Why Policy Gradient Algorithms Work for Undiscounted Total-Reward MDPs
作者: Jongmin Lee, Ernest K. Ryu
分类: cs.LG
发布日期: 2025-10-21
💡 一句话要点
针对无折扣总回报MDP,提出策略梯度算法的收敛性分析方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 策略梯度 强化学习 无折扣MDP 收敛性分析 瞬态访问度量
📋 核心要点
- 现有策略梯度算法的理论分析大多基于有折扣的MDP,无法直接应用于无折扣总回报的场景。
- 论文核心思想是利用MDP状态的循环和瞬态特性,并引入瞬态访问度量来分析无折扣场景下的策略梯度算法。
- 该研究为无折扣总回报MDP下的策略梯度方法提供了理论保障,有助于推动其在大型语言模型等领域的应用。
📝 摘要(中文)
经典的策略梯度方法是现代基于策略的强化学习(RL)算法的理论和概念基础。对此类方法的大多数严格分析,特别是那些建立收敛性保证的分析,都假设折扣因子γ<1。然而,最近关于大型语言模型策略RL的一系列工作使用了γ=1的无折扣总回报设置,使得现有的大部分理论不再适用。在本文中,我们基于两个关键见解,为无折扣预期总回报无限视界MDP的策略梯度方法提供了分析:(i)MDP状态到循环状态和瞬态状态的分类,在为每个动作分配严格正概率的策略集合上是不变的(这在采用softmax输出层的深度RL模型中很常见),以及(ii)经典的状态访问度量(当γ=1时可能定义不明确)可以用我们称之为瞬态访问度量的新对象代替。
🔬 方法详解
问题定义:论文旨在解决无折扣总回报(γ=1)的无限视界马尔可夫决策过程(MDP)中,策略梯度算法的收敛性分析问题。现有策略梯度算法的理论分析,通常依赖于折扣因子γ<1的假设,这使得这些理论无法直接应用于大型语言模型等实际应用中,因为这些应用通常采用无折扣的设置。现有方法在无折扣场景下,状态访问度量可能定义不明确,导致无法进行有效的理论分析。
核心思路:论文的核心思路是,即使在无折扣的情况下,MDP的状态可以被划分为循环状态和瞬态状态,并且这种划分对于所有为每个动作分配严格正概率的策略是不变的。此外,论文引入了一个新的概念,即瞬态访问度量,用来替代经典的状态访问度量。瞬态访问度量在γ=1时仍然可以很好地定义,并且可以用于分析策略梯度算法的收敛性。
技术框架:论文的技术框架主要包括以下几个步骤:首先,对MDP的状态进行分类,区分循环状态和瞬态状态。然后,定义瞬态访问度量,并证明其在无折扣情况下的良好性质。接着,利用瞬态访问度量,推导出策略梯度算法的更新公式。最后,基于更新公式,分析策略梯度算法的收敛性。
关键创新:论文最重要的技术创新点在于引入了瞬态访问度量,并证明了其在无折扣MDP中的有效性。与经典的状态访问度量相比,瞬态访问度量在γ=1时仍然可以很好地定义,并且可以用于分析策略梯度算法的收敛性。此外,论文还证明了MDP状态的循环和瞬态划分,在满足一定条件的策略集合上是不变的,这为分析策略梯度算法提供了重要的理论基础。
关键设计:论文的关键设计包括:(1) 瞬态访问度量的定义,它基于从初始状态到瞬态状态的期望访问次数。(2) 策略集合的选择,论文考虑了为每个动作分配严格正概率的策略集合,这在深度强化学习中是很常见的,例如使用softmax输出层的模型。(3) 收敛性分析的方法,论文利用瞬态访问度量,推导出策略梯度算法的更新公式,并基于该公式分析算法的收敛性。
🖼️ 关键图片

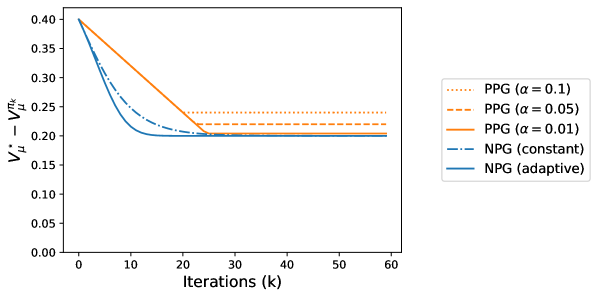
📊 实验亮点
该论文的主要贡献是为无折扣总回报MDP下的策略梯度方法提供了理论分析,证明了在特定条件下算法的收敛性。与现有理论分析主要集中在有折扣MDP不同,该研究填补了无折扣场景下的理论空白,为策略梯度算法在大型语言模型等领域的应用提供了理论支撑。具体的性能数据和对比基线未知,因为论文主要关注理论分析而非实验验证。
🎯 应用场景
该研究成果可直接应用于大型语言模型的策略优化,例如使用强化学习进行指令微调。通过提供无折扣总回报MDP下策略梯度算法的理论保障,该研究有助于提升语言模型在长期交互任务中的性能和稳定性。此外,该方法还可以推广到其他无折扣的强化学习应用场景,例如机器人控制和推荐系统。
📄 摘要(原文)
The classical policy gradient method is the theoretical and conceptual foundation of modern policy-based reinforcement learning (RL) algorithms. Most rigorous analyses of such methods, particularly those establishing convergence guarantees, assume a discount factor $γ< 1$. In contrast, however, a recent line of work on policy-based RL for large language models uses the undiscounted total-reward setting with $γ= 1$, rendering much of the existing theory inapplicable. In this paper, we provide analyses of the policy gradient method for undiscounted expected total-reward infinite-horizon MDPs based on two key insights: (i) the classification of the MDP states into recurrent and transient states is invariant over the set of policies that assign strictly positive probability to every action (as is typical in deep RL models employing a softmax output layer) and (ii) the classical state visitation measure (which may be ill-defined when $γ= 1$) can be replaced with a new object that we call the transient visitation measure.