Offline Preference Optimization via Maximum Marginal Likelihood Estimation
作者: Saeed Najafi, Alona Fyshe
分类: cs.LG, cs.CL
发布日期: 2025-10-27 (更新: 2026-01-23)
备注: EACL 2026, camera ready
💡 一句话要点
提出基于最大边缘似然估计的离线偏好优化方法MMPO,简化LLM对齐流程。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏好优化 最大边缘似然 离线学习 人类反馈
📋 核心要点
- 现有RLHF方法在对齐LLM与人类偏好时,存在流程复杂、训练不稳定等问题。
- MMPO通过最大化边缘似然,隐式地进行偏好优化,无需显式奖励模型和熵最大化。
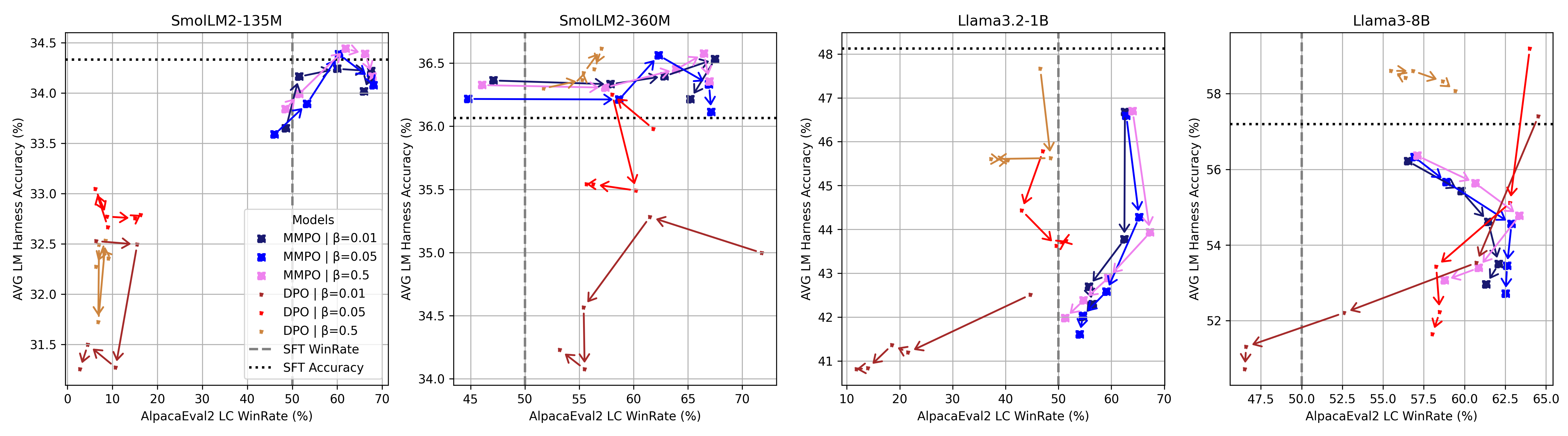
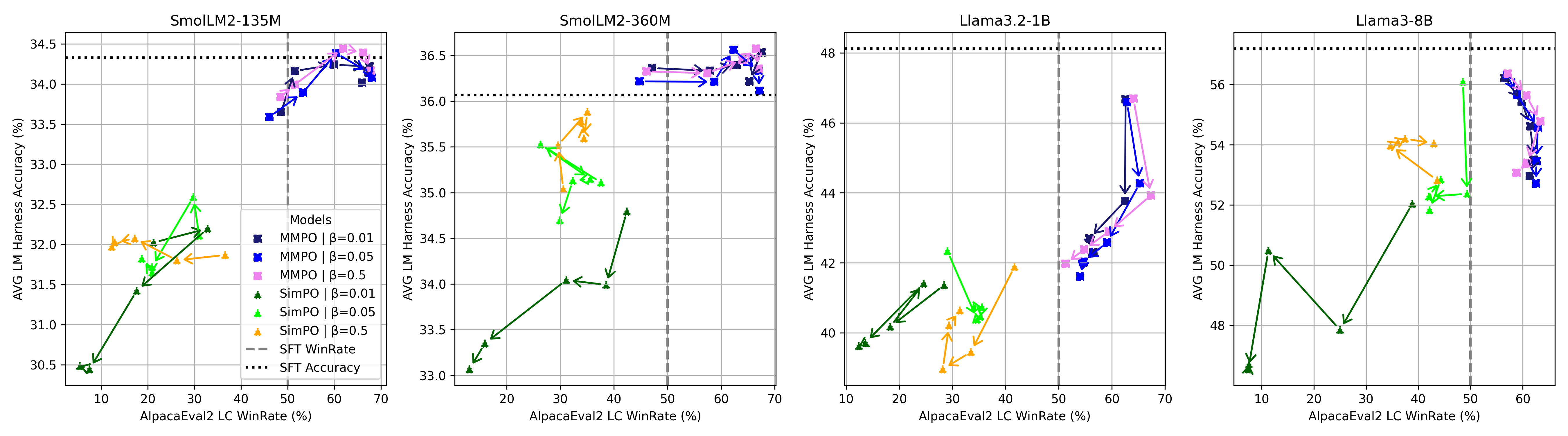
- 实验表明,MMPO在超参数稳定性、偏好对齐和通用语言能力保持方面表现更优。
📝 摘要(中文)
将大型语言模型(LLM)与人类偏好对齐至关重要,但诸如基于人类反馈的强化学习(RLHF)等标准方法通常复杂且不稳定。本文提出了一种新的、更简单的方法,通过最大边缘似然(MML)估计的角度重新构建对齐过程。我们提出的基于MML的偏好优化(MMPO)方法,通过最大化首选文本输出的边缘对数似然,并将偏好对作为近似样本,从而避免了对显式奖励模型和熵最大化的需求。理论上,我们证明了MMPO隐式地执行偏好优化,产生一个加权梯度,自然地提升了选择的响应相对于拒绝的响应的权重。在参数规模从1.35亿到80亿的模型上,我们通过实验表明,MMPO:1)相对于其他基线,在超参数β方面更稳定;2)在更好地保持基础模型通用语言能力的同时,实现了有竞争力或更优越的偏好对齐。通过一系列消融实验,我们表明,这种改进的性能确实归因于MMPO在梯度更新中进行的隐式偏好优化。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)与人类偏好对齐的问题。现有方法,如RLHF,依赖于复杂的强化学习流程,训练过程不稳定,且需要显式地训练奖励模型。这些方法计算成本高昂,并且对超参数敏感。
