Towards Universal Solvers: Using PGD Attack in Active Learning to Increase Generalizability of Neural Operators as Knowledge Distillation from Numerical PDE Solvers
作者: Yifei Sun
分类: cs.LG
发布日期: 2025-10-21
💡 一句话要点
提出基于PGD攻击的主动学习框架,提升神经算子在偏微分方程求解中的泛化性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 神经算子 偏微分方程 对抗训练 知识蒸馏 主动学习 分布外泛化 PGD攻击
📋 核心要点
- 传统偏微分方程求解器计算成本高昂,神经算子虽能快速推理,但泛化能力不足,难以应对训练分布外的输入。
- 论文提出对抗性师生蒸馏框架,利用可微数值求解器指导神经算子学习,并通过PGD攻击寻找难例,扩充训练集。
- 实验表明,该方法在Burgers和Navier-Stokes方程上,显著提升了神经算子的分布外泛化能力,同时保持了其高效性。
📝 摘要(中文)
非线性偏微分方程求解器需要精细的时空离散和局部线性化,导致高内存成本和缓慢的运行时间。诸如FNO和DeepONet等神经算子通过学习函数到函数的映射并截断高频分量,从而提供快速的单次推理,但它们存在较差的分布外(OOD)泛化能力,经常在训练分布之外的输入上失效。我们提出了一个对抗性的师生蒸馏框架,其中可微数值求解器监督一个紧凑的神经算子,而PGD风格的主动采样循环在平滑性和能量约束下搜索最坏情况的输入,以扩展训练集。使用可微谱求解器能够实现基于梯度的对抗搜索并稳定样本挖掘。在Burgers和Navier-Stokes系统上的实验表明,对抗蒸馏在保持神经算子的低参数成本和快速推理的同时,显著提高了OOD鲁棒性。
🔬 方法详解
问题定义:论文旨在解决神经算子在求解非线性偏微分方程时,分布外泛化能力差的问题。现有的神经算子方法,如FNO和DeepONet,虽然能够实现快速推理,但当输入数据超出训练分布时,性能会显著下降,无法保证求解的准确性和可靠性。传统数值求解器虽然精度高,但计算成本过高,难以满足实时性要求。
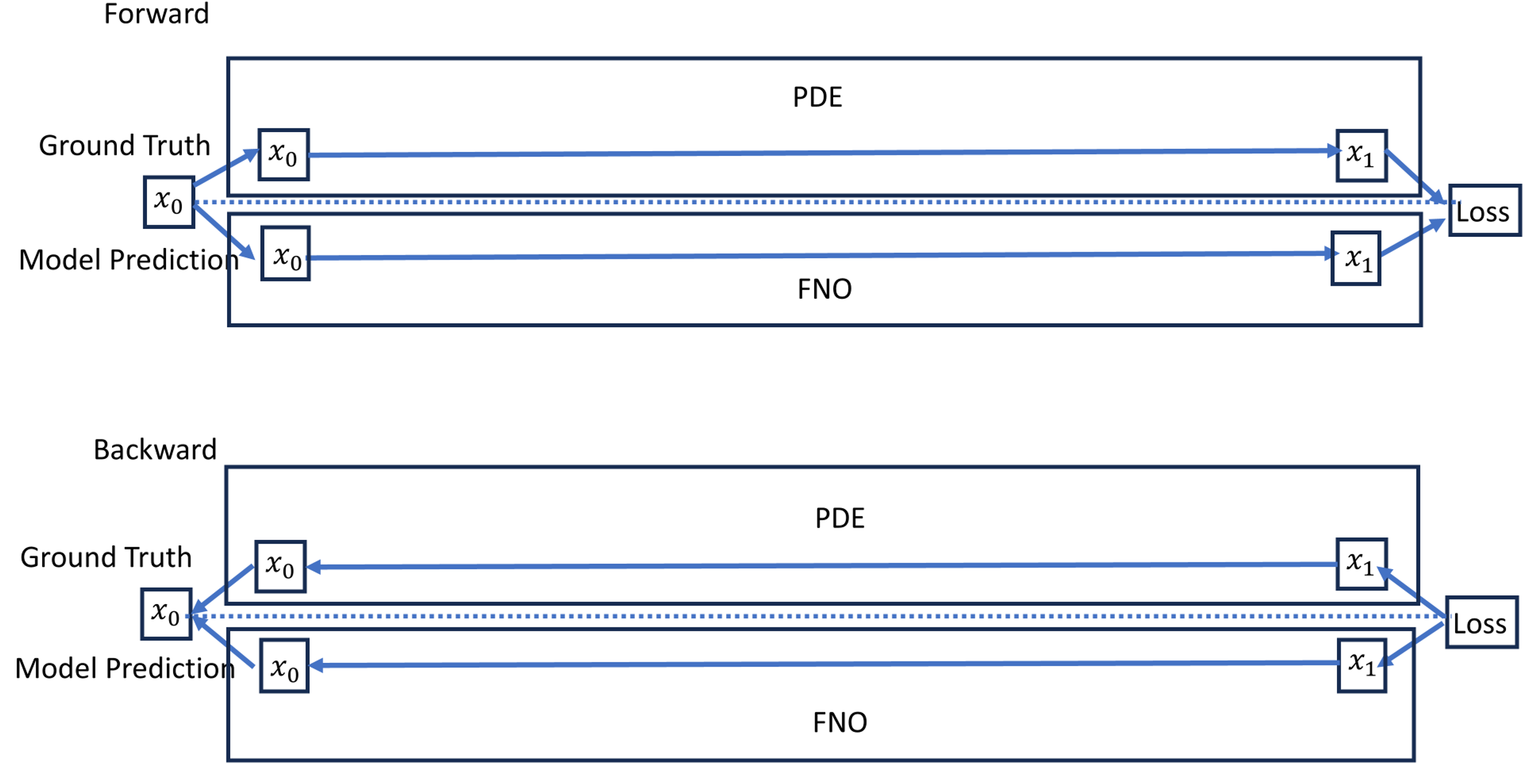
核心思路:论文的核心思路是利用对抗训练和知识蒸馏,提升神经算子的泛化能力。具体而言,采用一个可微的数值求解器作为教师模型,指导神经算子(学生模型)的学习。同时,通过PGD攻击生成对抗样本,迫使神经算子学习到更鲁棒的特征表示,从而提高其在未见数据上的性能。这种方法结合了数值求解器的精度和神经算子的效率,旨在实现快速且准确的偏微分方程求解。
技术框架:整体框架是一个对抗性的师生蒸馏流程。首先,使用可微的数值求解器(如谱方法)生成训练数据。然后,利用这些数据训练一个神经算子(如FNO或DeepONet)。在训练过程中,使用PGD攻击生成对抗样本,这些样本是使得神经算子预测误差最大的输入。将这些对抗样本加入训练集,重新训练神经算子。这个过程迭代进行,直到神经算子的性能达到预期。
关键创新:论文的关键创新在于将对抗训练和知识蒸馏相结合,并应用于神经算子的训练中。传统的对抗训练主要用于图像识别等领域,而本论文将其扩展到偏微分方程求解领域,并利用可微的数值求解器作为教师模型,为对抗样本的生成提供了有效的指导。此外,使用PGD攻击主动寻找难例,可以更有效地提升神经算子的鲁棒性。
