Increasing LLM Coding Capabilities through Diverse Synthetic Coding Tasks
作者: Amal Abed, Ivan Lukic, Jörg K. H. Franke, Frank Hutter
分类: cs.LG, cs.AI
发布日期: 2025-10-27
备注: Presented at the 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Workshop: The 4th Deep Learning for Code Workshop (DL4C)
💡 一句话要点
提出一种基于多样化合成编码任务的LLM能力提升方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 合成数据 推理 微调 遗传算法 数据增强
📋 核心要点
- 现有代码生成数据集缺乏多样性,且忽略了编码过程中的推理步骤,限制了LLM的编码能力。
- 提出一种可扩展的合成数据生成流程,生成包含指令、推理、代码和测试的四元组数据,使模型学习编码的“如何做”。
- 实验表明,使用该数据集微调LLM,在编码基准测试中取得了持续的改进,且推理感知数据可替代模型缩放。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成方面展现出令人瞩目的潜力,但其进展仍受限于缺乏大规模、多样化且与人类推理对齐的数据集。现有资源大多只提供问题和解决方案的配对,忽略了指导编码的中间思考过程。为了弥补这一差距,我们提出了一种可扩展的合成数据生成流程,生成近80万个指令-推理-代码-测试四元组。每个样本结合了任务、逐步推理轨迹、可行的解决方案和可执行的测试,使模型不仅能学习“做什么”,还能学习“如何做”。我们的流程结合了四个关键组件:精选的竞赛问题、网络挖掘的并通过相关性分类器过滤的内容、由推理模式指导的数据扩展以及基于执行的多阶段验证。一种遗传变异算法进一步增加了任务多样性,同时保持了推理轨迹和代码实现之间的一致性。我们的关键发现是,在此数据集上微调LLM可以持续改进编码基准。除了原始准确性之外,推理感知数据可以替代模型缩放,跨架构泛化,并在相同的样本预算下优于领先的开源替代方案。我们的工作将以推理为中心的合成数据生成确立为提高LLM编码能力的有效方法。我们发布了我们的数据集和生成流程,以促进进一步的研究。
🔬 方法详解
问题定义:现有的大型语言模型在代码生成方面表现出潜力,但缺乏足够大规模、多样化且包含推理过程的数据集。现有数据集通常只包含问题和对应的代码解决方案,而忽略了人类解决问题时的思考过程,这限制了模型学习更复杂的编码任务和推理能力。
核心思路:本文的核心思路是通过合成数据生成来弥补现有数据集的不足。通过生成包含问题、推理步骤、代码和测试用例的四元组数据,让模型学习如何一步步地解决问题,而不仅仅是记住问题的答案。这种方法旨在提高模型在面对新问题时的泛化能力和解决问题的能力。
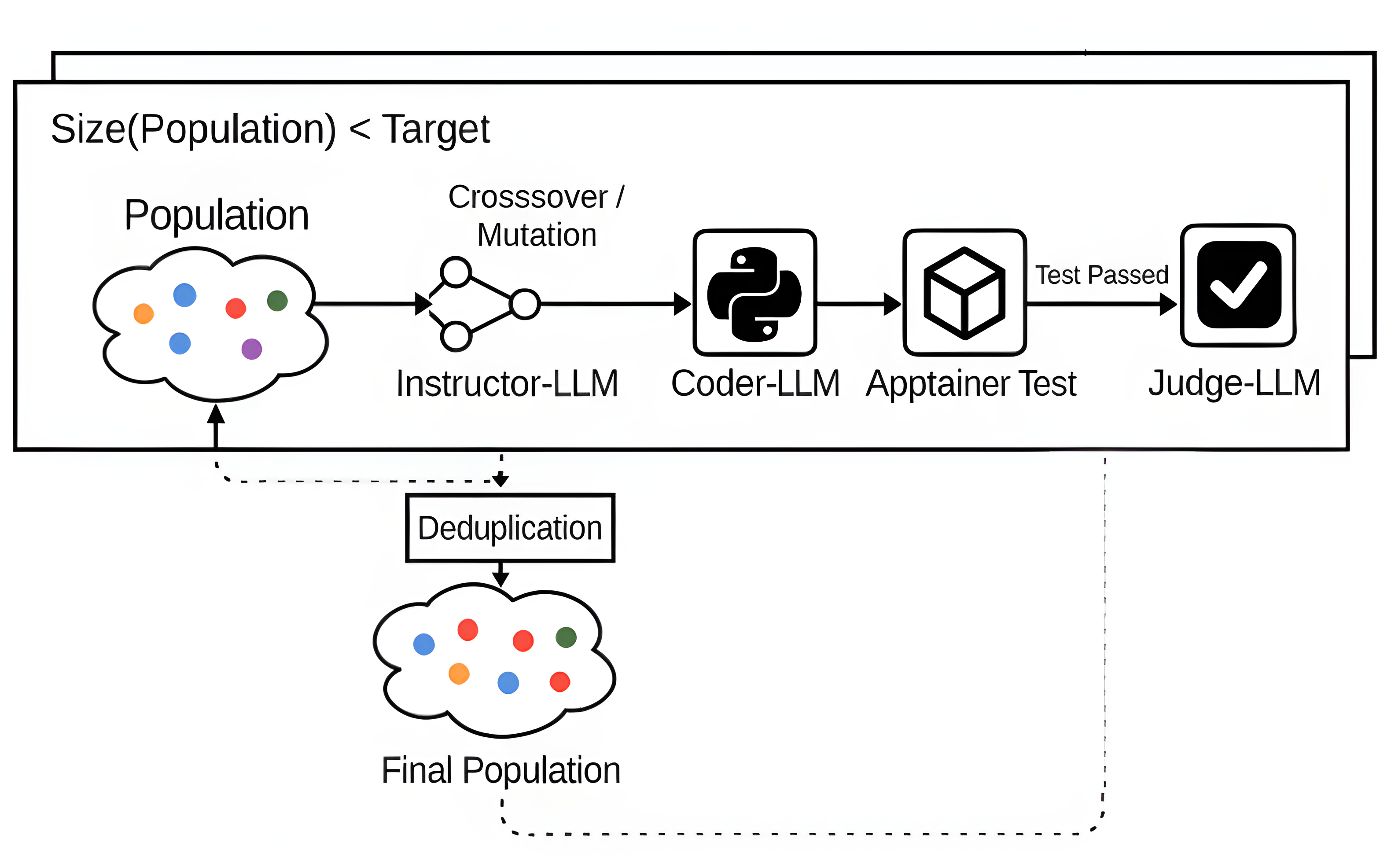
技术框架:该方法包含一个可扩展的合成数据生成流程,主要由四个模块组成:1) 精选竞赛问题:从公开的编程竞赛中收集高质量的问题。2) 网络挖掘内容:从网络上抓取与问题相关的代码和推理过程,并使用相关性分类器进行过滤。3) 基于推理模式的数据扩展:利用预定义的推理模式,对现有数据进行扩展,生成更多样化的数据。4) 基于执行的多阶段验证:通过执行生成的代码,验证其正确性,并对推理过程进行评估。此外,还使用遗传变异算法来增加任务的多样性。
关键创新:该方法最重要的创新点在于合成了包含推理过程的编码数据。与以往只关注问题和代码的数据集不同,该方法显式地生成了解决问题的中间步骤,使模型能够学习到人类的思考方式。此外,使用遗传变异算法来增加任务的多样性,进一步提高了模型的泛化能力。
关键设计:在数据扩展阶段,使用了预定义的推理模式,例如“分解问题”、“逐步求解”等。在验证阶段,使用了多阶段的执行测试,包括单元测试、集成测试等,以确保代码的正确性。遗传变异算法通过对现有代码进行小的修改,例如改变变量名、调整循环顺序等,来生成新的代码,同时保持代码的语义不变。
🖼️ 关键图片
