Few-Shot Knowledge Distillation of LLMs With Counterfactual Explanations
作者: Faisal Hamman, Pasan Dissanayake, Yanjun Fu, Sanghamitra Dutta
分类: cs.LG, cs.AI, cs.CL, cs.CY, stat.ML
发布日期: 2025-10-24
备注: NeurIPS 2025
💡 一句话要点
提出基于反事实解释的蒸馏方法CoD,用于少样本场景下LLM的知识蒸馏。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 少样本学习 反事实解释 大型语言模型 模型压缩
📋 核心要点
- 现有任务感知的知识蒸馏方法依赖大量数据,这在许多实际场景中是不可行的。
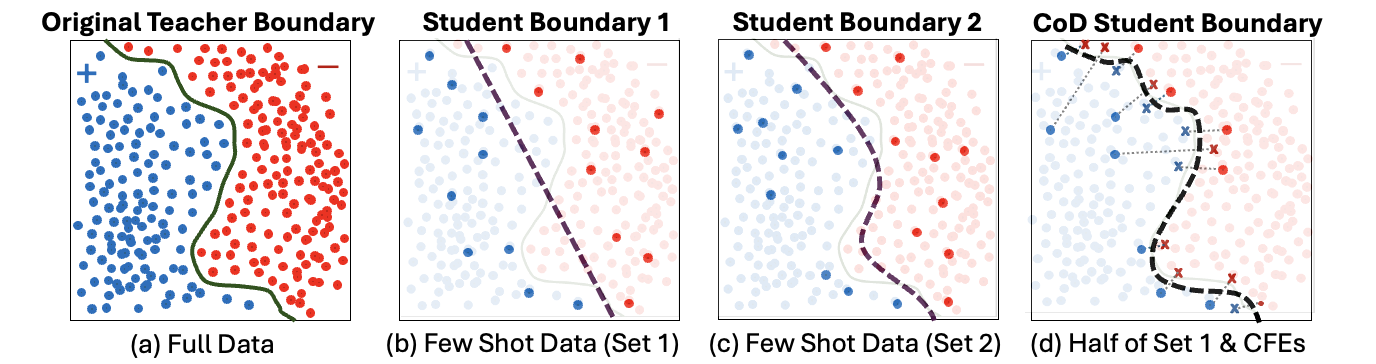
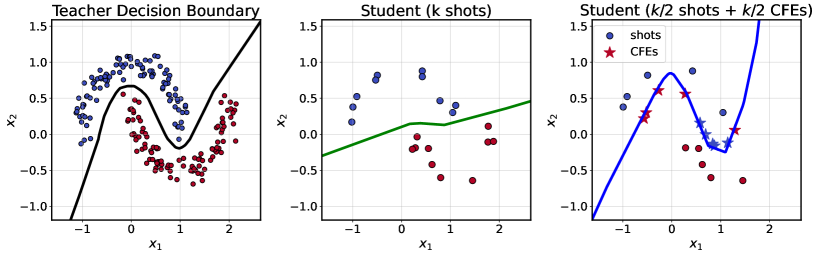
- 论文提出CoD方法,通过注入反事实解释(CFE)来更精确地映射教师模型的决策边界,减少样本需求。
- 实验表明,CoD在少样本场景下优于标准蒸馏方法,仅使用一半样本即可提高性能。
📝 摘要(中文)
知识蒸馏是一种有前景的方法,可以将复杂教师模型的能力转移到更小、资源效率更高的学生模型,尤其是在任务相关的场景中。然而,现有的任务相关蒸馏方法通常需要大量数据,而在许多实际场景中,这些数据可能不可用或获取成本高昂。本文通过引入一种名为反事实解释注入蒸馏(Counterfactual-explanation-infused Distillation CoD)的新策略来解决这一挑战,该策略通过系统地注入反事实解释来进行少样本任务相关的知识蒸馏。反事实解释(CFE)是指可以用最小扰动翻转教师模型输出预测的输入。我们的策略CoD利用这些CFE来精确地映射教师的决策边界,且只需要显著更少的样本。我们从统计和几何角度提供了理论保证,以证明CFE在蒸馏中的作用。我们用数学方法表明,CFE可以通过提供教师决策边界附近更具信息量的示例来改善参数估计。我们还推导了几何方面的见解,即CFE如何有效地充当知识探针,帮助学生比标准数据更有效地模仿教师的决策边界。我们跨各种数据集和LLM进行了实验,表明CoD在少样本情况下(低至8-512个样本)优于标准蒸馏方法。值得注意的是,CoD仅使用基线方法所用原始样本的一半,并将其与相应的CFE配对,仍然可以提高性能。
🔬 方法详解
问题定义:现有任务相关的知识蒸馏方法需要大量的训练数据,这在数据稀缺或获取成本高的场景下成为瓶颈。如何利用有限的数据,有效地将大型语言模型(LLM)的知识迁移到小型模型,是本研究要解决的核心问题。现有方法难以在少样本情况下精确模拟教师模型的决策边界。
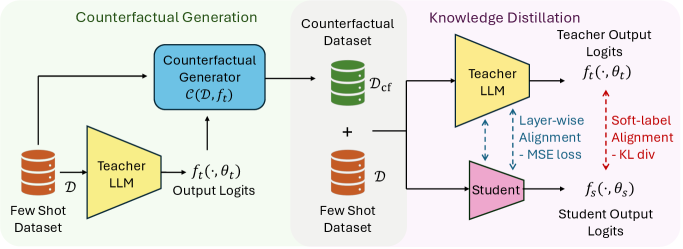
核心思路:论文的核心思路是利用反事实解释(CFE)来增强知识蒸馏过程。CFE能够以最小的扰动改变教师模型的预测结果,因此包含了教师模型决策边界的关键信息。通过将CFE与原始数据结合,可以更有效地训练学生模型,使其更好地逼近教师模型的决策边界。
技术框架:CoD方法的技术框架主要包含以下几个步骤:1) 从原始数据集中选择一部分样本。2) 为每个选定的样本生成对应的反事实解释(CFE)。3) 使用原始样本和对应的CFE作为训练数据,对学生模型进行知识蒸馏。蒸馏过程中,学生模型的目标是模仿教师模型在原始样本和CFE上的预测结果。
关键创新:CoD方法的关键创新在于利用反事实解释来指导知识蒸馏过程。与传统的知识蒸馏方法相比,CoD方法能够更有效地利用有限的数据,从而在少样本情况下取得更好的性能。通过CFE,模型能够关注到决策边界附近的关键样本,从而加速学习过程。
关键设计:CoD方法的关键设计包括:1) CFE的生成方式:论文中可能使用了特定的算法来生成CFE,例如基于梯度的方法或对抗攻击的方法。2) 损失函数的设计:损失函数需要同时考虑学生模型在原始样本和CFE上的预测结果,并鼓励学生模型模仿教师模型的行为。3) 样本选择策略:如何选择用于生成CFE的样本也会影响最终的蒸馏效果。论文可能采用了某种主动学习策略来选择最具信息量的样本。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CoD方法在少样本情况下显著优于标准蒸馏方法。在某些数据集上,CoD仅使用基线方法一半的样本(配以相应的CFE),就能取得更好的性能。例如,在特定任务上,CoD使用8-512个样本即可超越使用更多样本的标准蒸馏方法。
