Agentic Reinforcement Learning for Real-World Code Repair
作者: Siyu Zhu, Anastasiya Karpovich, Albert Chen, Jessica Koscheka, Shailesh Jannu, Di Wen, Yuqing Zhu, Rohit Jain, Alborz Geramifard
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-24
💡 一句话要点
提出Agentic强化学习方法,解决真实代码仓库中的代码修复问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 代码修复 强化学习 监督微调 代码仓库 Agentic Reinforcement Learning
📋 核心要点
- 现有代码修复Agent在真实代码仓库中训练时,面临构建复杂、依赖关系变化导致评估不稳定的问题。
- 论文提出一种Agentic强化学习方法,通过可验证的pipeline和简化的RL环境,提升代码修复Agent的性能。
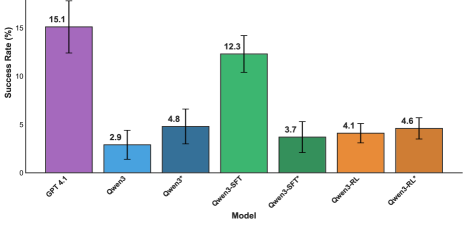
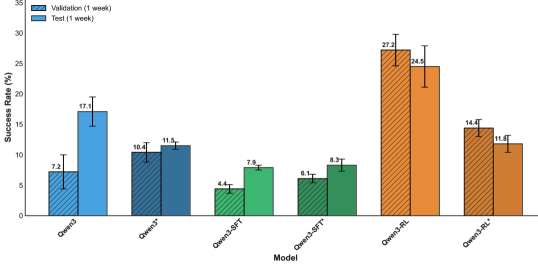
- 实验表明,监督微调的Qwen3-32B模型性能与GPT-4.1相当,且规模更小,强化学习进一步提升了7-20%的性能。
📝 摘要(中文)
本文旨在解决真实代码仓库中训练可靠的代码修复Agent的挑战,其中复杂的构建和不断变化的依赖关系使得评估不稳定。我们开发了一个可验证的pipeline,其成功标准定义为修复后的构建验证,并通过固定依赖关系和禁用自动升级,提高了约1000个真实问题的可重复性。在此基础上,我们引入了一个可扩展的简化pipeline,用于大规模强化学习(RL)。利用此设置,我们在完整pipeline中对Qwen3-32B进行了监督微调,并在简化环境中对SFT模型应用了RL。从GPT-4.1轨迹中提炼出的SFT模型性能相当,但规模缩小了56倍,并且在匹配的训练-测试条件下,RL增加了7-20%的绝对收益。“思考模式”在我们的实验中表现相当甚至更差。SFT和RL模型都未能跨环境泛化,突出了匹配训练-测试环境对于构建可靠的真实代码修复Agent的重要性。
🔬 方法详解
问题定义:论文旨在解决在真实代码仓库中训练可靠的代码修复Agent的难题。现有的方法在真实场景中面临诸多挑战,例如复杂的构建过程、频繁变化的依赖关系以及难以复现的实验结果,这些因素使得评估代码修复Agent的性能变得非常困难,阻碍了其在实际应用中的部署。
核心思路:论文的核心思路是构建一个可验证且可扩展的训练pipeline,用于训练和评估代码修复Agent。通过固定依赖关系、禁用自动升级等手段,提高实验的可重复性。同时,为了支持大规模强化学习,论文还设计了一个简化的训练环境,降低了训练的计算成本。在此基础上,论文采用监督微调(SFT)和强化学习(RL)相结合的方法,提升Agent的代码修复能力。
技术框架:整体框架包含两个主要的pipeline:一个是完整的、可验证的pipeline,用于评估Agent的性能;另一个是简化的pipeline,用于大规模的强化学习训练。首先,使用GPT-4.1生成代码修复轨迹,并用这些数据对Qwen3-32B模型进行监督微调(SFT)。然后,在简化的环境中,使用强化学习算法对SFT模型进行进一步的优化。最终,在完整的pipeline中评估模型的性能。
关键创新:论文的关键创新在于构建了一个可验证且可扩展的训练pipeline,并结合监督微调和强化学习来提升代码修复Agent的性能。通过固定依赖关系和禁用自动升级,提高了实验的可重复性,使得研究结果更加可靠。此外,简化的训练环境使得大规模强化学习成为可能。
关键设计:论文使用了Qwen3-32B作为基础模型,并采用GPT-4.1生成的代码修复轨迹进行监督微调。在强化学习阶段,具体使用的算法和奖励函数等细节未明确给出,但强调了匹配训练-测试环境的重要性。论文还探索了“思考模式”对模型性能的影响,但实验结果表明其效果并不理想。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过GPT-4.1轨迹蒸馏得到的SFT模型(Qwen3-32B)性能与GPT-4.1相当,但模型规模缩小了56倍。在匹配的训练-测试条件下,强化学习在SFT模型的基础上进一步提升了7-20%的绝对收益。然而,模型在跨环境泛化方面表现不佳,强调了训练和测试环境匹配的重要性。
🎯 应用场景
该研究成果可应用于软件开发和维护领域,帮助开发者自动修复代码中的错误,提高开发效率和软件质量。通过构建可靠的代码修复Agent,可以减少人工调试和修复代码的时间和成本,并降低软件缺陷带来的风险。未来,该技术有望应用于大规模软件系统的自动化维护和演进。
📄 摘要(原文)
We tackle the challenge of training reliable code-fixing agents in real repositories, where complex builds and shifting dependencies make evaluation unstable. We developed a verifiable pipeline with success defined as post-fix build validation and improved reproducibility across ~1K real issues by pinning dependencies and disabling automatic upgrades. Building on this, we introduced a scalable simplified pipeline for large-scale reinforcement learning (RL). Using this setup, we supervised fine-tuned Qwen3-32B in the full pipeline and applied RL on top of the SFT model in the simplified environment. The SFT model distilled from GPT-4.1 trajectories performs on par while being 56x smaller, and RL added 7-20% absolute gains under matched train-test conditions. "Thinking mode" was on par or worse in our experiments. Both SFT and RL models failed to generalize across environments, highlighting the importance of matching train-test environments for building reliable real-world code-fixing agents.