ADPO: Anchored Direct Preference Optimization
作者: Wang Zixian
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-10-21 (更新: 2026-01-12)
💡 一句话要点
ADPO:锚定直接偏好优化,通过解耦响应质量与先验流行度提升策略对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 直接偏好优化 强化学习 人类反馈 策略对齐 锚定logits
📋 核心要点
- 现有策略对齐方法未能充分利用参考策略的内在优势,导致优化效率受限。
- ADPO通过锚定logits,显式参数化最优策略的差分结构,解耦响应质量与先验流行度。
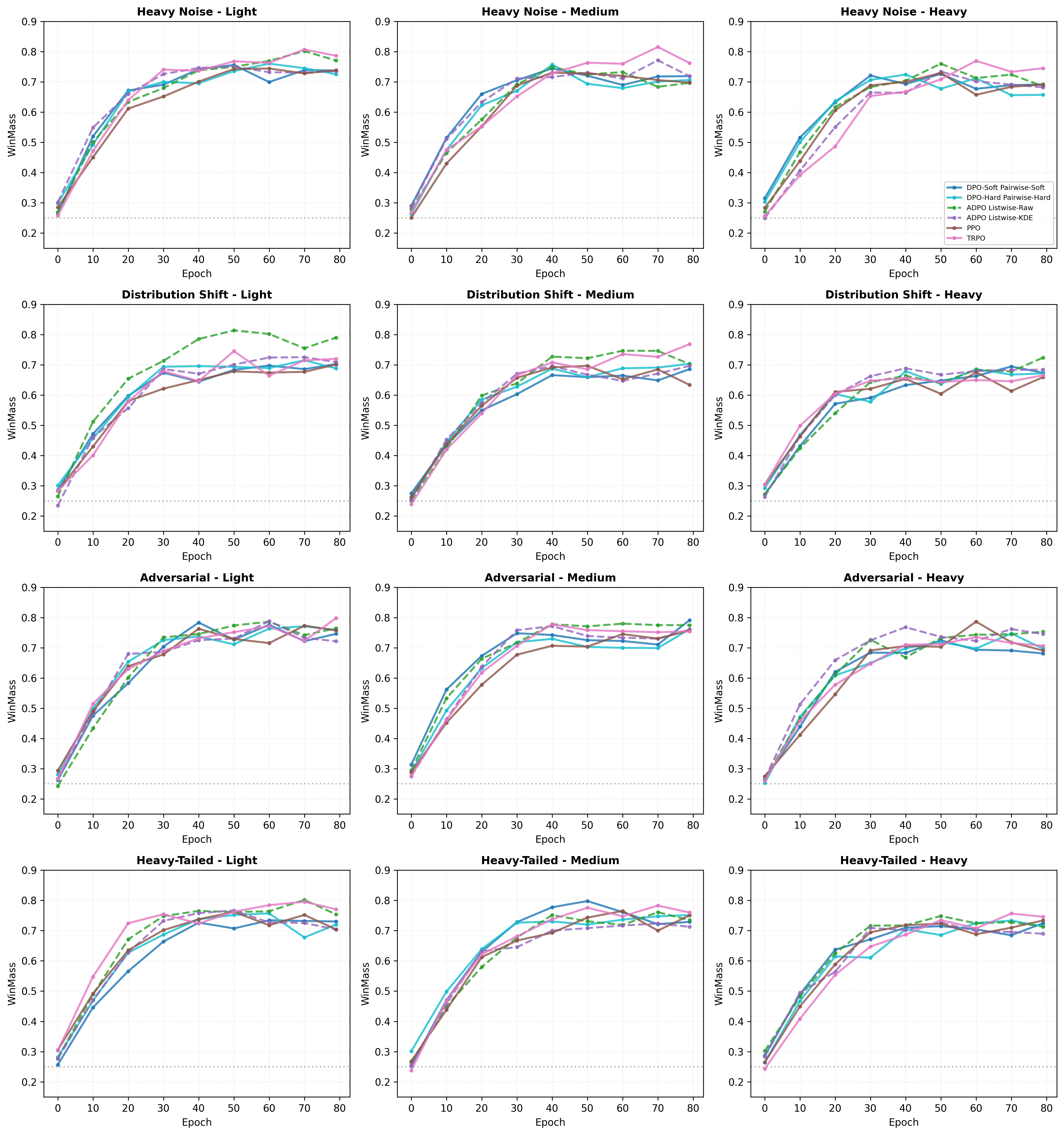
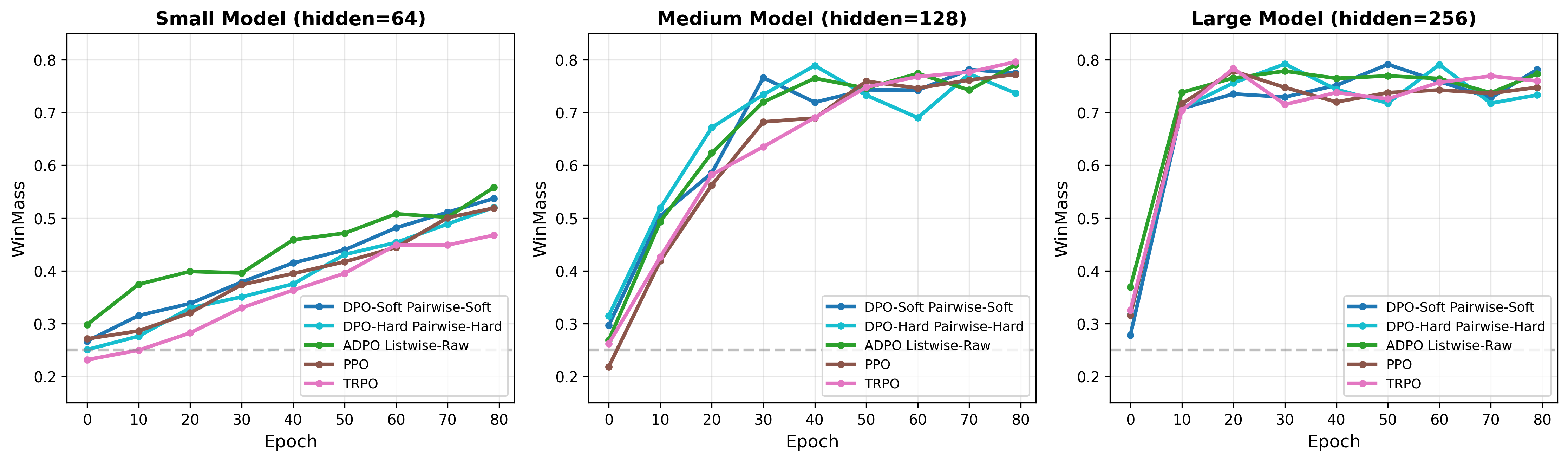
- 实验表明,ADPO在推理任务上超越现有方法,并在分布偏移下表现出更强的鲁棒性。
📝 摘要(中文)
本文提出锚定直接偏好优化(ADPO),这是一种源于KL正则化强化学习第一性原理的策略对齐方法。与将参考策略仅视为正则化项的标准方法不同,我们证明了来自人类反馈的强化学习中的最优策略本质上是在差分坐标系中运行的,以对数比率的形式优化相对优势,而不是绝对概率。ADPO通过锚定logits显式地参数化这种最优结构,有效地将响应质量与先验流行度解耦,并通过曲率缩放创建隐式信任区域。我们表明,这种公式将监督微调、强化学习和基于排序的目标统一在单一的几何视角下。从理论上讲,ADPO解决了监督微调的概率涂抹问题,同时避免了反向KL方法的模式寻求不稳定性。在实验上,ADPO的列表式排序变体在推理任务上实现了最先进的性能,在Qwen3-1.7B上优于GRPO 30.9%,并表现出在分布偏移下更强的鲁棒性。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习方法,例如直接偏好优化(DPO),通常将参考策略视为简单的正则化项,忽略了其内在的结构信息。监督微调(SFT)存在概率涂抹问题,而反向KL方法则容易陷入模式寻求的不稳定性。这些问题限制了策略对齐的效率和效果。
核心思路:ADPO的核心思想是将最优策略视为在差分坐标系中运行,优化的是相对优势(log ratios),而非绝对概率。通过锚定logits,ADPO显式地参数化这种最优结构,从而将响应质量与先验流行度解耦。这种设计允许模型更专注于学习人类偏好,而不是简单地模仿参考策略。
技术框架:ADPO的整体框架基于KL正则化强化学习。它通过引入锚定logits来参数化策略,并使用偏好数据来训练模型。训练过程涉及优化一个目标函数,该函数鼓励模型生成与人类偏好一致的响应,同时保持与参考策略的接近性。ADPO可以统一监督微调、强化学习和基于排序的目标。
关键创新:ADPO的关键创新在于其锚定logits的设计,它有效地将响应质量与先验流行度解耦。这种解耦允许模型更专注于学习人类偏好,而不是简单地模仿参考策略。此外,ADPO通过曲率缩放创建隐式信任区域,避免了模式寻求的不稳定性。
关键设计:ADPO的关键设计包括:1) 锚定logits的参数化方式,具体如何将logits分解为锚定部分和差异部分;2) KL散度的计算方式,如何确保策略不会偏离参考策略太远;3) 目标函数的具体形式,如何平衡人类偏好和参考策略的影响;4) 列表式排序变体的实现细节,如何处理多个候选响应之间的偏好关系。
