Parallel Sampling from Masked Diffusion Models via Conditional Independence Testing
作者: Iskander Azangulov, Teodora Pandeva, Niranjani Prasad, Javier Zazo, Sushrut Karmalkar
分类: cs.LG, cs.CL
发布日期: 2025-10-24
💡 一句话要点
提出PUNT,通过条件独立性测试加速Masked Diffusion Models的并行采样。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: Masked Diffusion Model 并行采样 条件独立性测试 文本生成 无训练采样
📋 核心要点
- 自回归模型生成文本速度慢,Masked Diffusion Models虽可并行采样,但需平衡token独立性和高置信度。
- PUNT通过条件独立性测试识别token依赖,移除低置信度token,生成满足独立性和置信度标准的索引集。
- 实验表明,PUNT在长文本生成中,相比其他基线方法,准确率提升高达16%,且对超参数不敏感。
📝 摘要(中文)
Masked diffusion models (MDMs) 为离散文本生成提供了一种引人注目的替代方案,相较于自回归模型 (ARMs),MDMs 能够实现并行 token 采样,而非顺序的、从左到右的生成,这意味着潜在的更快推理速度。然而,有效的并行采样面临两个相互竞争的要求:(i) 同时更新的 token 必须条件独立,以及 (ii) 更新应优先考虑高置信度的预测。这些目标相互冲突,因为高置信度的预测通常聚集在一起并相互依赖,从而提供了并行更新的机会。我们提出 PUNT,一种与模型无关的采样器,用于调和这种权衡。我们的方法识别 token 依赖性并从冲突组中删除置信度较低的 token。这产生了满足独立性和置信度标准的 unmasking 索引集。我们的方法通过近似条件独立性测试确保改进的并行 unmasking。我们的实验表明,与其他强大的无训练基线相比,PUNT 在准确性和计算之间提供了卓越的权衡,尤其是在生成较长序列时。在 IFEval 基准测试中,它比包括顺序生成(逐个)在内的基线方法实现了高达 16% 的更高准确率。这些增益在不同的超参数值中保持不变,从而减轻了对脆弱的超参数调整的需求。此外,我们观察到 PUNT 诱导了一种新兴的分层生成策略,模型首先建立高层段落结构,然后再进行局部细化,这表明了一种类似规划的生成过程,有助于强大的对齐性能。
🔬 方法详解
问题定义:论文旨在解决Masked Diffusion Models在并行采样时,如何平衡同时更新token的条件独立性以及优先更新高置信度预测这两个相互冲突的需求。现有方法要么牺牲并行性,采用自回归方式;要么忽略token之间的依赖关系,导致生成质量下降。
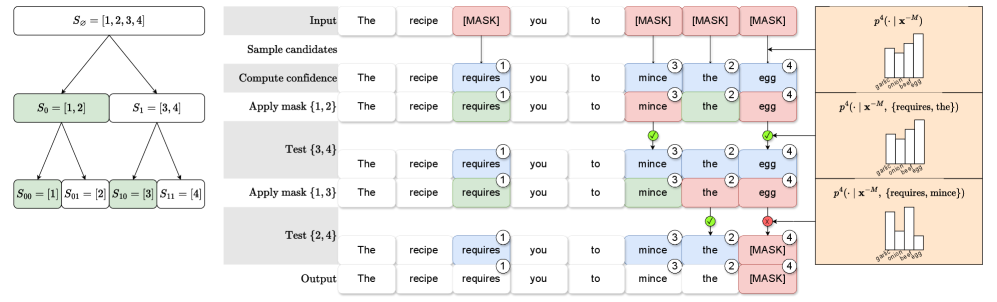
核心思路:论文的核心思路是通过近似条件独立性测试,识别token之间的依赖关系,并从相互依赖的token组中移除置信度较低的token,从而生成一组既满足条件独立性,又包含高置信度token的索引集合,用于并行unmasking。这样既能保证生成质量,又能提升采样速度。
技术框架:PUNT采样器的整体流程如下:1. 使用Masked Diffusion Model预测所有被mask token的概率分布;2. 根据预测概率计算每个token的置信度;3. 使用近似条件独立性测试,识别token之间的依赖关系,构建依赖图;4. 从依赖图中移除置信度较低的token,得到一组独立的token集合;5. unmask这些token,并重复上述步骤,直到生成完整的序列。
关键创新:PUNT的关键创新在于提出了一种基于近似条件独立性测试的并行采样方法,能够在保证生成质量的前提下,充分利用Masked Diffusion Models的并行计算能力。与现有方法相比,PUNT不需要额外的训练,可以直接应用于各种Masked Diffusion Models。
关键设计:PUNT的关键设计包括:1. 使用KL散度或JS散度等指标来衡量token之间的条件独立性;2. 使用贪心算法或图算法从依赖图中移除token,以最大化unmask token的数量;3. 使用温度系数来调整预测概率的分布,从而控制生成的多样性。
🖼️ 关键图片
📊 实验亮点
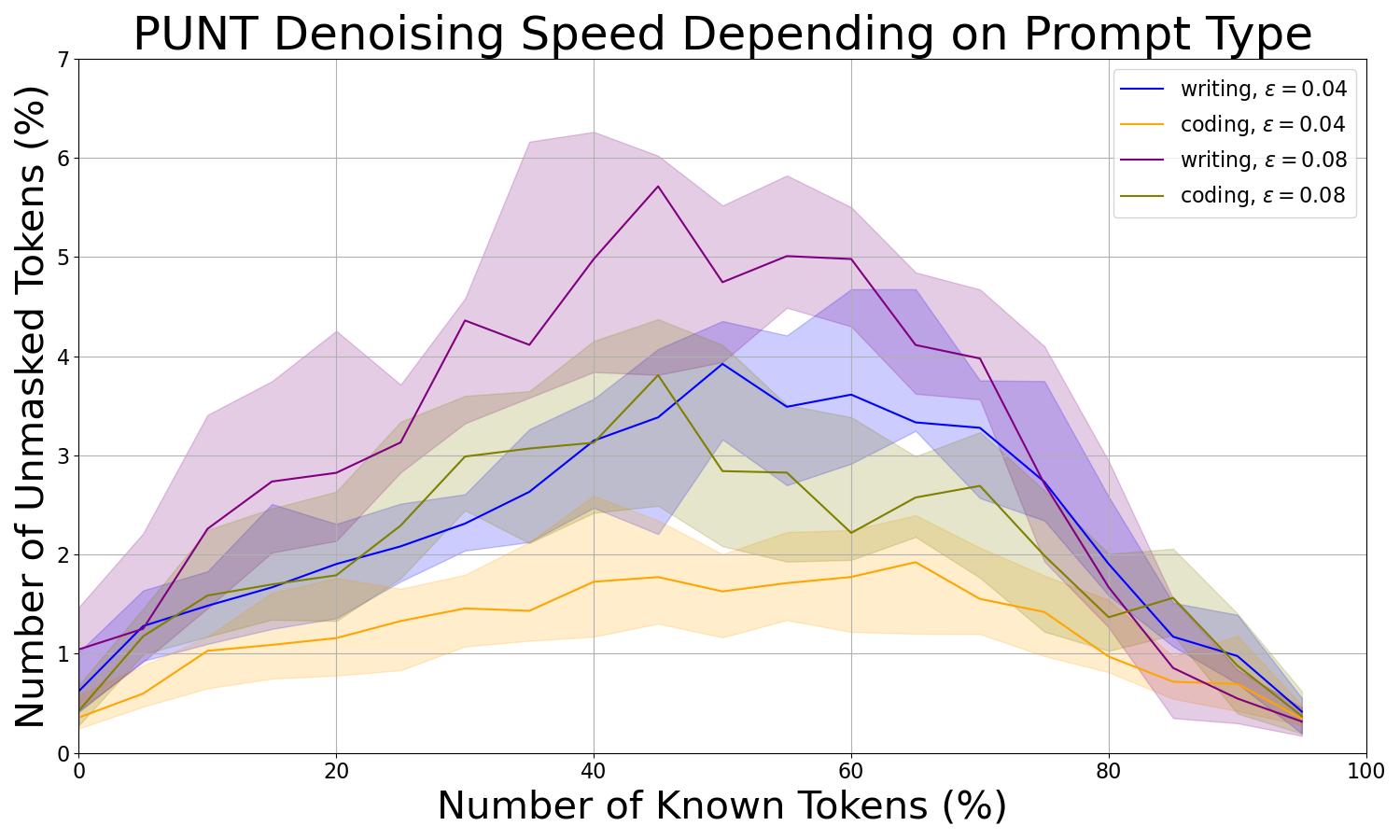