📊 实验亮点
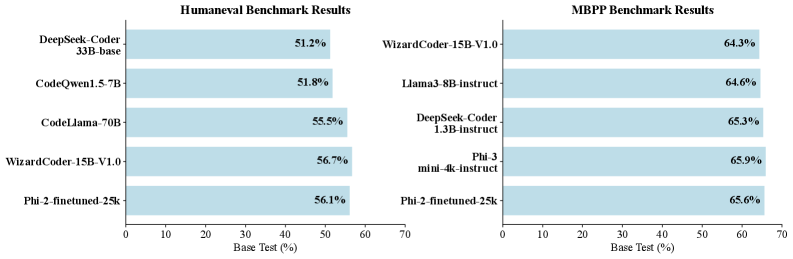
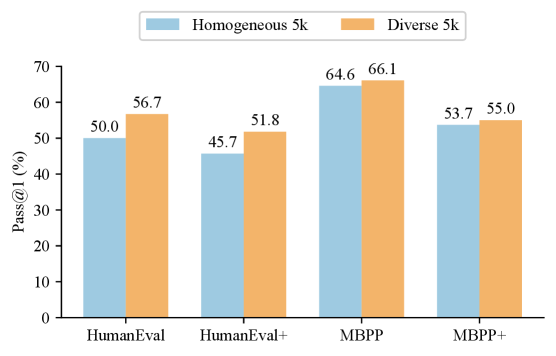
通过在合成数据集上微调LLM,在编码基准测试中取得了持续的改进。实验表明,推理感知数据可以替代模型缩放,跨架构泛化,并在相同的样本预算下优于领先的开源替代方案。这表明该方法在提高LLM编码能力方面具有显著的优势。
🎯 应用场景
该研究成果可应用于自动化代码生成、智能编程助手、代码教育等领域。通过提供包含推理过程的训练数据,可以提高代码生成模型的准确性和可靠性,降低开发成本,并帮助初学者更好地理解编程思维。
📄 摘要(原文)
Large language models (LLMs) have shown impressive promise in code generation, yet their progress remains limited by the shortage of large-scale datasets that are both diverse and well-aligned with human reasoning. Most existing resources pair problems with solutions, but omit the intermediate thought process that guides coding. To close this gap, we present a scalable synthetic data generation pipeline that produces nearly 800k instruction-reasoning-code-test quadruplets. Each sample combines a task, a step-by-step reasoning trace, a working solution, and executable tests, enabling models to learn not just the what but also the how of problem solving. Our pipeline combines four key components: curated contest problems, web-mined content filtered by relevance classifiers, data expansion guided by reasoning patterns, and multi-stage execution-based validation. A genetic mutation algorithm further increases task diversity while maintaining consistency between reasoning traces and code implementations. Our key finding is that fine-tuning LLMs on this dataset yields consistent improvements on coding benchmarks. Beyond raw accuracy, reasoning-aware data can substitute for model scaling, generalize across architectures, and outperform leading open-source alternatives under identical sample budgets. Our work establishes reasoning-centered synthetic data generation as an efficient approach for advancing coding capabilities in LLMs. We publish our dataset and generation pipeline to facilitate further research.