GAPO: Robust Advantage Estimation for Real-World Code LLMs
作者: Jianqing Zhang, Zhezheng Hao, Wei Xia, Hande Dong, Hong Wang, Chenxing Wei, Yuyan Zhou, Yubin Qi, Qiang Lin, Jian Cao
分类: cs.LG, cs.AI
发布日期: 2025-10-22 (更新: 2026-01-08)
🔗 代码/项目: GITHUB
💡 一句话要点
提出GAPO,通过鲁棒优势估计提升代码LLM在真实场景下的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码LLM 强化学习 优势估计 噪声鲁棒性 策略优化
📋 核心要点
- 真实代码编辑场景中,奖励分布倾斜且噪声大,导致现有GRPO等方法优势估计失真,影响模型性能。
- GAPO自适应地为每个prompt寻找最高信噪比区间,并用该区间中位数作为自适应Q值,降低噪声影响。
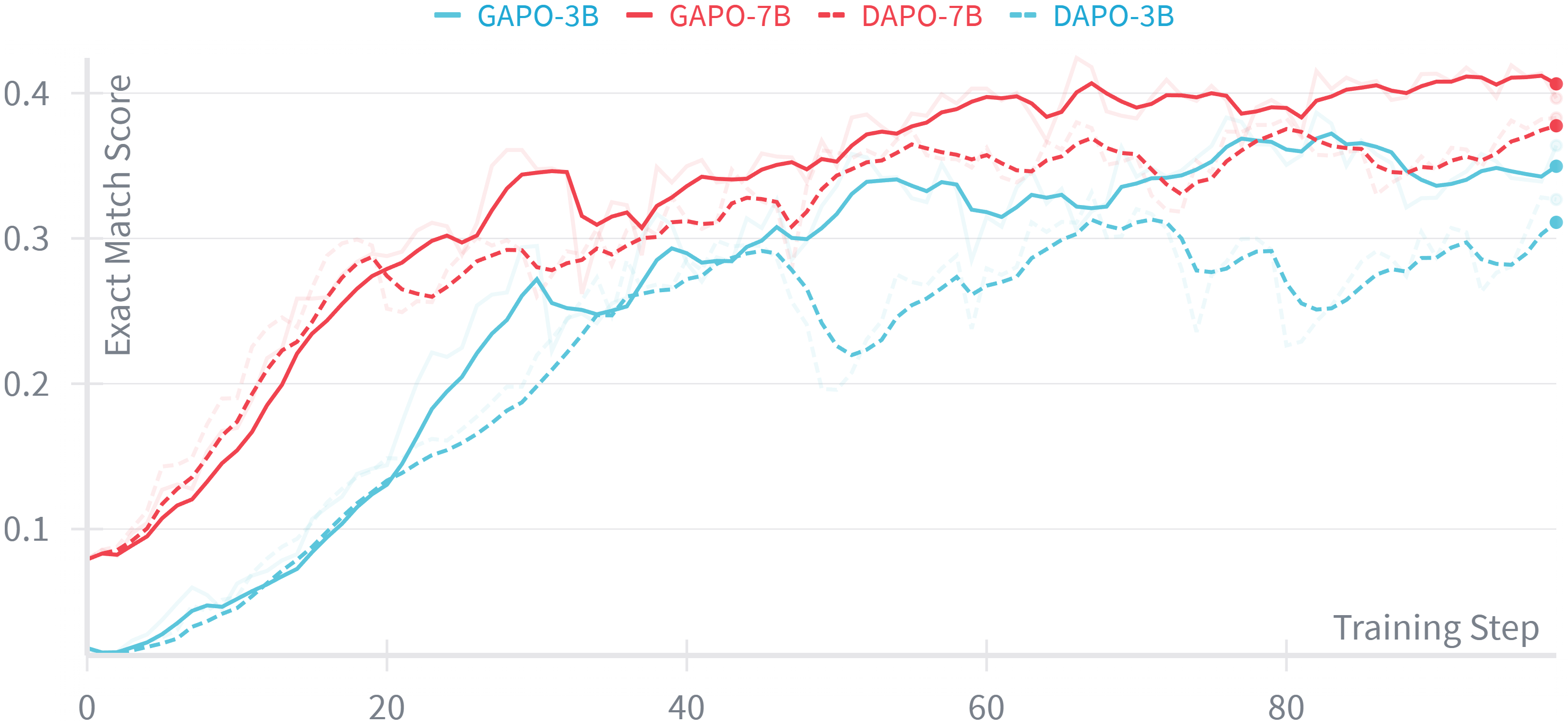
- 实验表明,GAPO在多个LLM上显著优于GRPO和DAPO,同时降低了裁剪率并提高了GPU吞吐量。
📝 摘要(中文)
强化学习被广泛应用于代码编辑中大型语言模型(LLM)的后训练,其中GRPO等组相对方法因其无评论家和归一化优势估计而受欢迎。然而,在真实的code-editing场景中,奖励分布经常出现倾斜和不可预测的噪声,导致优势计算失真和rollout异常值增加。为了解决这个问题,我们提出了组自适应策略优化(GAPO),它自适应地找到每个prompt具有最高信噪比(SNR)的区间,并使用该区间的中位数作为自适应Q值,以代替优势计算中的组平均值,从而进一步减少噪声。这种自适应Q值能够鲁棒地处理rollout噪声,同时保持即插即用和高效。我们使用收集的大型数据集(包含51,844个真实、历史感知的代码编辑任务,涵盖10种编程语言)在九个指令调优的LLM(3B-14B)上评估GAPO。GAPO在领域内(ID)和领域外(OOD)的精确匹配方面,比GRPO及其变体DAPO分别提高了高达4.35和5.30,同时实现了更低的裁剪率和更高的GPU吞吐量。
🔬 方法详解
问题定义:论文旨在解决真实代码编辑场景下,由于奖励分布的噪声和倾斜,导致现有基于强化学习的LLM训练方法(如GRPO)的优势估计不准确的问题。现有方法的痛点在于对噪声敏感,容易受到异常值的影响,从而导致策略优化不稳定。
核心思路:论文的核心思路是自适应地估计每个prompt的Q值,以减少噪声的影响。具体来说,对于每个prompt,算法会寻找一个具有最高信噪比(SNR)的奖励区间,并使用该区间的中位数作为Q值的估计。这样可以有效地过滤掉异常值,并提供更鲁棒的优势估计。
技术框架:GAPO的整体框架仍然是基于强化学习的策略优化。主要流程如下: 1. 使用LLM生成代码编辑的多个rollout。 2. 计算每个rollout的奖励。 3. 对于每个prompt,自适应地选择具有最高SNR的奖励区间,并计算该区间的中位数作为Q值。 4. 使用计算得到的Q值来估计优势函数。 5. 使用优势函数来更新LLM的策略。
关键创新:GAPO的关键创新在于自适应Q值的估计方法。与传统的GRPO方法使用组平均值作为Q值不同,GAPO使用具有最高SNR的奖励区间的中位数。这种方法能够更有效地处理噪声和异常值,从而提高策略优化的稳定性。
