The Lossy Horizon: Error-Bounded Predictive Coding for Lossy Text Compression (Episode I)
作者: Nnamdi Aghanya, Jun Li, Kewei Wang
分类: cs.LG, cs.CL, cs.IT
发布日期: 2025-10-25
备注: 12 pages, 7 figures
💡 一句话要点
提出Error-Bounded Predictive Coding,用于基于LLM的高效有损文本压缩
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 有损文本压缩 大型语言模型 Masked Language Model 率失真优化 预测编码
📋 核心要点
- 现有有损文本压缩方法难以充分利用大型语言模型的先验知识,导致压缩率和重建质量难以兼顾。
- Error-Bounded Predictive Coding (EPC) 通过预测mask内容并仅存储预测错误的校正信息,实现高效的率失真控制。
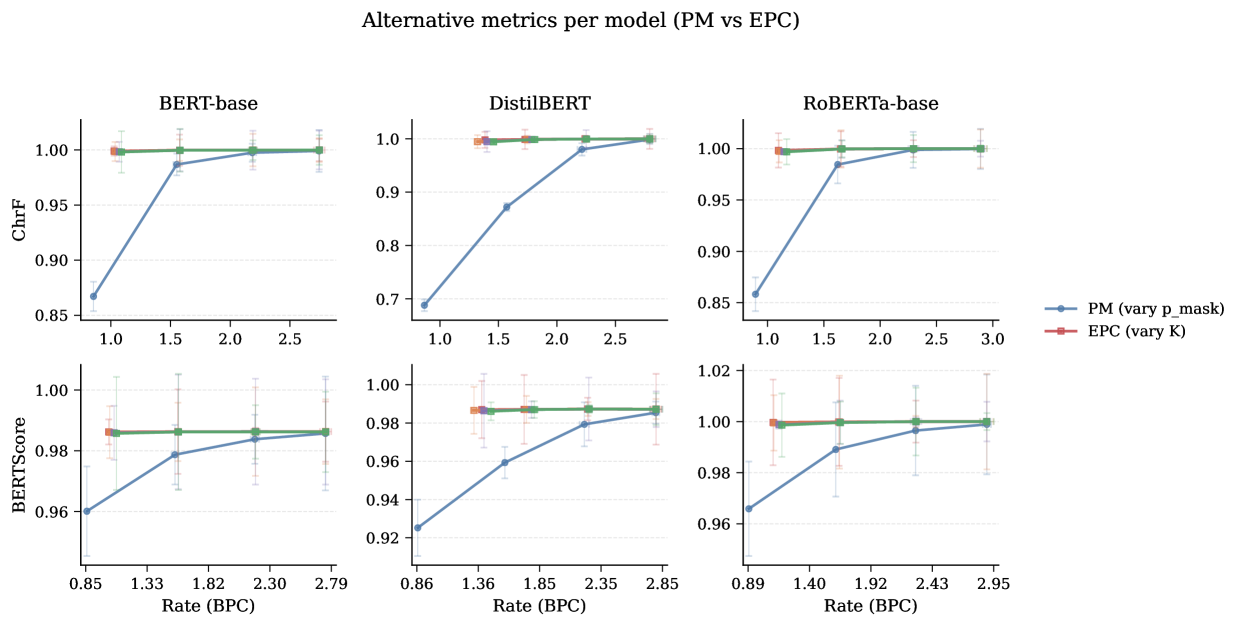
- 实验表明,EPC在显著降低比特率的同时,能够提供比Predictive Masking (PM) 更好的文本重建保真度。
📝 摘要(中文)
本文研究了大型语言模型(LLM)在有损压缩领域的应用,利用其强大的概率建模能力实现接近最优的压缩效果。论文提出了一种名为Error-Bounded Predictive Coding (EPC) 的有损文本编解码器,它利用Masked Language Model (MLM) 作为解压缩器。EPC不存储原始token的子集,而是允许模型预测被mask的内容,并且仅当模型的最佳预测不正确时才存储最小的、基于排序的校正信息。这创建了一个残差通道,提供连续的率失真控制。通过与更简单的Predictive Masking (PM) 基线方法以及基于变换的Vector Quantisation with a Residual Patch (VQ+RE) 方法进行比较,实验结果表明EPC始终优于PM,通过更有效地利用模型的内在知识,在显著降低比特率的同时提供更高的保真度。
🔬 方法详解
问题定义:论文旨在解决有损文本压缩问题,即如何在保证一定重建质量的前提下,尽可能地降低文本的存储空间。现有方法,如直接存储token子集,或使用向量量化等方法,无法充分利用大型语言模型(LLM)强大的文本建模能力,导致压缩效率不高,或者在相同压缩率下重建质量较差。
核心思路:论文的核心思路是利用Masked Language Model (MLM) 的预测能力,只存储模型预测错误的信息。具体来说,首先mask文本的一部分内容,然后让MLM预测这些被mask的内容。如果模型的最佳预测是正确的,则不需要存储任何信息;如果预测错误,则存储一个基于排序的校正信息,用于修正模型的预测。这样,只需要存储少量的残差信息,就可以实现较高的压缩率。
技术框架:EPC的整体框架包括以下几个步骤:1. Masking: 根据一定的策略,对输入文本进行mask操作。2. Prediction: 使用Masked Language Model (MLM) 预测被mask的内容。3. Correction: 如果模型的最佳预测不正确,则计算并存储一个基于排序的校正信息。4. Decoding: 在解码端,首先使用MLM预测被mask的内容,然后根据存储的校正信息修正模型的预测,从而重建原始文本。
关键创新:EPC的关键创新在于它利用MLM的预测能力,只存储预测错误的校正信息,从而实现了高效的率失真控制。与传统的有损压缩方法相比,EPC能够更有效地利用LLM的先验知识,从而在相同的压缩率下提供更高的重建质量。此外,EPC的残差通道设计允许连续的率失真控制,可以根据不同的应用场景调整压缩率和重建质量。
