Higher Embedding Dimension Creates a Stronger World Model for a Simple Sorting Task
作者: Brady Bhalla, Honglu Fan, Nancy Chen, Tony Yue YU
分类: cs.LG, cs.AI
发布日期: 2025-10-21
💡 一句话要点
研究表明,更高维度嵌入能为排序任务Transformer构建更强的世界模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Transformer 强化学习 世界模型 嵌入维度 排序算法 可解释性 注意力机制
📋 核心要点
- 现有方法在利用Transformer解决排序等算法任务时,缺乏对模型内部表示质量的深入理解。
- 该论文通过增加嵌入维度,提升Transformer内部世界模型的质量,从而改善排序任务的性能和可解释性。
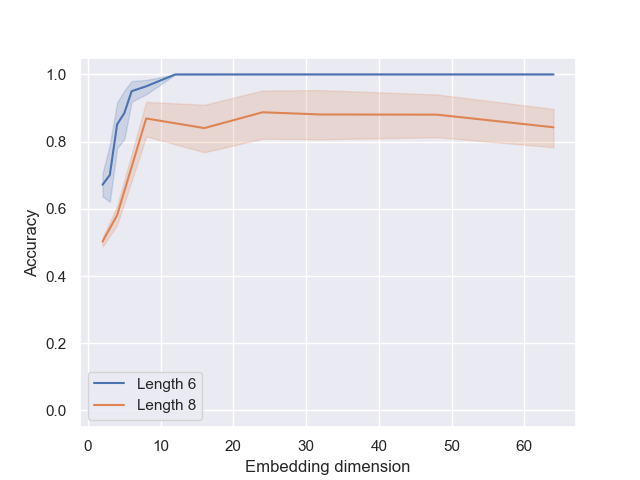
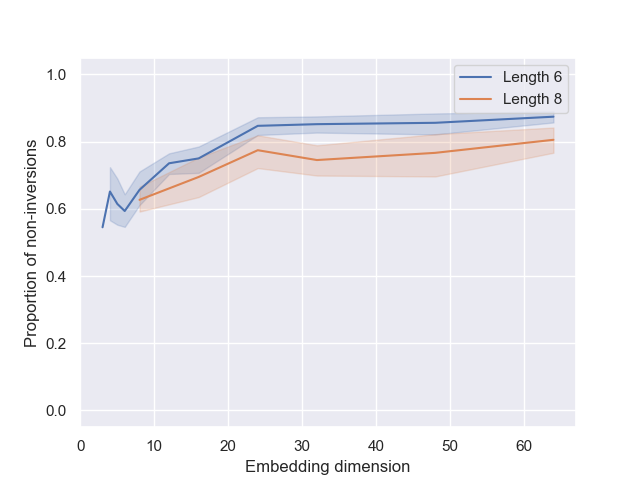
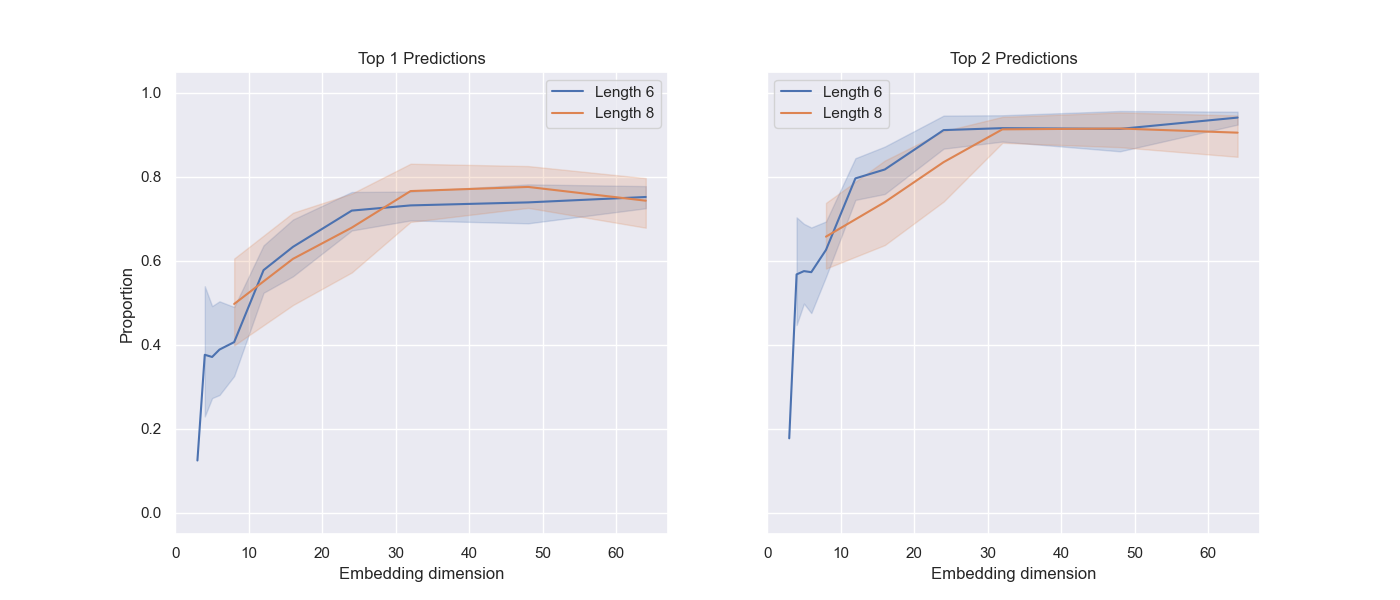
- 实验结果表明,更高维度的嵌入能产生更忠实、一致和鲁棒的内部表示,并加强结构化表示的形成。
📝 摘要(中文)
本文研究了嵌入维度如何影响Transformer在强化学习训练中执行冒泡排序式相邻交换任务时,内部“世界模型”的涌现。即使在非常小的嵌入维度下,模型也能达到很高的准确率,但更大的维度会产生更忠实、一致和鲁棒的内部表示。特别是,更高的嵌入维度加强了结构化内部表示的形成,并提高了可解释性。经过数百次实验,我们观察到两种一致的机制:(1)注意力权重矩阵的最后一行单调地编码了token的全局排序;(2)选择的转置与这些编码值的最大相邻差对齐。我们的结果提供了定量证据,表明Transformer构建了结构化的内部世界模型,并且模型大小除了提高最终性能外,还提高了表示质量。我们发布了我们的指标和分析,这些指标和分析可用于探测类似的算法任务。
🔬 方法详解
问题定义:论文旨在研究在使用Transformer进行强化学习以解决排序问题时,嵌入维度对模型内部“世界模型”的影响。现有方法虽然能完成排序任务,但缺乏对模型内部表示的理解,难以解释模型行为,且可能存在鲁棒性问题。
核心思路:核心思路是通过增加Transformer的嵌入维度,来提升其内部世界模型的质量。作者假设,更高维度的嵌入能够让模型学习到更丰富、更准确的内部表示,从而更好地理解和处理排序任务。这种设计旨在提高模型的可解释性和鲁棒性。
技术框架:该研究使用Transformer模型,并采用强化学习方法进行训练,使其学习执行冒泡排序式的相邻交换操作。整体流程包括:输入待排序序列,Transformer模型输出交换操作,根据交换后的序列状态给予奖励,并利用奖励信号更新模型参数。关键在于分析不同嵌入维度下,Transformer内部注意力机制的学习情况。
关键创新:该研究的关键创新在于定量分析了嵌入维度对Transformer内部世界模型的影响。通过实验发现,更高维度的嵌入能够促进模型形成结构化的内部表示,具体表现为注意力权重矩阵的最后一行能够单调编码token的全局排序,并且选择的转置操作与编码值的最大相邻差对齐。
