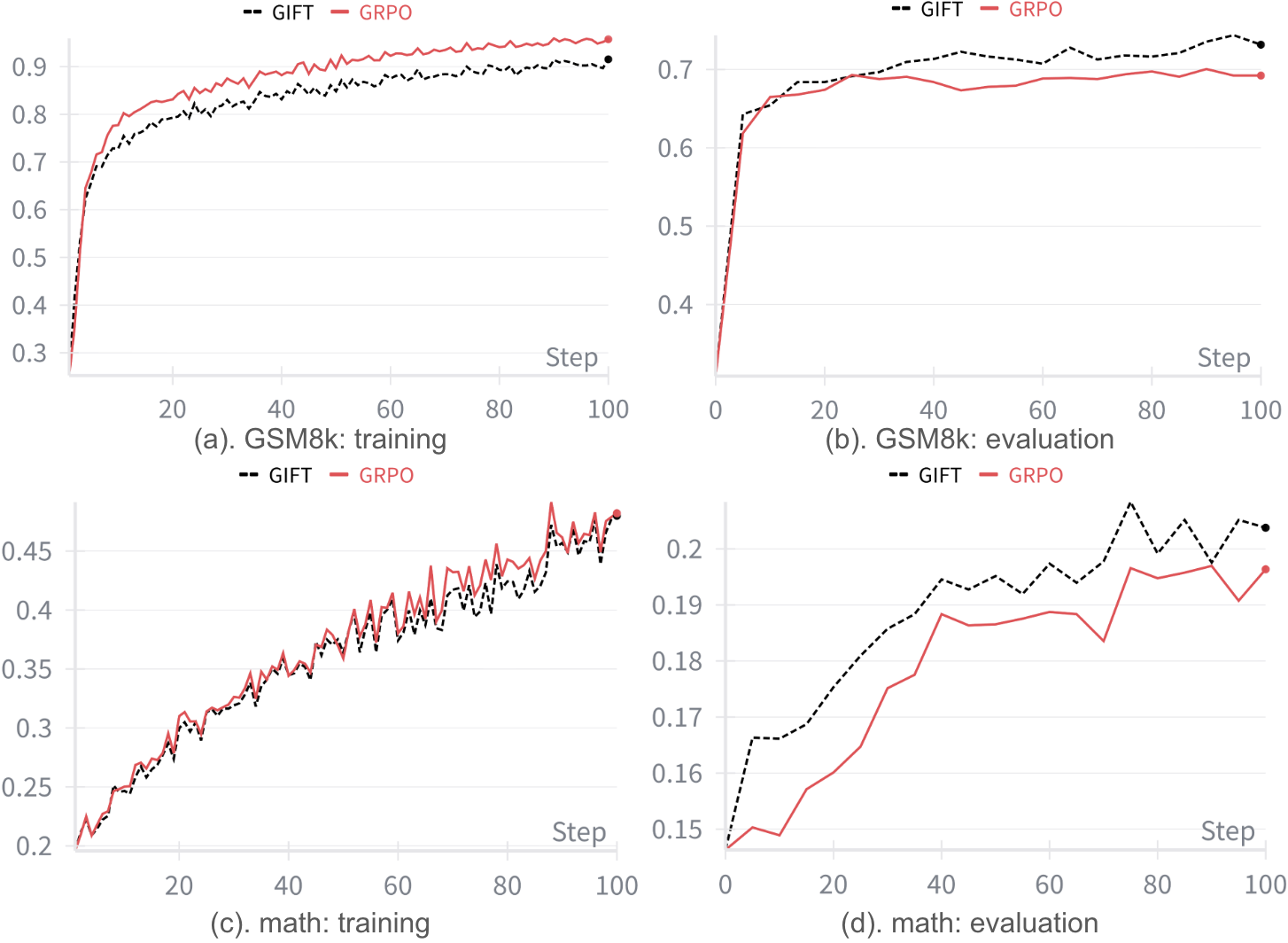
实验结果表明,GIFT在数学基准测试中实现了卓越的推理和对齐性能。与GRPO相比,GIFT需要的超参数更少,收敛速度更快,并且泛化能力更好,同时显著减少了训练过拟合。具体性能数据(例如,在特定数学基准上的准确率提升)需要在论文中查找。
🎯 应用场景
GIFT框架可应用于各种需要对齐大型语言模型的场景,例如对话系统、文本生成、代码生成等。通过使LLM更好地理解和遵循人类的意图,GIFT可以提高LLM的可用性和安全性,并促进人机协作。
📄 摘要(原文)
I propose \textbf{G}roup-relative \textbf{I}mplicit \textbf{F}ine \textbf{T}uning (GIFT), a novel reinforcement learning framework for aligning LLMs. Instead of directly maximizing cumulative rewards like PPO or GRPO, GIFT minimizes the discrepancy between implicit and explicit reward models. It combines three key ideas: (1) the online multi-response generation and normalization of GRPO, (2) the implicit reward formulation of DPO, and (3) the implicit-explicit reward alignment principle of UNA. By jointly normalizing the implicit and explicit rewards, GIFT eliminates an otherwise intractable term that prevents effective use of implicit rewards. This normalization transforms the complex reward maximization objective into a simple mean squared error (MSE) loss between the normalized reward functions, converting a non-convex optimization problem into a convex, stable, and analytically differentiable formulation. Unlike offline methods such as DPO and UNA, GIFT remains on-policy and thus retains exploration capability. Compared to GRPO, it requires fewer hyperparameters, converges faster, and generalizes better with significantly reduced training overfitting. Empirically, GIFT achieves superior reasoning and alignment performance on mathematical benchmarks while remaining computationally efficient.