Benchmarking On-Device Machine Learning on Apple Silicon with MLX
作者: Oluwaseun A. Ajayi, Ogundepo Odunayo
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-21
备注: 19 pages, 6 figures. Presented at the 6th Deep Learning Indaba (DLI 2024), Dakar, Senegal; non-archival presentation. Poster: https://storage.googleapis.com/indaba-public/Oluwaseun_Ajayi%20.pdf
💡 一句话要点
利用MLX框架,在Apple Silicon上高效部署Transformer模型,实现端侧机器学习加速。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 端侧机器学习 Apple Silicon MLX框架 Transformer模型 推理延迟
📋 核心要点
- 现有机器学习框架在Apple Silicon等端侧设备上部署大型模型时,性能受限,无法充分利用硬件加速能力。
- MLX框架旨在优化Apple Silicon上的机器学习计算,通过简化模型部署流程,提升端侧推理效率。
- 实验结果表明,MLX在Transformer模型推理方面表现出潜力,为Apple生态系统中的端侧ML应用提供了可能。
📝 摘要(中文)
大型语言模型(LLM)和机器学习的广泛应用激发了在笔记本电脑和手机等小型设备上部署这些模型的研究兴趣。这需要能够利用端侧硬件的框架和方法。MLX框架应运而生,它针对Apple Silicon设备上的机器学习(ML)计算进行了优化,从而简化了研究、实验和原型设计。本文对MLX进行了性能评估,重点关注Transformer模型的推理延迟。我们将MLX中不同Transformer架构实现的性能与Pytorch中的对应实现进行了比较。为此,我们创建了一个名为MLX-transformers的框架,该框架包含MLX中的不同Transformer实现,并下载Pytorch中的模型检查点并将其转换为MLX格式。通过利用Apple Silicon的先进架构和功能,MLX-Transformers可以直接执行来自Hugging Face的Transformer模型,无需在框架之间移植模型时通常需要的检查点转换。我们的研究在两台Apple Silicon Macbook设备上针对NVIDIA CUDA GPU对不同的Transformer模型进行了基准测试。具体来说,我们比较了具有相同参数大小和检查点的模型的推理延迟性能。我们评估了BERT、RoBERTa和XLM-RoBERTa模型的性能,并计划将未来的工作扩展到包括不同模态的模型,从而更全面地评估MLX的功能。结果突出了MLX在Apple生态系统中实现高效且更易于访问的端侧ML应用程序的潜力。
🔬 方法详解
问题定义:论文旨在解决在Apple Silicon设备上高效运行Transformer模型的问题。现有框架(如PyTorch)在端侧设备上的性能不足,无法充分利用Apple Silicon的硬件加速能力,导致推理延迟较高。此外,不同框架之间的模型转换过程也较为繁琐。
