Towards Stable and Effective Reinforcement Learning for Mixture-of-Experts
作者: Di Zhang, Xun Wu, Shaohan Huang, Lingjie Jiang, Yaru Hao, Li Dong, Zewen Chi, Zhifang Sui, Furu Wei
分类: cs.LG, cs.CL
发布日期: 2025-10-27 (更新: 2026-01-12)
备注: Added additional experiments, improved analysis, and fixed minor issues
💡 一句话要点
提出基于路由感知的重采样方法,稳定MoE模型的强化学习训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 混合专家模型 强化学习 重要性采样 路由感知 梯度方差
📋 核心要点
- 现有强化学习方法主要关注稠密模型,对MoE模型的强化学习训练研究不足,MoE模型训练时常出现不稳定的情况。
- 论文提出一种路由感知的重采样方法,通过路由logits引导的重缩放策略,降低梯度方差,缓解训练发散问题。
- 实验结果表明,该方法显著提高了MoE模型的收敛稳定性和最终性能,验证了其有效性。
📝 摘要(中文)
近年来,强化学习(RL)的进步显著提升了大规模语言模型的训练效果,在生成质量和推理能力方面取得了显著进展。然而,现有研究大多集中在稠密模型上,而混合专家(MoE)架构的RL训练仍未得到充分探索。为了解决MoE训练中常见的训练不稳定问题,我们提出了一种新颖的、路由感知的优化重要性采样(IS)权重的方法,用于离线强化学习。具体来说,我们设计了一种由路由logits引导的重缩放策略,有效地降低了梯度方差,并缓解了训练发散。实验结果表明,我们的方法显著提高了MoE模型的收敛稳定性和最终性能,突出了针对MoE架构定制的RL算法创新的潜力,并为大规模专家模型的有效训练提供了一个有希望的方向。
🔬 方法详解
问题定义:论文旨在解决MoE模型在强化学习训练中遇到的不稳定性问题。现有方法在训练MoE模型时,由于专家选择的不平衡以及由此带来的梯度方差过大,容易导致训练发散,难以获得稳定的性能提升。
核心思路:论文的核心思路是利用MoE模型中路由器的信息,对重要性采样(IS)的权重进行调整,从而降低梯度方差,稳定训练过程。通过关注每个样本选择专家的概率(即路由logits),对重要性权重进行重缩放,使得梯度更新更加平滑,避免因个别样本的极端权重而导致训练崩溃。
技术框架:整体框架基于离线强化学习,主要包含以下几个模块:1) 离线数据集:包含历史策略产生的数据;2) MoE模型:包含多个专家网络和一个路由器网络;3) 路由感知的重要性采样:利用路由器logits调整重要性权重;4) 策略优化:使用调整后的重要性权重更新策略网络。
关键创新:论文的关键创新在于提出了路由感知的重缩放策略,将MoE模型中的路由器信息融入到重要性采样的权重计算中。与传统的重要性采样方法相比,该方法能够更有效地降低梯度方差,从而提高训练的稳定性。这种方法是针对MoE架构的特性而设计的,具有较强的针对性。