关键设计:实验中,作者使用了不同维度的嵌入层来训练Transformer模型。损失函数基于强化学习的奖励信号。网络结构采用标准的Transformer架构,重点关注注意力权重矩阵的学习情况。通过分析注意力权重矩阵的模式,来理解模型内部如何表示和处理排序信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使在小嵌入维度下模型也能达到高准确率,但更高维度能产生更忠实、一致和鲁棒的内部表示。具体而言,注意力权重矩阵的最后一行单调编码了token的全局排序,且选择的转置与编码值的最大相邻差对齐。这些发现为Transformer构建结构化内部世界模型提供了定量证据。
🎯 应用场景
该研究成果可应用于提升AI模型的可解释性和鲁棒性,尤其是在需要模型具备一定推理能力的算法任务中。例如,可以应用于机器人路径规划、资源调度等领域,帮助模型更好地理解环境状态,做出更合理的决策。此外,该研究也为理解Transformer内部机制提供了新的视角。
📄 摘要(原文)
We investigate how embedding dimension affects the emergence of an internal "world model" in a transformer trained with reinforcement learning to perform bubble-sort-style adjacent swaps. Models achieve high accuracy even with very small embedding dimensions, but larger dimensions yield more faithful, consistent, and robust internal representations. In particular, higher embedding dimensions strengthen the formation of structured internal representation and lead to better interpretability. After hundreds of experiments, we observe two consistent mechanisms: (1) the last row of the attention weight matrix monotonically encodes the global ordering of tokens; and (2) the selected transposition aligns with the largest adjacent difference of these encoded values. Our results provide quantitative evidence that transformers build structured internal world models and that model size improves representation quality in addition to end performance. We release our metrics and analyses, which can be used to probe similar algorithmic tasks.