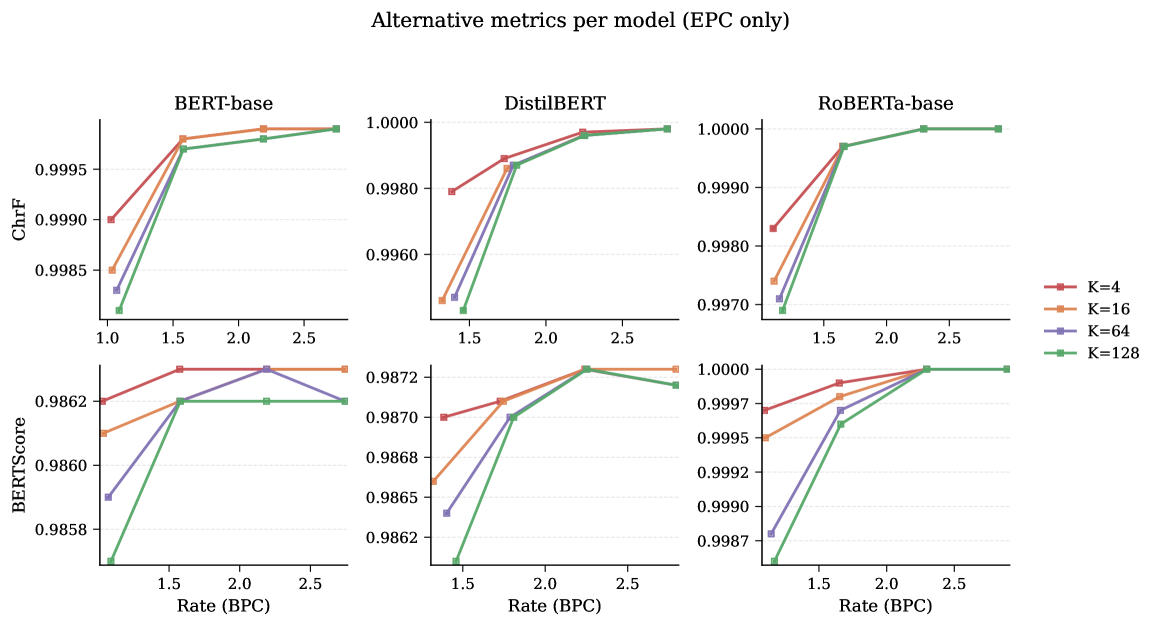
关键设计:EPC的关键设计包括:1. Masking策略: 如何选择被mask的token,例如随机mask,或者根据token的重要性进行mask。2. 校正信息的编码方式: 如何高效地编码校正信息,例如使用基于排序的编码方式,只存储正确token在模型预测结果中的排名。3. 率失真优化: 如何平衡压缩率和重建质量,例如通过调整masking的比例,或者调整校正信息的编码精度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Error-Bounded Predictive Coding (EPC) 在有损文本压缩方面优于现有的Predictive Masking (PM) 和 Vector Quantisation with a Residual Patch (VQ+RE) 方法。EPC通过更有效地利用模型的内在知识,在显著降低比特率的同时提供更高的保真度。具体的性能数据未知,但论文强调EPC在率失真分析中始终优于PM。
🎯 应用场景
该研究成果可应用于多种场景,例如低带宽网络环境下的文本传输、大规模文本数据的存储和检索、以及对存储空间敏感的移动设备等。通过有损压缩,可以在有限的带宽或存储空间下,传输或存储更多的文本信息。此外,该方法还可以用于文本摘要、机器翻译等任务中,通过有损压缩去除冗余信息,提高处理效率。
📄 摘要(原文)
Large Language Models (LLMs) can achieve near-optimal lossless compression by acting as powerful probability models. We investigate their use in the lossy domain, where reconstruction fidelity is traded for higher compression ratios. This paper introduces Error-Bounded Predictive Coding (EPC), a lossy text codec that leverages a Masked Language Model (MLM) as a decompressor. Instead of storing a subset of original tokens, EPC allows the model to predict masked content and stores minimal, rank-based corrections only when the model's top prediction is incorrect. This creates a residual channel that offers continuous rate-distortion control. We compare EPC to a simpler Predictive Masking (PM) baseline and a transform-based Vector Quantisation with a Residual Patch (VQ+RE) approach. Through an evaluation that includes precise bit accounting and rate-distortion analysis, we demonstrate that EPC consistently dominates PM, offering superior fidelity at a significantly lower bit rate by more efficiently utilising the model's intrinsic knowledge.