Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting
作者: Howard Chen, Noam Razin, Karthik Narasimhan, Danqi Chen
分类: cs.LG, cs.CL
发布日期: 2025-10-21 (更新: 2025-12-03)
💡 一句话要点
利用On-Policy数据缓解语言模型微调中的灾难性遗忘
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灾难性遗忘 语言模型 强化学习 On-Policy学习 监督微调
📋 核心要点
- 语言模型微调易导致灾难性遗忘,现有方法难以兼顾新任务性能和旧知识保留。
- 论文核心思想是利用强化学习的On-Policy特性,在学习新任务时保持先验知识。
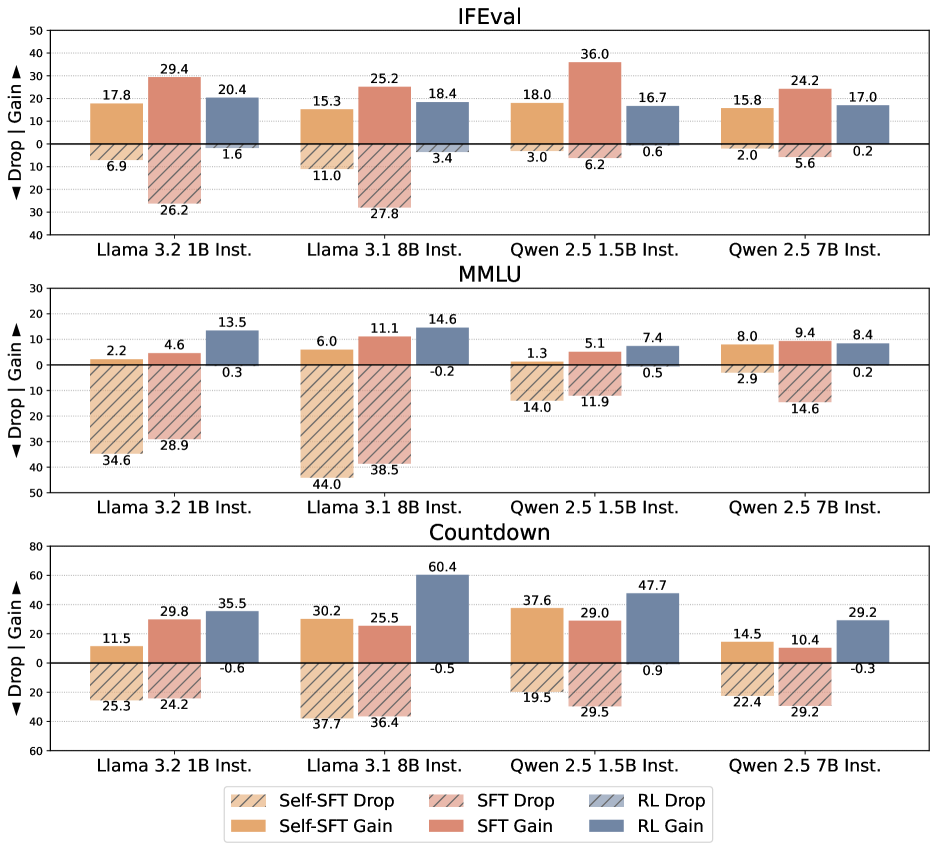
- 实验证明,强化学习比监督微调更有效地缓解遗忘,且目标任务性能相当或更高。
📝 摘要(中文)
通过后训练使语言模型(LM)适应新任务存在降低现有能力的风险,这种现象被称为灾难性遗忘。本文旨在确定缓解这种现象的指导方针,系统地比较了两种广泛采用的后训练方法:监督微调(SFT)和强化学习(RL)的遗忘模式。实验表明,在LM家族(Llama, Qwen)和任务(指令跟随、一般知识和算术推理)中,RL比SFT导致更少的遗忘,同时实现了相当或更高的目标任务性能。为了研究这种差异的原因,我们考虑了一个简化的设置,其中LM被建模为两个分布的混合,一个对应于先验知识,另一个对应于目标任务。我们发现,RL的mode-seeking特性,源于其对on-policy数据的使用,使得在学习目标任务时能够保持先验知识的完整性。我们通过证明在实际环境中,使用on-policy数据是RL对遗忘具有鲁棒性的根本原因,而不是其他算法选择,如KL正则化或优势估计,从而验证了这一观点。最后,作为一个实际的意义,我们的结果强调了使用近似on-policy数据来缓解遗忘的潜力,这种数据比完全on-policy数据更容易获得。
🔬 方法详解
问题定义:论文旨在解决语言模型在进行后训练(如监督微调SFT或强化学习RL)以适应新任务时,出现的灾难性遗忘问题。现有方法,特别是SFT,在提升新任务性能的同时,往往会显著降低模型在原有任务上的表现,导致知识遗忘。
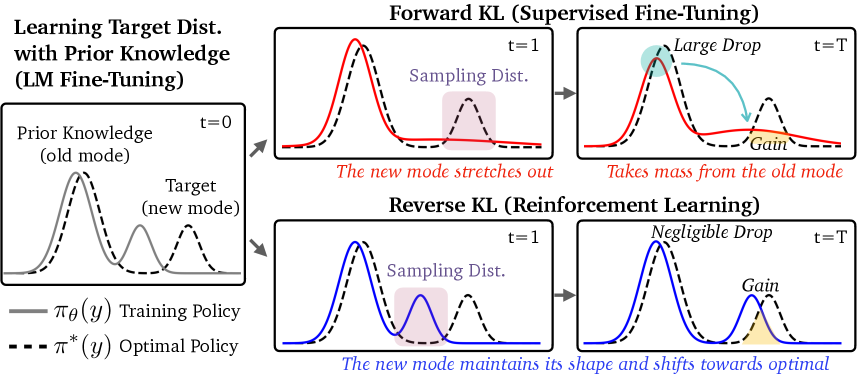
核心思路:论文的核心思路是利用强化学习(RL)的On-Policy特性来缓解遗忘。On-Policy学习意味着RL算法使用当前策略产生的数据进行学习,这种方式倾向于探索和利用当前策略下的最优行为,从而在学习新任务的同时,更好地保持原有知识的分布。论文认为,RL的mode-seeking特性使其在学习目标任务时能够保持先验知识的完整性。
技术框架:论文构建了一个简化的模型,将语言模型视为两个分布的混合:一个代表先验知识,另一个代表目标任务。通过比较SFT和RL在不同任务上的遗忘模式,分析了On-Policy数据在缓解遗忘中的作用。实验涵盖了多种语言模型(Llama, Qwen)和任务(指令跟随、一般知识、算术推理)。
关键创新:论文的关键创新在于揭示了On-Policy数据在缓解语言模型灾难性遗忘中的重要作用。与以往关注KL散度正则化等方法不同,论文强调了数据分布本身对遗忘的影响。通过实验验证,On-Policy数据是RL在缓解遗忘方面优于SFT的根本原因,而不是其他算法选择(如KL正则化或优势估计)。
关键设计:论文通过对比SFT和RL的训练过程,分析了它们在数据使用上的差异。SFT通常使用Off-Policy数据,即预先收集好的数据集,而RL使用On-Policy数据,即由当前策略生成的数据。论文还探讨了近似On-Policy数据的使用,以提高训练效率。具体的参数设置和损失函数根据不同的实验任务和模型而有所调整,但核心在于强调On-Policy数据对知识保留的重要性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在多种语言模型(Llama, Qwen)和任务(指令跟随、一般知识、算术推理)中,强化学习(RL)比监督微调(SFT)导致更少的遗忘,同时实现了相当或更高的目标任务性能。这验证了On-Policy数据在缓解遗忘方面的有效性。论文还通过实验证明,On-Policy数据是RL在缓解遗忘方面优于SFT的根本原因,而不是其他算法选择。