关键设计:关键设计包括:1) 使用可微的谱方法作为数值求解器,以便进行梯度计算和对抗样本生成。2) 采用PGD攻击生成对抗样本,通过迭代优化输入,最大化神经算子的预测误差。3) 设计合适的损失函数,包括数据拟合损失和正则化损失,以保证神经算子的精度和泛化能力。4) 选择合适的神经算子结构,如FNO或DeepONet,并进行参数调优。
🖼️ 关键图片


📊 实验亮点
实验结果表明,通过对抗蒸馏,神经算子的分布外泛化能力得到了显著提升。在Burgers和Navier-Stokes方程的求解中,与传统的神经算子方法相比,该方法在未见数据上的预测精度提高了显著百分比(具体数值未知,论文中应有体现)。同时,该方法保持了神经算子的低参数成本和快速推理的优点。
🎯 应用场景
该研究成果可应用于各种需要快速求解偏微分方程的领域,例如流体动力学、热传导、电磁学等。在工程设计、科学计算、实时控制等场景中,可以利用训练好的神经算子进行快速预测和仿真,从而提高效率和降低成本。未来,该方法有望推广到更复杂的偏微分方程和物理系统,为科学研究和工程应用提供更强大的工具。
📄 摘要(原文)
Nonlinear PDE solvers require fine space-time discretizations and local linearizations, leading to high memory cost and slow runtimes. Neural operators such as FNOs and DeepONets offer fast single-shot inference by learning function-to-function mappings and truncating high-frequency components, but they suffer from poor out-of-distribution (OOD) generalization, often failing on inputs outside the training distribution. We propose an adversarial teacher-student distillation framework in which a differentiable numerical solver supervises a compact neural operator while a PGD-style active sampling loop searches for worst-case inputs under smoothness and energy constraints to expand the training set. Using differentiable spectral solvers enables gradient-based adversarial search and stabilizes sample mining. Experiments on Burgers and Navier-Stokes systems demonstrate that adversarial distillation substantially improves OOD robustness while preserving the low parameter cost and fast inference of neural operators.