What Makes a Good Curriculum? Disentangling the Effects of Data Ordering on LLM Mathematical Reasoning
作者: Yaning Jia, Chunhui Zhang, Xingjian Diao, Xiangchi Yuan, Zhongyu Ouyang, Chiyu Ma, Soroush Vosoughi
分类: cs.LG, cs.AI
发布日期: 2025-10-21 (更新: 2025-10-24)
备注: 8 pages (main text) + 4 pages (appendix), 4 figures
💡 一句话要点
解耦数据排序对LLM数学推理的影响,探究有效课程学习策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 课程学习 大型语言模型 数学推理 数据排序 难度评估
📋 核心要点
- 现有课程学习方法在难度衡量和训练设置上存在差异,缺乏对不同策略效果的深入理解。
- 论文提出统一的离线评估框架,将课程难度解耦为五个维度,从而分析不同课程策略的影响。
- 实验表明,课程学习效果依赖于模型能力和任务复杂性,且不同难度样本增益不同。
📝 摘要(中文)
课程学习(CL),即按照从易到难的顺序组织训练数据,已成为提升大型语言模型(LLM)推理能力的常用策略。然而,现有研究采用不同的难度指标和训练设置,导致一些根本性问题仍未解决:课程学习何时有效?正向(从易到难)或反向(从难到易)哪个更好?答案是否取决于我们所衡量的指标?本文通过一个统一的离线评估框架来解决这些问题,该框架将课程难度分解为五个互补的维度:问题难度、模型惊讶度、置信度边际、预测不确定性和决策可变性。通过在Llama3.1-8B、Mistral-7B和Gemma3-4B上进行受控的数学推理基准测试后训练实验,我们发现:(i)没有一种课程策略是普遍占优的——正向与反向CL的相对有效性共同取决于模型能力和任务复杂性;(ii)即使在单个指标内,不同难度级别的样本也会根据任务需求产生不同的增益;(iii)与任务对齐的课程侧重于塑造模型的最终表示和泛化能力,而内部状态课程则调节内部状态,如置信度和不确定性。我们的发现挑战了通用课程策略的观念,并为跨模型和任务体系提供了可操作的指导,其中一些指标表明,优先考虑决策不确定性样本可以进一步提高学习效果。
🔬 方法详解
问题定义:现有课程学习方法在提升LLM推理能力时,缺乏统一的评估标准和理论指导。不同的难度指标和训练设置使得难以确定哪种课程策略(正向或反向)在何种情况下更有效。现有方法未能充分理解数据排序对模型内部状态和最终性能的影响。
核心思路:论文的核心思路是将课程难度解耦为多个维度,包括问题难度、模型惊讶度、置信度边际、预测不确定性和决策可变性。通过分析这些维度与模型性能之间的关系,可以更深入地理解不同课程策略的优势和劣势,从而为选择合适的课程策略提供指导。
技术框架:论文采用离线评估框架,首先使用不同的难度指标对训练数据进行排序,然后使用不同的课程策略(正向、反向等)对LLM进行后训练。在训练过程中,记录模型的内部状态(如置信度、不确定性),并在数学推理基准测试上评估模型的性能。通过分析不同课程策略对模型内部状态和性能的影响,从而评估课程策略的有效性。
关键创新:论文的关键创新在于提出了一个统一的、多维度的课程难度评估框架。该框架能够将课程难度分解为多个可解释的维度,从而更深入地理解课程学习的机制。此外,论文还发现,课程学习的效果依赖于模型能力和任务复杂性,没有一种课程策略是普遍占优的。
关键设计:论文的关键设计包括:(1) 定义了五个互补的课程难度维度;(2) 采用离线评估框架,避免了在线训练的复杂性;(3) 使用多个LLM(Llama3.1-8B、Mistral-7B和Gemma3-4B)进行实验,验证了结论的泛化性;(4) 在数学推理基准测试上评估模型的性能,确保了评估的可靠性。
🖼️ 关键图片

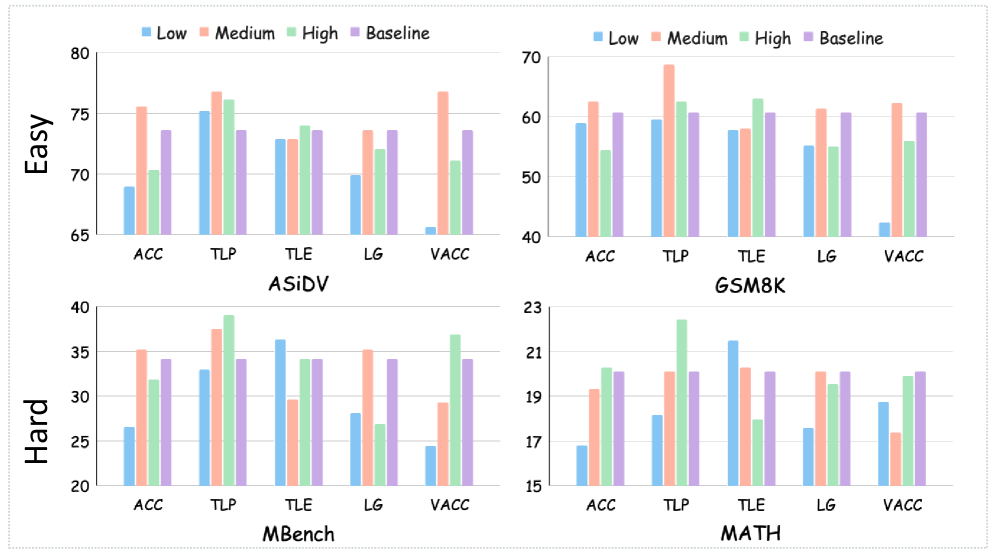

📊 实验亮点
实验结果表明,没有一种课程策略是普遍占优的,正向与反向CL的相对有效性取决于模型能力和任务复杂性。此外,论文还发现,优先考虑决策不确定性样本可以进一步提高学习效果。这些发现挑战了通用课程策略的观念,并为跨模型和任务体系提供了可操作的指导。
🎯 应用场景
该研究成果可应用于提升LLM在各种推理任务中的性能,例如数学推理、逻辑推理和常识推理。通过选择合适的课程策略,可以更有效地训练LLM,提高其解决复杂问题的能力。此外,该研究还可以为开发更有效的课程学习算法提供指导。
📄 摘要(原文)
Curriculum learning (CL) - ordering training data from easy to hard - has become a popular strategy for improving reasoning in large language models (LLMs). Yet prior work employs disparate difficulty metrics and training setups, leaving open fundamental questions: When does curriculum help? Which direction - forward or reverse - is better? And does the answer depend on what we measure? We address these questions through a unified offline evaluation framework that decomposes curriculum difficulty into five complementary dimensions: Problem Difficulty, Model Surprisal, Confidence Margin, Predictive Uncertainty, and Decision Variability. Through controlled post-training experiments on mathematical reasoning benchmarks with Llama3.1-8B, Mistral-7B, and Gemma3-4B, we find that (i) no curriculum strategy dominates universally - the relative effectiveness of forward versus reverse CL depends jointly on model capability and task complexity; (ii) even within a single metric, samples at different difficulty levels produce distinct gains depending on task demands; and (iii) task-aligned curricula focus on shaping the model's final representations and generalization, whereas inner-state curricula modulate internal states such as confidence and uncertainty. Our findings challenge the notion of a universal curriculum strategy and offer actionable guidance across model and task regimes, with some metrics indicating that prioritizing decision-uncertain samples can further enhance learning outcomes.