Learning to Navigate Under Imperfect Perception: Conformalised Segmentation for Safe Reinforcement Learning
作者: Daniel Bethell, Simos Gerasimou, Radu Calinescu, Calum Imrie
分类: cs.LG
发布日期: 2025-10-21
💡 一句话要点
提出COPPOL,结合Conformal Prediction与强化学习,实现安全导航。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Conformal Prediction 强化学习 安全导航 语义分割 不确定性量化
📋 核心要点
- 现有导航方法依赖于完美的危险检测,忽略了实际场景中感知的不确定性,导致安全风险。
- COPPOL利用Conformal Prediction生成带有严格保证的危险地图,为强化学习提供风险感知的成本信息。
- 实验表明,COPPOL显著提高了危险区域的覆盖率,降低了导航过程中的安全违规,并对分布偏移具有鲁棒性。
📝 摘要(中文)
在安全攸关的环境中进行可靠导航,需要精确的危险感知和合理的不确定性处理,以加强下游安全处理。现有方法虽然有效,但假设具有完美的危险检测能力,而不确定性感知方法缺乏有限样本保证。我们提出了COPPOL,一种由Conformal Prediction驱动的感知到策略学习方法,它将无分布、有限样本安全保证集成到语义分割中,从而产生校准的危险地图,并为漏检提供严格的界限。这些地图为下游强化学习规划引入了风险感知的成本场。在两个卫星衍生的基准测试中,与对比基线相比,COPPOL增加了危险覆盖率(高达6倍),实现了对不安全区域的近乎完整的检测,同时减少了导航期间的危险违规(高达约50%)。更重要的是,我们的方法对分布偏移保持鲁棒性,同时保持安全性和效率。
🔬 方法详解
问题定义:现有基于强化学习的导航方法通常假设环境感知是完美的,即能够准确无误地检测到所有危险区域。然而,在实际应用中,感知系统(例如语义分割模型)不可避免地存在误差,导致漏检或误检,从而影响导航的安全性。现有不确定性感知方法虽然考虑了感知误差,但缺乏有限样本保证,难以在安全攸关的场景中应用。
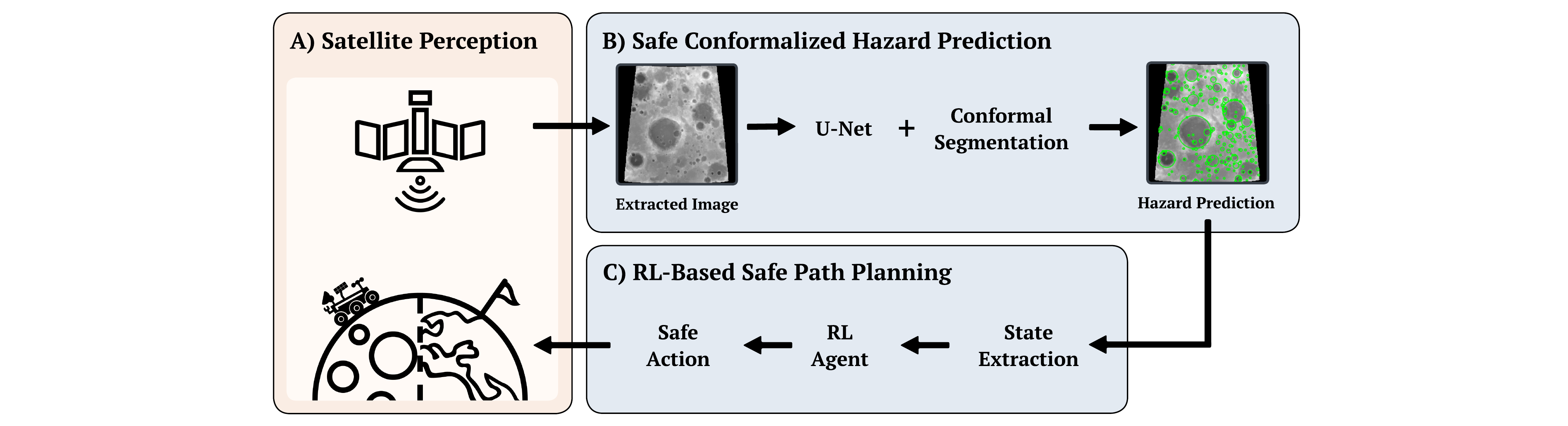
核心思路:COPPOL的核心思路是将Conformal Prediction(CP)集成到语义分割模型中,利用CP提供无分布、有限样本的安全保证。具体来说,CP能够为每个像素的分割结果提供一个置信度区间,从而生成校准的危险地图,并为漏检提供严格的界限。这些危险地图可以作为强化学习的输入,引导智能体避开高风险区域。
技术框架:COPPOL的整体框架包含以下几个主要模块:1) 语义分割模型:用于对环境进行初步的语义分割,识别潜在的危险区域。2) Conformal Prediction模块:利用CP对语义分割模型的输出进行校准,生成带有置信度区间的危险地图。3) 风险感知的成本场:将危险地图转换为风险感知的成本场,用于指导强化学习规划。4) 强化学习规划器:利用风险感知的成本场进行路径规划,找到安全且高效的导航路径。
关键创新:COPPOL最重要的创新点在于将Conformal Prediction与强化学习相结合,为语义分割的输出提供了严格的安全保证。与现有方法相比,COPPOL不需要对数据的分布做出任何假设,并且能够提供有限样本的保证,使其更适用于安全攸关的场景。此外,COPPOL通过风险感知的成本场,将感知的不确定性融入到强化学习的规划过程中,从而提高了导航的安全性。
