The Best of N Worlds: Aligning Reinforcement Learning with Best-of-N Sampling via max@k Optimisation
作者: Farid Bagirov, Mikhail Arkhipov, Ksenia Sycheva, Evgeniy Glukhov, Egor Bogomolov
分类: cs.LG
发布日期: 2025-10-27
💡 一句话要点
提出基于max@k优化的强化学习方法,提升LLM在Best-of-N采样中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 Best-of-N采样 max@k优化 策略梯度
📋 核心要点
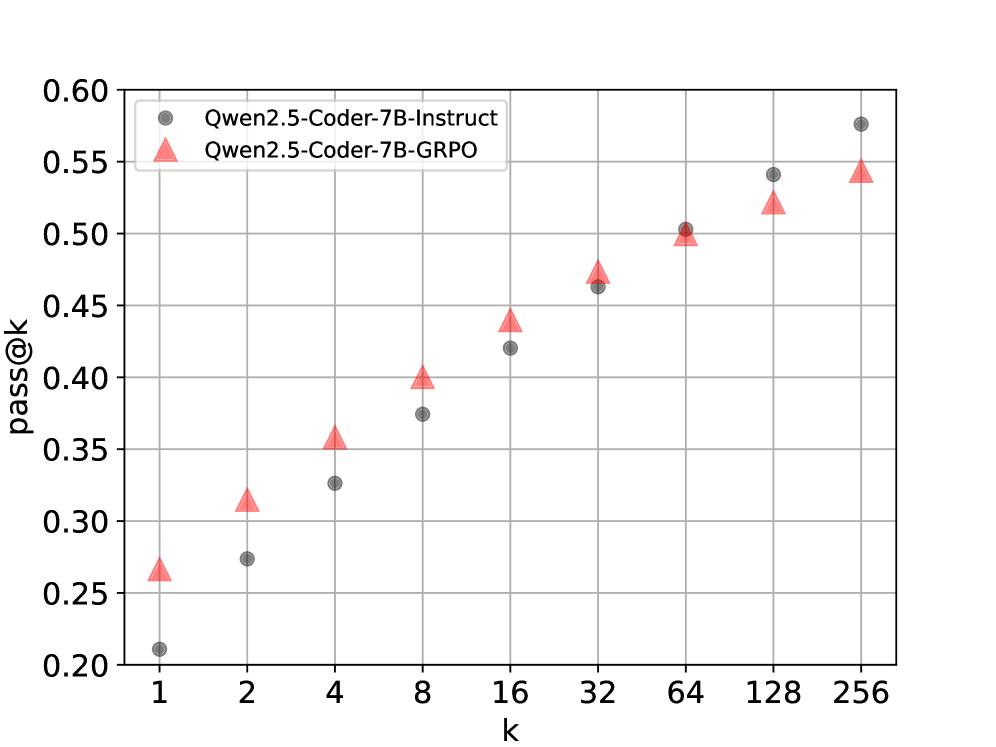
- 现有RLVR方法在提升LLM问题解决能力的同时,可能降低生成多样性,导致Best-of-N采样性能下降。
- 论文提出直接优化max@k指标的强化学习方法,通过无偏梯度估计和off-policy更新提高样本效率。
- 实验表明,该方法能有效优化off-policy场景下的max@k指标,使模型更好地适应Best-of-N推理。
📝 摘要(中文)
本文研究了将可验证奖励强化学习(RLVR)应用于数学和编程领域,该方法显著提升了大型语言模型(LLM)的推理和问题解决能力。尽管RLVR在单次生成问题求解中表现出色,但强化学习微调过程可能会损害模型的探索能力,导致生成多样性降低,并降低Best-of-N采样在大N值时的性能。本文着重于优化max@k指标,它是pass@k的连续泛化。我们推导了用于直接优化此指标的无偏on-policy梯度估计。此外,我们将推导扩展到off-policy更新,这是现代RLVR算法中的常见元素,可以提高样本效率。实验结果表明,我们的目标有效地优化了off-policy场景中的max@k指标,使模型与Best-of-N推理策略对齐。
🔬 方法详解
问题定义:论文旨在解决强化学习微调LLM时,模型探索能力下降,导致Best-of-N采样性能降低的问题。现有方法在优化单次生成性能时,忽略了生成多样性的重要性,使得在大规模采样时无法充分利用模型的潜力。
核心思路:论文的核心思路是直接优化max@k指标,该指标是pass@k的连续泛化,能够更好地反映Best-of-N采样的性能。通过优化max@k,可以引导模型生成更多样化且高质量的候选答案,从而提升整体性能。
技术框架:整体框架基于强化学习,利用奖励信号引导LLM生成更好的结果。主要包含以下几个阶段:1) LLM生成候选答案;2) 使用奖励函数评估候选答案的质量;3) 计算max@k指标;4) 使用on-policy或off-policy梯度估计优化max@k指标。
关键创新:论文的关键创新在于提出了max@k指标的无偏梯度估计方法,并将其扩展到off-policy更新。这使得可以直接优化Best-of-N采样的性能,并且能够利用历史数据提高样本效率。
关键设计:论文使用了max@k作为奖励函数,并推导了其梯度。对于on-policy更新,使用了标准的策略梯度方法。对于off-policy更新,使用了重要性采样来校正数据分布的差异。具体的网络结构和参数设置取决于具体的LLM和任务。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了所提出方法的有效性,表明其能够有效地优化off-policy场景下的max@k指标,从而提升Best-of-N采样的性能。具体的性能提升数据和对比基线在论文中进行了详细的展示,证明了该方法相对于现有方法的优势。
🎯 应用场景
该研究成果可应用于各种需要LLM进行问题求解的场景,例如数学问题求解、代码生成、问答系统等。通过优化Best-of-N采样性能,可以显著提升LLM在这些任务中的准确性和可靠性,从而提高自动化问题解决的效率和质量。未来,该方法可以进一步推广到其他生成式任务中。
📄 摘要(原文)
The application of Reinforcement Learning with Verifiable Rewards (RLVR) to mathematical and coding domains has demonstrated significant improvements in the reasoning and problem-solving abilities of Large Language Models. Despite its success in single generation problem solving, the reinforcement learning fine-tuning process may harm the model's exploration ability, as reflected in decreased diversity of generations and a resulting degradation of performance during Best-of-N sampling for large N values. In this work, we focus on optimizing the max@k metric, a continuous generalization of pass@k. We derive an unbiased on-policy gradient estimate for direct optimization of this metric. Furthermore, we extend our derivations to the off-policy updates, a common element in modern RLVR algorithms, that allows better sample efficiency. Empirically, we show that our objective effectively optimizes max@k metric in off-policy scenarios, aligning the model with the Best-of-N inference strategy.