关键设计:GAPO的关键设计包括: 1. SNR计算:论文定义了SNR的计算方法,用于评估不同奖励区间的质量。具体公式未知,但其目标是找到一个既包含较高奖励,又具有较低方差的区间。 2. 自适应区间选择:论文提出了一种算法,用于自适应地搜索具有最高SNR的奖励区间。具体搜索策略未知。 3. 中位数计算:选择的区间的中位数被用作Q值的估计。中位数对异常值具有较强的鲁棒性。
🖼️ 关键图片


📊 实验亮点
GAPO在包含51,844个真实代码编辑任务的大型数据集上进行了评估,涵盖10种编程语言。实验结果表明,GAPO在领域内(ID)和领域外(OOD)的精确匹配方面,比GRPO及其变体DAPO分别提高了高达4.35和5.30。此外,GAPO还实现了更低的裁剪率和更高的GPU吞吐量,表明其具有更好的训练效率和稳定性。
🎯 应用场景
GAPO可应用于各种代码相关的LLM的训练和优化,例如代码补全、代码修复、代码翻译等。该方法能够提高LLM在真实场景下的代码编辑能力,降低开发成本,提高软件质量。未来,该方法可以扩展到其他具有噪声和不确定性的强化学习任务中。
📄 摘要(原文)
Reinforcement learning (RL) is widely used for post-training large language models (LLMs) in code editing, where group-relative methods, such as GRPO, are popular due to their critic-free and normalized advantage estimation. However, in real-world code-editing scenarios, reward distributions are often skewed with unpredictable noise, leading to distorted advantage computation and increased rollout outliers. To address this issue, we propose Group Adaptive Policy Optimization (GAPO), which adaptively finds an interval with the highest SNR (Signal to Noise Ratio) per prompt and uses the median of that interval as an adaptive Q to replace the group mean in advantage calculation to reduce noise further. This adaptive Q robustly handles rollout noise while remaining plug-and-play and efficient. We evaluate GAPO on nine instruction-tuned LLMs (3B-14B) using a collected large dataset of 51,844 real-world, history-aware code-editing tasks spanning 10 programming languages. GAPO yields up to 4.35 in-domain (ID) and 5.30 out-of-domain (OOD) exact-match improvements over GRPO and its variant DAPO, while achieving lower clipping ratios and higher GPU throughput. Code: https://github.com/TsingZ0/verl-GAPO.