🎯 应用场景
该研究成果可应用于各种需要持续学习和知识保留的语言模型应用场景,例如对话系统、智能助手、知识库问答等。通过采用On-Policy或近似On-Policy的训练方法,可以有效缓解模型在适应新任务时出现的遗忘问题,提升模型的长期性能和用户体验。未来的研究可以进一步探索更高效的On-Policy数据获取方法,以及如何将On-Policy学习与其他缓解遗忘的技术相结合。
📄 摘要(原文)
Adapting language models (LMs) to new tasks via post-training carries the risk of degrading existing capabilities -- a phenomenon classically known as catastrophic forgetting. In this paper, toward identifying guidelines for mitigating this phenomenon, we systematically compare the forgetting patterns of two widely adopted post-training methods: supervised fine-tuning (SFT) and reinforcement learning (RL). Our experiments reveal a consistent trend across LM families (Llama, Qwen) and tasks (instruction following, general knowledge, and arithmetic reasoning): RL leads to less forgetting than SFT while achieving comparable or higher target task performance. To investigate the cause for this difference, we consider a simplified setting in which the LM is modeled as a mixture of two distributions, one corresponding to prior knowledge and the other to the target task. We identify that the mode-seeking nature of RL, which stems from its use of on-policy data, enables keeping prior knowledge intact when learning the target task. We then verify this insight by demonstrating that the use on-policy data underlies the robustness of RL to forgetting in practical settings, as opposed to other algorithmic choices such as the KL regularization or advantage estimation. Lastly, as a practical implication, our results highlight the potential of mitigating forgetting using approximately on-policy data, which can be substantially more efficient to obtain than fully on-policy data.