关键设计:COPPOL的关键设计包括:1) 使用DeepLabv3+作为语义分割模型,以获得较高的分割精度。2) 使用Residual Conformal Prediction (RCP) 来提高 Conformal Prediction 的效率和准确性。3) 将危险地图转换为风险感知的成本场,其中成本与危险区域的置信度成正比。4) 使用 Soft Actor-Critic (SAC) 作为强化学习规划器,以实现高效的探索和利用。
🖼️ 关键图片


📊 实验亮点
实验结果表明,COPPOL在两个卫星衍生的基准测试中,与对比基线相比,危险覆盖率提高了高达6倍,实现了对不安全区域的近乎完整的检测。同时,COPPOL还降低了导航期间的危险违规,降幅高达约50%。更重要的是,COPPOL对分布偏移具有鲁棒性,能够在不同的环境中保持安全性和效率。
🎯 应用场景
COPPOL可应用于各种安全攸关的导航场景,例如自动驾驶、无人机巡检、机器人救援等。该方法能够提高导航系统的安全性,降低事故发生的风险,并为智能体在复杂环境中安全可靠地运行提供保障。未来,COPPOL有望与其他先进的感知和控制技术相结合,进一步提升导航系统的性能和鲁棒性。
📄 摘要(原文)
Reliable navigation in safety-critical environments requires both accurate hazard perception and principled uncertainty handling to strengthen downstream safety handling. Despite the effectiveness of existing approaches, they assume perfect hazard detection capabilities, while uncertainty-aware perception approaches lack finite-sample guarantees. We present COPPOL, a conformal-driven perception-to-policy learning approach that integrates distribution-free, finite-sample safety guarantees into semantic segmentation, yielding calibrated hazard maps with rigorous bounds for missed detections. These maps induce risk-aware cost fields for downstream RL planning. Across two satellite-derived benchmarks, COPPOL increases hazard coverage (up to 6x) compared to comparative baselines, achieving near-complete detection of unsafe regions while reducing hazardous violations during navigation (up to approx 50%). More importantly, our approach remains robust to distributional shift, preserving both safety and efficiency.