POLAR: Policy-based Layerwise Reinforcement Learning Method for Stealthy Backdoor Attacks in Federated Learning
作者: Kuai Yu, Xiaoyu Wu, Peishen Yan, Qingqian Yang, Linshan Jiang, Hao Wang, Yang Hua, Tao Song, Haibing Guan
分类: cs.LG
发布日期: 2025-10-21
💡 一句话要点
POLAR:提出基于策略梯度强化学习的联邦学习隐蔽后门攻击方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联邦学习 后门攻击 强化学习 策略梯度 隐蔽攻击 模型安全 对抗防御
📋 核心要点
- 现有联邦学习后门攻击方法依赖规则选择关键层,忽略层间关系,易被防御机制检测。
- POLAR采用强化学习动态学习攻击策略,通过策略梯度更新优化层选择后门关键层。
- 实验表明,POLAR在对抗多种先进防御机制时,性能优于现有攻击方法高达40%。
📝 摘要(中文)
联邦学习(FL)允许多个客户端在不暴露本地数据的情况下进行去中心化模型训练,但其分布式特性使其容易受到后门攻击。早期的FL后门攻击会修改整个模型,而最近的研究探索了后门关键(BC)层的概念,即通过毒化选定的有影响力的层来保持隐蔽性,同时实现高有效性。然而,现有的BC层方法依赖于基于规则的选择,没有考虑到层之间的相互关系,导致效果不佳,并且容易被先进的防御机制检测到。本文提出POLAR(基于策略的层级强化学习),这是第一个创造性地采用RL来解决分层后门攻击中BC层选择问题的流程。与其它常用的RL范式不同,POLAR是轻量级的,采用伯努利抽样。POLAR动态地学习攻击策略,使用基于后门成功率(BSR)改进的策略梯度更新来优化层选择。为了确保隐蔽性,我们引入了一个正则化约束,通过惩罚大的攻击足迹来限制修改层的数量。大量的实验表明,POLAR在对抗六种最先进的(SOTA)防御机制时,性能优于最新的攻击方法高达40%。
🔬 方法详解
问题定义:论文旨在解决联邦学习中后门攻击的隐蔽性和有效性问题。现有的后门攻击方法,特别是基于后门关键层(BC层)的方法,通常依赖于预定义的规则来选择需要投毒的层。这种选择方式忽略了层与层之间的相互依赖关系,导致攻击效果不佳,并且容易被防御机制检测到。因此,如何动态地、智能地选择合适的BC层,以在保证攻击成功率的同时,尽可能地降低攻击的暴露风险,是本论文要解决的核心问题。
核心思路:POLAR的核心思路是将BC层的选择问题建模为一个强化学习问题。通过强化学习,POLAR能够动态地学习一个攻击策略,该策略能够根据当前模型的状态,选择最合适的层进行投毒。这种基于策略的学习方式能够考虑到层与层之间的相互关系,从而提高攻击的成功率和隐蔽性。同时,为了保证隐蔽性,POLAR还引入了一个正则化约束,限制了被修改层的数量。
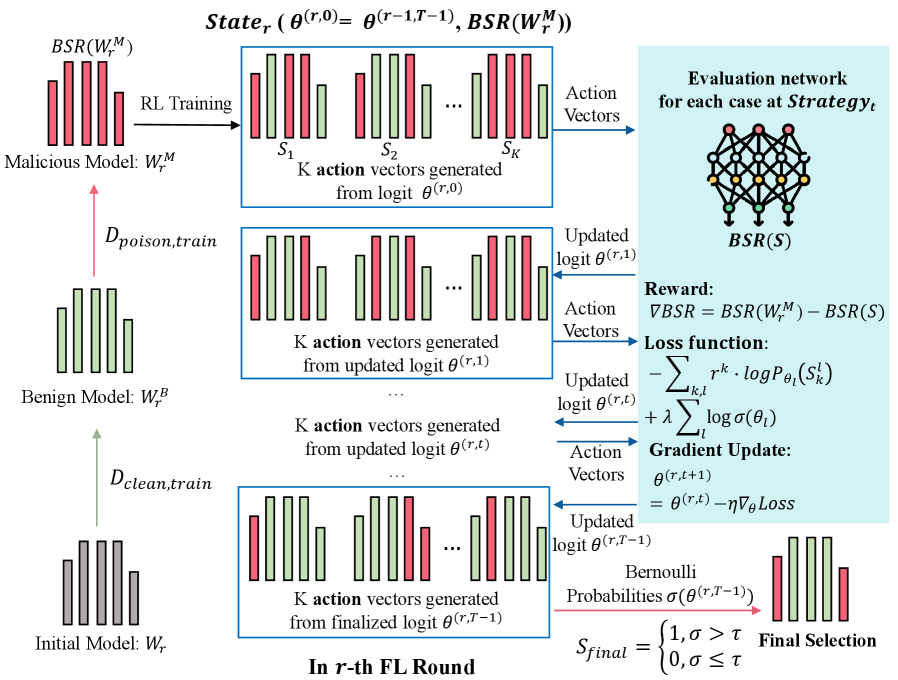
技术框架:POLAR的整体框架包括以下几个主要模块:1) 状态表示:将当前模型的层信息作为强化学习的状态输入。2) 策略网络:使用一个策略网络来学习攻击策略,该策略决定了哪些层应该被投毒。3) 奖励函数:根据后门攻击的成功率和修改层的数量来设计奖励函数,引导策略网络学习有效的攻击策略。4) 策略更新:使用策略梯度算法来更新策略网络,使其能够选择更合适的BC层。5) 正则化约束:引入一个正则化项,惩罚修改过多的层,以保证攻击的隐蔽性。
关键创新:POLAR的关键创新在于将强化学习引入到联邦学习的后门攻击中,并将其应用于BC层的选择问题。与传统的基于规则的选择方法相比,POLAR能够动态地学习攻击策略,考虑到层与层之间的相互关系,从而提高攻击的成功率和隐蔽性。此外,POLAR还引入了一个正则化约束,进一步提高了攻击的隐蔽性。
关键设计:POLAR采用伯努利分布进行采样,使得强化学习过程更加轻量级。奖励函数的设计至关重要,它需要平衡攻击的成功率和隐蔽性。论文中,奖励函数主要由两部分组成:后门成功率的提升和修改层数量的惩罚。策略网络可以使用各种常见的神经网络结构,如多层感知机或卷积神经网络。正则化约束可以通过在损失函数中添加一个L1或L2正则化项来实现。