🎯 应用场景
该研究成果可应用于资源受限的边缘设备或移动设备上部署轻量级LLM,例如在智能手机上运行定制化的问答系统或文本生成模型。此外,在数据隐私敏感的场景下,该方法可以通过少量样本实现知识迁移,避免直接暴露大量原始数据,具有重要的应用价值。
📄 摘要(原文)
Knowledge distillation is a promising approach to transfer capabilities from complex teacher models to smaller, resource-efficient student models that can be deployed easily, particularly in task-aware scenarios. However, existing methods of task-aware distillation typically require substantial quantities of data which may be unavailable or expensive to obtain in many practical scenarios. In this paper, we address this challenge by introducing a novel strategy called Counterfactual-explanation-infused Distillation CoD for few-shot task-aware knowledge distillation by systematically infusing counterfactual explanations. Counterfactual explanations (CFEs) refer to inputs that can flip the output prediction of the teacher model with minimum perturbation. Our strategy CoD leverages these CFEs to precisely map the teacher's decision boundary with significantly fewer samples. We provide theoretical guarantees for motivating the role of CFEs in distillation, from both statistical and geometric perspectives. We mathematically show that CFEs can improve parameter estimation by providing more informative examples near the teacher's decision boundary. We also derive geometric insights on how CFEs effectively act as knowledge probes, helping the students mimic the teacher's decision boundaries more effectively than standard data. We perform experiments across various datasets and LLMs to show that CoD outperforms standard distillation approaches in few-shot regimes (as low as 8-512 samples). Notably, CoD only uses half of the original samples used by the baselines, paired with their corresponding CFEs and still improves performance.