核心思路:论文的核心思路是将偏好对齐问题转化为最大边缘似然(MML)估计问题。通过最大化首选文本输出的边缘对数似然,模型能够学习到人类的偏好,而无需显式地构建奖励模型。这种方法简化了对齐流程,并提高了训练的稳定性。
技术框架:MMPO方法的整体框架包括以下几个步骤:1) 收集人类偏好数据,形成偏好对(首选响应,拒绝响应);2) 使用LLM生成响应;3) 计算首选响应的边缘对数似然;4) 使用梯度上升更新LLM的参数,以最大化边缘对数似然。该框架避免了显式奖励模型的训练,直接优化LLM的生成策略。
关键创新:MMPO的关键创新在于将偏好优化问题转化为最大边缘似然估计问题,从而实现了隐式的偏好优化。与传统的RLHF方法相比,MMPO无需训练单独的奖励模型,也无需进行复杂的强化学习过程。此外,MMPO通过加权梯度更新,自然地提升了首选响应的权重,降低了拒绝响应的权重。
关键设计:MMPO的关键设计包括:1) 使用偏好对作为MML估计的样本;2) 使用LLM生成响应,并计算边缘对数似然;3) 使用Adam优化器更新LLM的参数。超参数β控制了首选响应和拒绝响应之间的权重差异,实验表明MMPO对β的敏感度较低,具有更好的稳定性。损失函数为负的边缘对数似然,目标是最小化该损失函数。
🖼️ 关键图片
📊 实验亮点
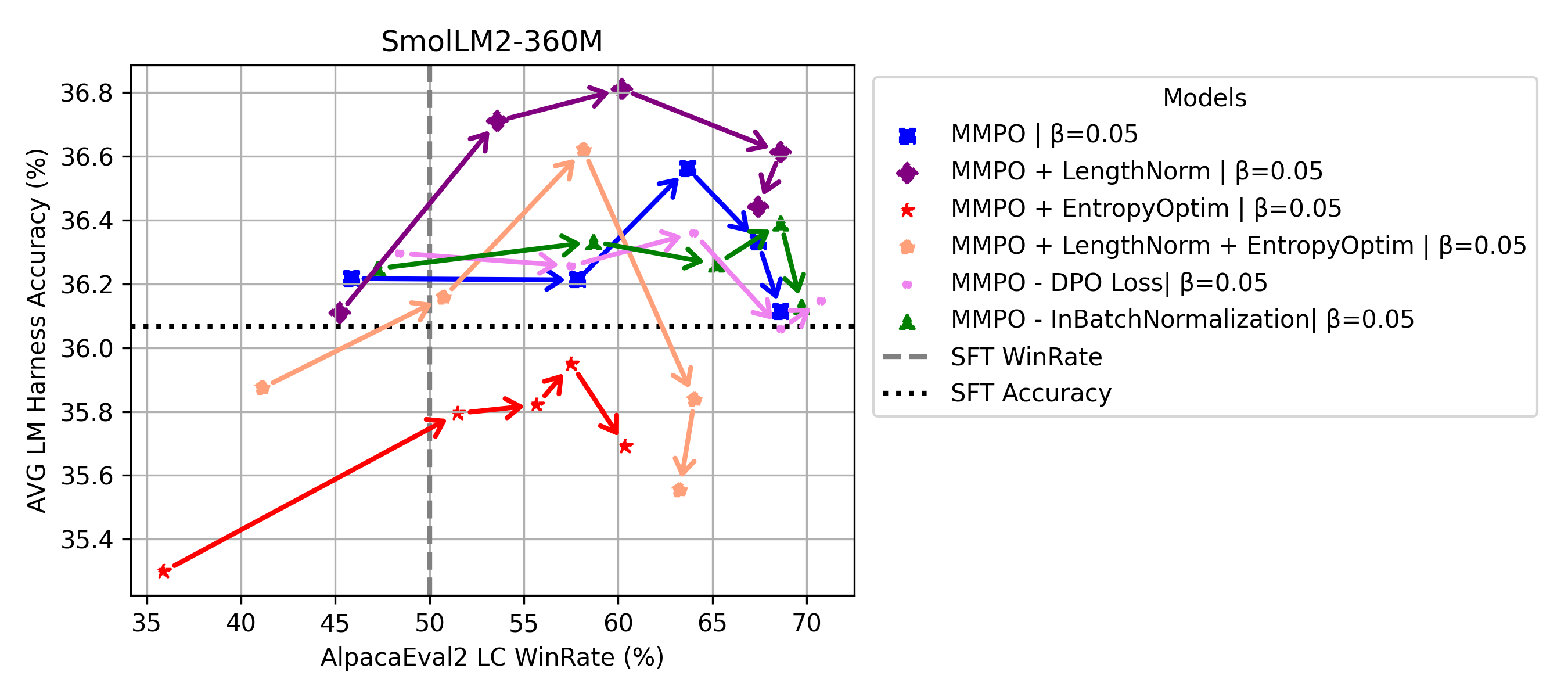
实验结果表明,MMPO在1.35亿到80亿参数规模的模型上,相对于基线方法,在超参数β的稳定性方面表现更优。同时,MMPO在偏好对齐方面达到了有竞争力或更优越的性能,并且更好地保持了基础模型的通用语言能力。消融实验证明,MMPO的性能提升主要归功于其在梯度更新中进行的隐式偏好优化。
🎯 应用场景
该研究成果可广泛应用于各种需要与人类偏好对齐的LLM应用场景,例如对话系统、文本摘要、代码生成等。通过MMPO方法,可以更高效、更稳定地训练出符合人类偏好的LLM,提升用户体验,并降低模型部署和维护的成本。未来,该方法可以进一步扩展到多模态场景,实现更广泛的应用。
📄 摘要(原文)
Aligning Large Language Models (LLMs) with human preferences is crucial, but standard methods like Reinforcement Learning from Human Feedback (RLHF) are often complex and unstable. In this work, we propose a new, simpler approach that recasts alignment through the lens of Maximum Marginal Likelihood (MML) estimation. Our new MML based Preference Optimization (MMPO) maximizes the marginal log-likelihood of a preferred text output, using the preference pair as samples for approximation, and forgoes the need for both an explicit reward model and entropy maximization. We theoretically demonstrate that MMPO implicitly performs preference optimization, producing a weighted gradient that naturally up-weights chosen responses over rejected ones. Across models ranging from 135M to 8B parameters, we empirically show that MMPO: 1) is more stable with respect to the hyperparameter $β$ compared to alternative baselines, and 2) achieves competitive or superior preference alignment while better preserving the base model's general language capabilities. Through a series of ablation experiments, we show that this improved performance is indeed attributable to MMPO's implicit preference optimization within the gradient updates.