核心思路:论文的核心思路是利用MLX框架,该框架专门为Apple Silicon设计,能够更好地利用其硬件特性进行机器学习计算。通过优化模型结构和计算方式,降低推理延迟,提高端侧模型的运行效率。同时,MLX-transformers框架简化了模型转换流程,可以直接使用Hugging Face上的PyTorch模型。
技术框架:整体框架包括以下几个主要部分:1) MLX框架本身,负责模型的加载、运行和推理;2) MLX-transformers框架,用于管理和转换Transformer模型;3) Hugging Face模型仓库,提供预训练的PyTorch模型;4) 性能评估模块,用于测量不同模型在不同设备上的推理延迟。流程如下:从Hugging Face下载PyTorch模型,使用MLX-transformers将其转换为MLX格式,然后在Apple Silicon设备上使用MLX框架进行推理,最后评估推理延迟。
关键创新:最重要的技术创新点在于MLX框架本身,它针对Apple Silicon的硬件特性进行了优化,例如利用统一内存架构和Metal框架进行加速。此外,MLX-transformers框架简化了模型转换流程,使得开发者可以更方便地在Apple设备上部署和运行Transformer模型。
关键设计:论文中没有详细描述关键的参数设置、损失函数或网络结构等技术细节。主要关注的是框架层面的优化和性能评估。模型参数和结构直接使用了Hugging Face上的预训练模型。
🖼️ 关键图片
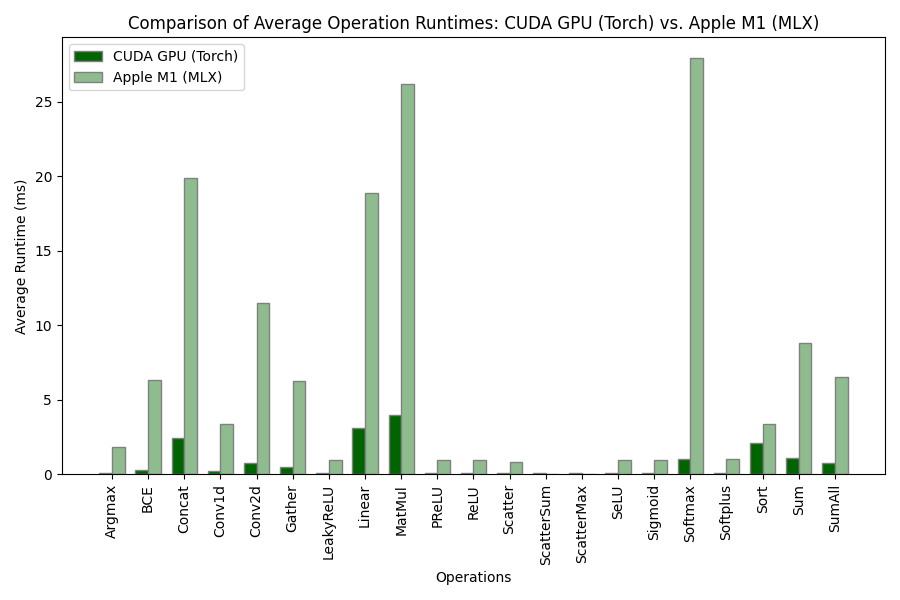
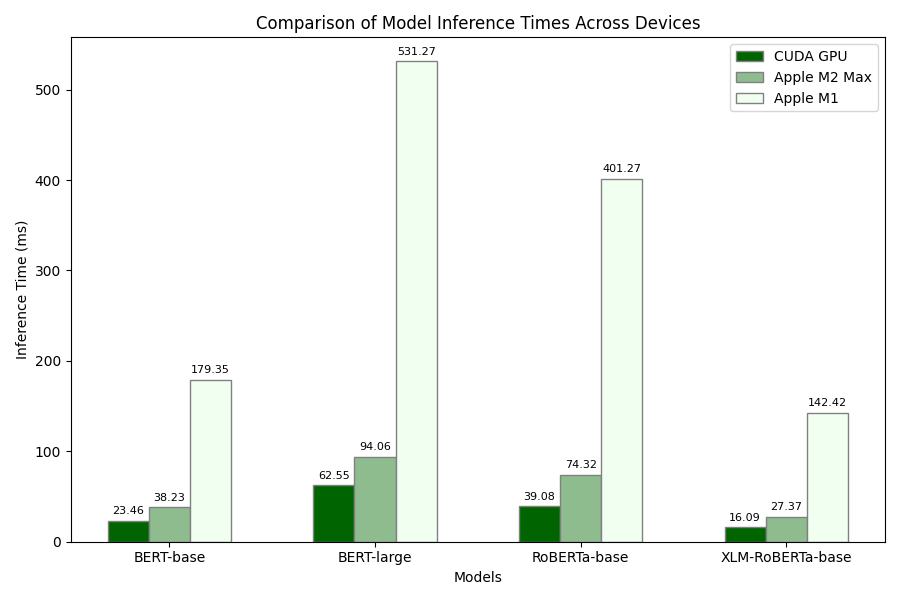
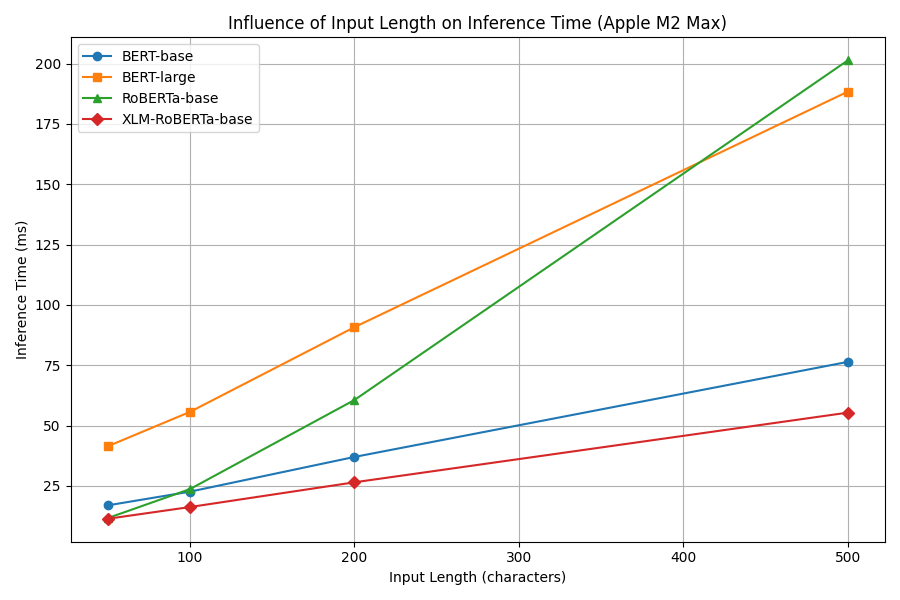
📊 实验亮点
论文通过实验对比了MLX和PyTorch在Apple Silicon设备以及NVIDIA CUDA GPU上的Transformer模型推理性能。实验结果表明,MLX在Apple Silicon设备上具有一定的优势,尤其是在推理延迟方面。虽然没有给出具体的性能数据,但强调了MLX在端侧机器学习方面的潜力。
🎯 应用场景
该研究成果可应用于各种需要端侧智能的场景,例如:离线语音识别、图像处理、自然语言处理等。在保护用户隐私的同时,提供更快速、更可靠的AI服务。未来,可进一步扩展到其他模态的模型,例如音频、视频等,实现更丰富的端侧应用。
📄 摘要(原文)
The recent widespread adoption of Large Language Models (LLMs) and machine learning in general has sparked research interest in exploring the possibilities of deploying these models on smaller devices such as laptops and mobile phones. This creates a need for frameworks and approaches that are capable of taking advantage of on-device hardware. The MLX framework was created to address this need. It is a framework optimized for machine learning (ML) computations on Apple silicon devices, facilitating easier research, experimentation, and prototyping. This paper presents a performance evaluation of MLX, focusing on inference latency of transformer models. We compare the performance of different transformer architecture implementations in MLX with their Pytorch counterparts. For this research we create a framework called MLX-transformers which includes different transformer implementations in MLX and downloads the model checkpoints in pytorch and converts it to the MLX format. By leveraging the advanced architecture and capabilities of Apple Silicon, MLX-Transformers enables seamless execution of transformer models directly sourced from Hugging Face, eliminating the need for checkpoint conversion often required when porting models between frameworks. Our study benchmarks different transformer models on two Apple Silicon macbook devices against an NVIDIA CUDA GPU. Specifically, we compare the inference latency performance of models with the same parameter sizes and checkpoints. We evaluate the performance of BERT, RoBERTa, and XLM-RoBERTa models, with the intention of extending future work to include models of different modalities, thus providing a more comprehensive assessment of MLX's capabilities. The results highlight MLX's potential in enabling efficient and more accessible on-device ML applications within Apple's ecosystem.