实验结果表明,PUNT在IFEval基准测试中,相比于其他无训练基线方法,包括顺序生成方法,实现了高达16%的准确率提升。此外,PUNT的性能对超参数不敏感,降低了调参的难度。PUNT还展现出一种新兴的分层生成策略,先建立高层段落结构,再进行局部细化。
🎯 应用场景
PUNT可应用于各种需要快速文本生成的场景,如机器翻译、文本摘要、对话生成等。其并行采样特性尤其适用于对实时性要求较高的应用。此外,PUNT诱导的分层生成策略,有助于生成更符合人类语言习惯的长文本,提升用户体验。
📄 摘要(原文)
Masked diffusion models (MDMs) offer a compelling alternative to autoregressive models (ARMs) for discrete text generation because they enable parallel token sampling, rather than sequential, left-to-right generation. This means potentially much faster inference. However, effective parallel sampling faces two competing requirements: (i) simultaneously updated tokens must be conditionally independent, and (ii) updates should prioritise high-confidence predictions. These goals conflict because high-confidence predictions often cluster and depend on each other, opportunities for parallel updates. We present PUNT, a model-agnostic sampler that reconciles this trade-off. Our method identifies token dependencies and removes lower-confidence tokens from conflicting groups. This produces sets of indices for unmasking that satisfy both independence and confidence criteria. Our approach ensures improved parallel unmasking through approximate conditional independence testing. Our experiments show that PUNT delivers a superior trade-off between accuracy and compute when compared to other strong training-free baselines, especially for generation of longer sequences. On the IFEval benchmark, it achieves up to 16\% higher accuracy over baseline methods, including sequential generation (one-by-one). These gains hold across different values of hyperparameters, mitigating the need for brittle hyperparameter tuning. Moreover, we observe that PUNT induces an emergent hierarchical generation strategy, where the model first establishes high-level paragraph structure before local refinement, suggesting a planning-like generation process that contributes to strong alignment performance.