关键设计:关键设计在于如何利用路由logits进行权重重缩放。具体来说,对于每个样本,根据其选择各个专家的概率,对重要性权重进行调整。一种可能的实现方式是,对于被高概率选择的专家,降低其对应样本的重要性权重;对于被低概率选择的专家,提高其对应样本的重要性权重。具体的重缩放函数需要根据实际情况进行调整,以达到最佳的梯度方差降低效果。
🖼️ 关键图片

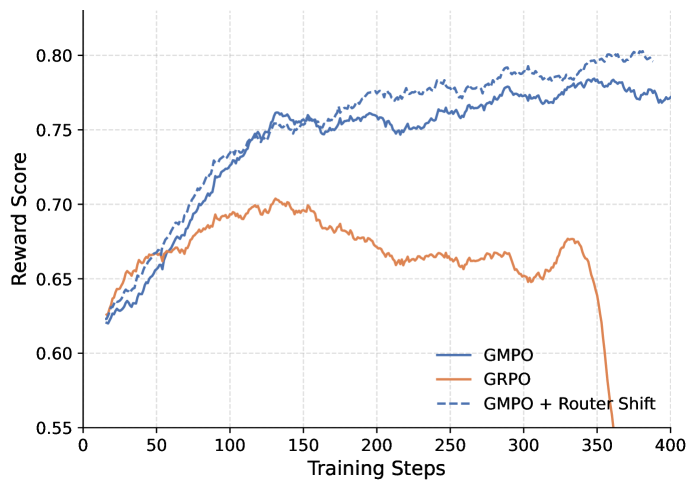
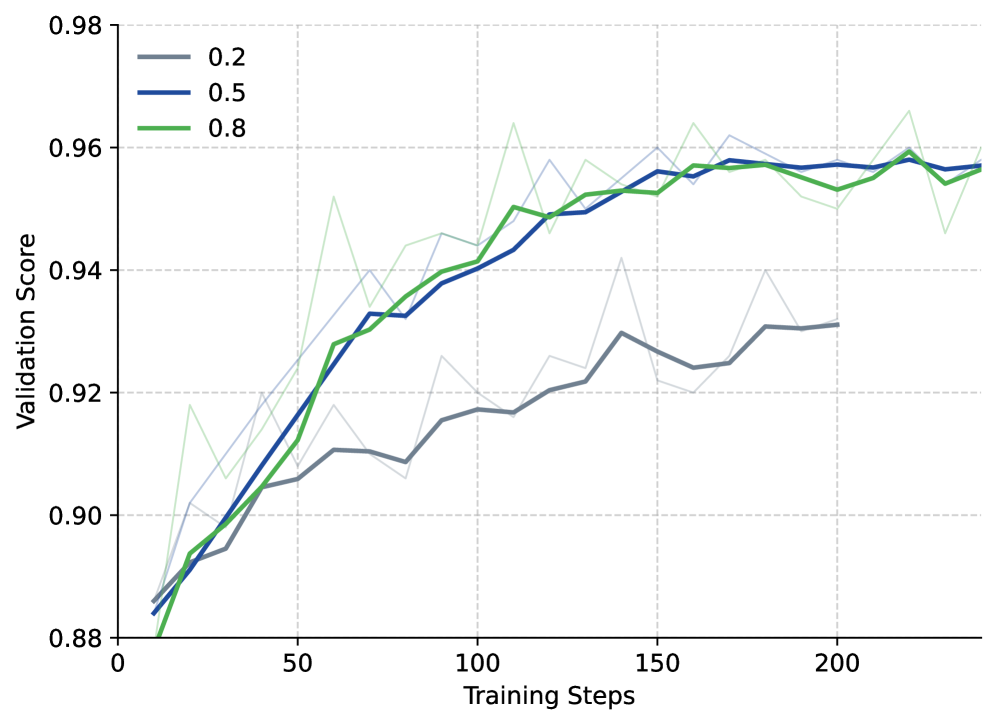
📊 实验亮点
实验结果表明,提出的路由感知重采样方法能够显著提高MoE模型在强化学习训练中的收敛稳定性和最终性能。具体来说,相比于传统的强化学习方法,该方法能够更快地收敛,并且能够达到更高的奖励值。实验结果验证了该方法在MoE模型训练中的有效性,并为未来的研究提供了新的方向。
🎯 应用场景
该研究成果可应用于各种需要大规模语言模型的强化学习任务中,例如对话生成、文本摘要、机器翻译等。通过稳定MoE模型的训练,可以提升这些任务的性能和效率,并为更大规模的专家模型训练奠定基础。该方法在AI助手、智能客服等领域具有潜在的应用价值。
📄 摘要(原文)
Recent advances in reinforcement learning (RL) have substantially improved the training of large-scale language models, leading to significant gains in generation quality and reasoning ability. However, most existing research focuses on dense models, while RL training for Mixture-of-Experts (MoE) architectures remains underexplored. To address the instability commonly observed in MoE training, we propose a novel router-aware approach to optimize importance sampling (IS) weights in off-policy RL. Specifically, we design a rescaling strategy guided by router logits, which effectively reduces gradient variance and mitigates training divergence. Experimental results demonstrate that our method significantly improves both the convergence stability and the final performance of MoE models, highlighting the potential of RL algorithmic innovations tailored to MoE architectures and providing a promising direction for efficient training of large-scale expert models.