Safety Assessment in Reinforcement Learning via Model Predictive Control
作者: Jeff Pflueger, Michael Everett
分类: cs.LG, cs.RO
发布日期: 2025-10-23
备注: 7 pages, 4 figures
💡 一句话要点
提出基于模型预测控制的强化学习安全评估方法,保障训练过程安全性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 安全评估 模型预测控制 路径积分控制 黑盒动力学
📋 核心要点
- 现有强化学习方法缺乏形式化的安全保证,且依赖于对安全规范的详细了解,限制了其在安全关键领域的应用。
- 该论文利用可逆性作为防止安全问题的手段,通过模型预测路径积分控制来评估学习策略提出的动作的安全性。
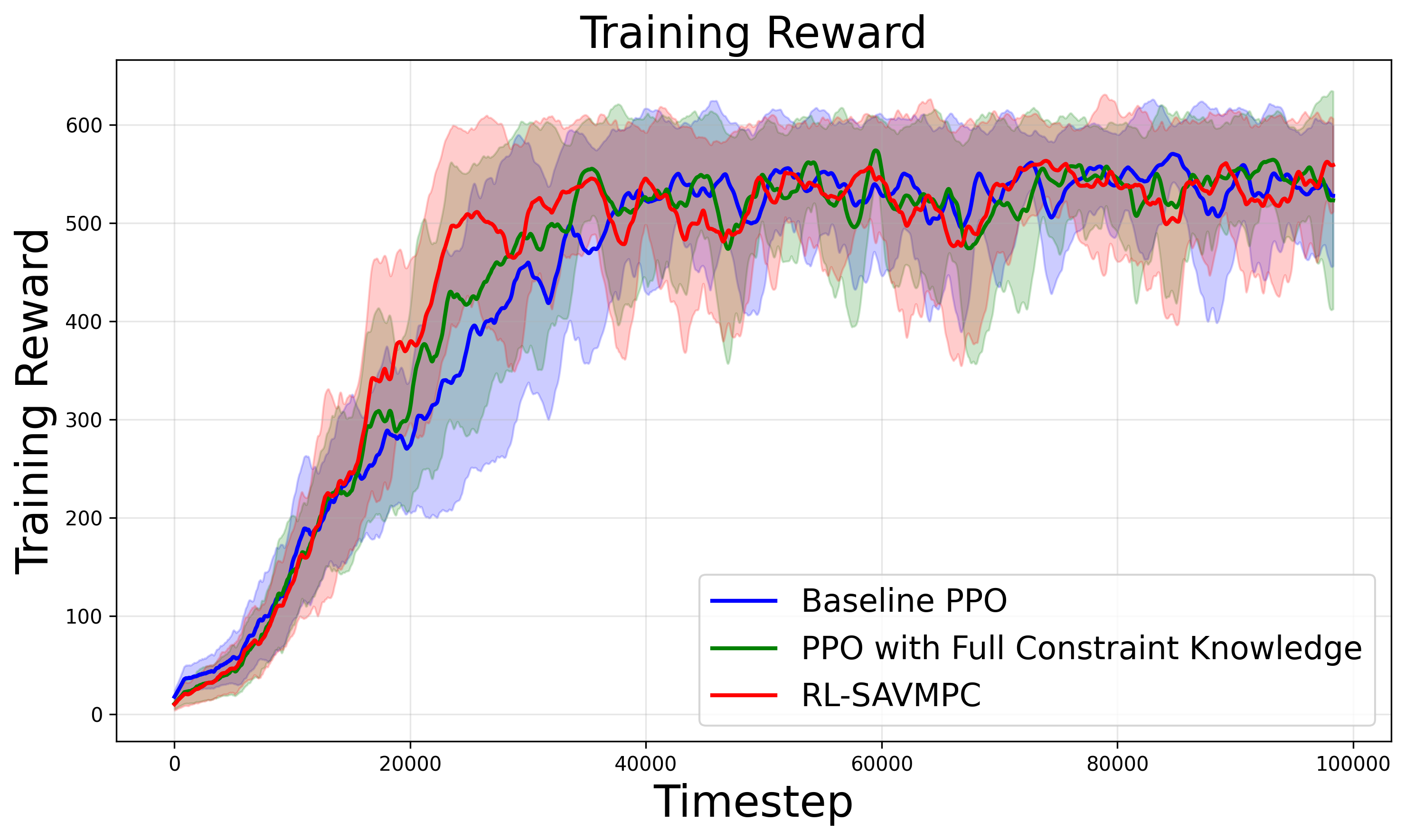
- 实验结果表明,该算法能够在保证安全性的前提下,实现与基线PPO方法相当的训练进度。
📝 摘要(中文)
无模型的强化学习方法在控制领域展现出潜力,但通常缺乏形式化的安全保证。现有的安全防护方法往往依赖于对安全规范的详细了解。本文提出了一种新思路,即许多难以明确指定的安全问题可以通过不变性来描述。因此,本文提出利用可逆性来防止训练过程中的这些安全问题。该方法使用模型预测路径积分控制来检查学习策略提出的动作的安全性。该方法的一个关键优势是,它只需要查询黑盒动力学模型,而不需要显式地了解动力学或安全约束。实验结果表明,所提出的算法成功地在所有不安全动作发生前中止,同时实现了与允许违反安全性的基线PPO方法相当的训练进度。
🔬 方法详解
问题定义:强化学习在控制任务中面临安全问题,尤其是在安全规范难以明确指定的情况下。现有方法要么依赖于精确的动力学模型和安全约束,要么缺乏形式化的安全保证,导致在实际应用中存在潜在风险。因此,如何在不依赖精确模型和安全约束的情况下,保证强化学习训练过程的安全性是一个关键问题。
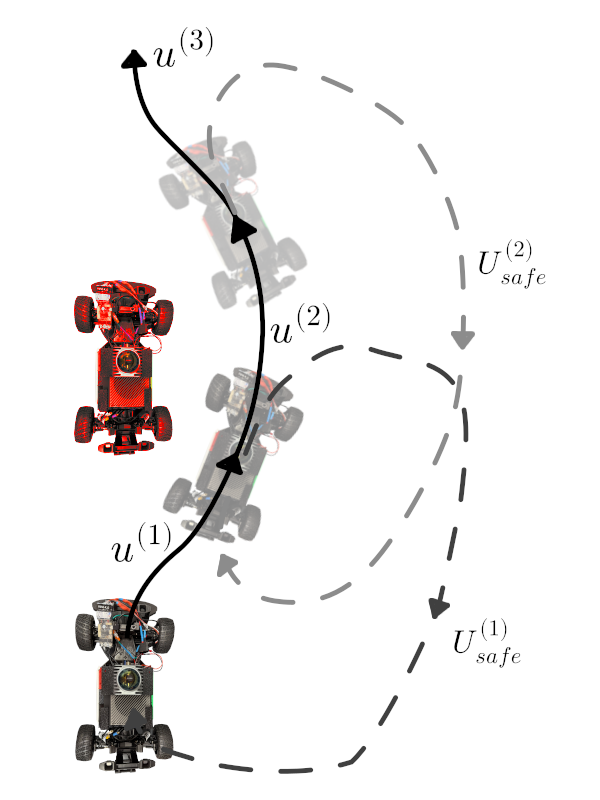
核心思路:论文的核心思路是利用“可逆性”来定义安全。作者认为,许多难以明确指定的安全问题可以通过系统状态的不变性来描述。具体来说,如果一个动作会导致系统进入不可逆的状态(例如,碰撞),那么这个动作就是不安全的。通过检测动作是否会导致不可逆的状态,可以在训练过程中避免不安全行为的发生。
技术框架:该方法的核心是一个基于模型预测路径积分控制(Model Predictive Path Integral Control, MPPI)的安全评估模块。在强化学习训练过程中,当智能体根据学习到的策略提出一个动作时,该动作首先会被送入MPPI模块进行安全评估。MPPI模块通过查询黑盒动力学模型,预测执行该动作后系统未来的状态轨迹。如果预测的轨迹中存在不安全的状态(例如,碰撞),则MPPI模块会拒绝该动作,并选择一个更安全的动作来执行。
关键创新:该方法最重要的创新点在于,它不需要显式地了解动力学模型或安全约束。传统的安全强化学习方法通常需要精确的动力学模型和安全约束,这在实际应用中往往难以获得。该方法只需要能够查询黑盒动力学模型,就可以进行安全评估,大大降低了对环境信息的依赖。此外,利用可逆性作为安全性的度量标准,避免了对安全规范进行显式建模的困难。