🖼️ 关键图片

📊 实验亮点
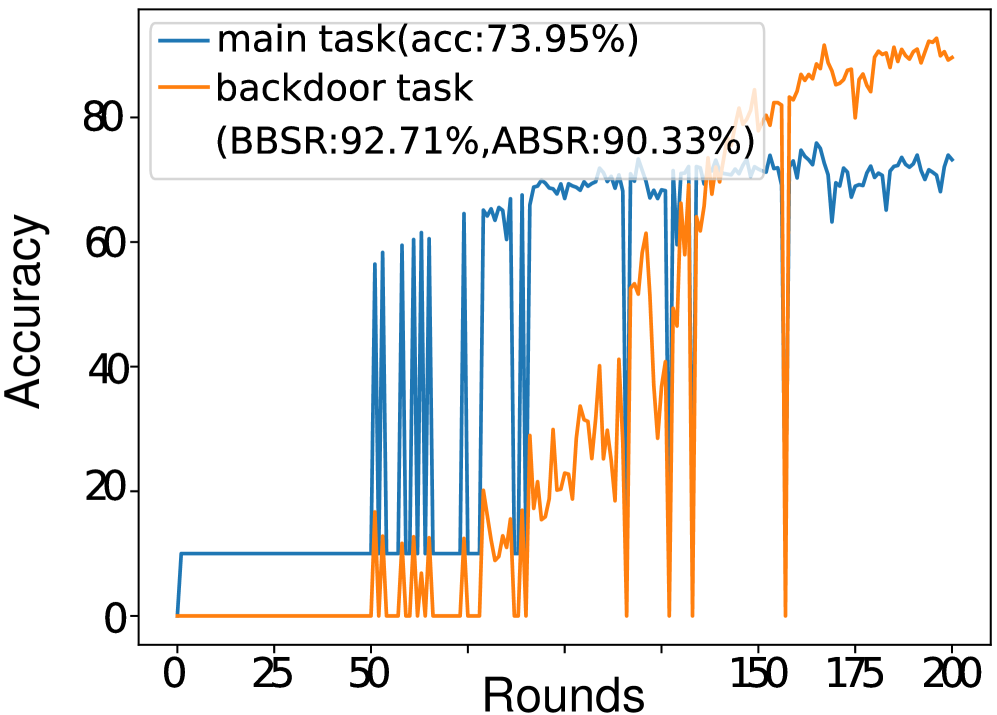
POLAR在六种最先进的防御机制下进行了广泛的实验,结果表明,POLAR的性能优于最新的攻击方法高达40%。这表明POLAR能够有效地绕过现有的防御机制,实现隐蔽且有效的后门攻击。实验结果还验证了POLAR的动态攻击策略学习方法的有效性,以及正则化约束对提高攻击隐蔽性的作用。
🎯 应用场景
POLAR的研究成果可以应用于评估和增强联邦学习系统的安全性。通过模拟POLAR攻击,可以发现联邦学习模型中的潜在漏洞,并开发相应的防御机制。此外,POLAR的动态攻击策略学习方法也可以推广到其他安全领域,例如对抗样本生成和恶意软件检测。该研究有助于提升联邦学习在实际应用中的可靠性和安全性,促进其在医疗、金融等敏感数据领域的广泛应用。
📄 摘要(原文)
Federated Learning (FL) enables decentralized model training across multiple clients without exposing local data, but its distributed feature makes it vulnerable to backdoor attacks. Despite early FL backdoor attacks modifying entire models, recent studies have explored the concept of backdoor-critical (BC) layers, which poison the chosen influential layers to maintain stealthiness while achieving high effectiveness. However, existing BC layers approaches rely on rule-based selection without consideration of the interrelations between layers, making them ineffective and prone to detection by advanced defenses. In this paper, we propose POLAR (POlicy-based LAyerwise Reinforcement learning), the first pipeline to creatively adopt RL to solve the BC layer selection problem in layer-wise backdoor attack. Different from other commonly used RL paradigm, POLAR is lightweight with Bernoulli sampling. POLAR dynamically learns an attack strategy, optimizing layer selection using policy gradient updates based on backdoor success rate (BSR) improvements. To ensure stealthiness, we introduce a regularization constraint that limits the number of modified layers by penalizing large attack footprints. Extensive experiments demonstrate that POLAR outperforms the latest attack methods by up to 40% against six state-of-the-art (SOTA) defenses.