🖼️ 关键图片
📊 实验亮点
ADPO在推理任务上取得了显著的性能提升。在Qwen3-1.7B模型上,ADPO的列表式排序变体优于GRPO 30.9%。此外,ADPO在分布偏移下表现出更强的鲁棒性,表明其具有更好的泛化能力。这些实验结果验证了ADPO的有效性和优越性。
🎯 应用场景
ADPO可应用于各种需要从人类反馈中学习的场景,例如对话系统、文本生成、代码生成等。它可以提升生成内容的质量、相关性和安全性,并减少模型对有害或不当内容的生成。该方法在提升AI系统的用户体验和安全性方面具有重要价值。
📄 摘要(原文)
We present Anchored Direct Preference Optimization (ADPO), a policy alignment method derived from first principles of KL-regularized reinforcement learning. Unlike standard approaches that treat the reference policy merely as a regularizer, we show that the optimal policy in reinforcement learning from human feedback inherently operates in a differential coordinate system, optimizing relative advantage in the form of log ratios rather than absolute probabilities. ADPO explicitly parameterizes this optimal structure through anchored logits, effectively decoupling response quality from prior popularity and creating an implicit trust region through curvature scaling. We show that this formulation unifies supervised fine-tuning, reinforcement learning, and ranking-based objectives under a single geometric perspective. Theoretically, ADPO resolves the probability smearing problem of supervised fine-tuning while avoiding the mode-seeking instability characteristic of reverse-KL methods. Empirically, the listwise ranking variant of ADPO achieves state-of-the-art performance on reasoning tasks, outperforming GRPO by 30.9 percent on Qwen3-1.7B and demonstrating superior robustness under distribution shift.