关键设计:MPPI模块的关键参数包括预测步长、采样数量和成本函数。预测步长决定了MPPI模块能够预测多远的未来状态。采样数量决定了MPPI模块能够探索多少不同的动作序列。成本函数用于评估每个动作序列的安全性,通常包括对不安全状态的惩罚项。论文中具体使用的成本函数和参数设置可能需要参考原文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够在保证安全性的前提下,实现与基线PPO方法相当的训练进度。具体来说,该方法成功地在所有不安全动作发生前中止,避免了智能体在训练过程中发生碰撞等危险行为。同时,该方法并没有显著降低智能体的学习效率,使其能够快速学习到最优策略。
🎯 应用场景
该研究成果可应用于各种安全关键的强化学习任务中,例如自动驾驶、机器人控制、航空航天等领域。通过在训练过程中引入安全评估机制,可以有效避免智能体在实际环境中发生危险行为,提高系统的可靠性和安全性。该方法尤其适用于动力学模型未知或难以精确建模的复杂系统。
📄 摘要(原文)
Model-free reinforcement learning approaches are promising for control but typically lack formal safety guarantees. Existing methods to shield or otherwise provide these guarantees often rely on detailed knowledge of the safety specifications. Instead, this work's insight is that many difficult-to-specify safety issues are best characterized by invariance. Accordingly, we propose to leverage reversibility as a method for preventing these safety issues throughout the training process. Our method uses model-predictive path integral control to check the safety of an action proposed by a learned policy throughout training. A key advantage of this approach is that it only requires the ability to query the black-box dynamics, not explicit knowledge of the dynamics or safety constraints. Experimental results demonstrate that the proposed algorithm successfully aborts before all unsafe actions, while still achieving comparable training progress to a baseline PPO approach that is allowed to violate safety.