Physics-Informed Parametric Bandits for Beam Alignment in mmWave Communications
作者: Hao Qin, Thang Duong, Ming Li, Chicheng Zhang
分类: cs.LG
发布日期: 2025-10-21
💡 一句话要点
针对毫米波通信波束对准,提出物理信息参数化Bandit算法pretc和prgreedy
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 毫米波通信 波束对准 Bandit算法 物理信息 稀疏多径 相位恢复 移动通信
📋 核心要点
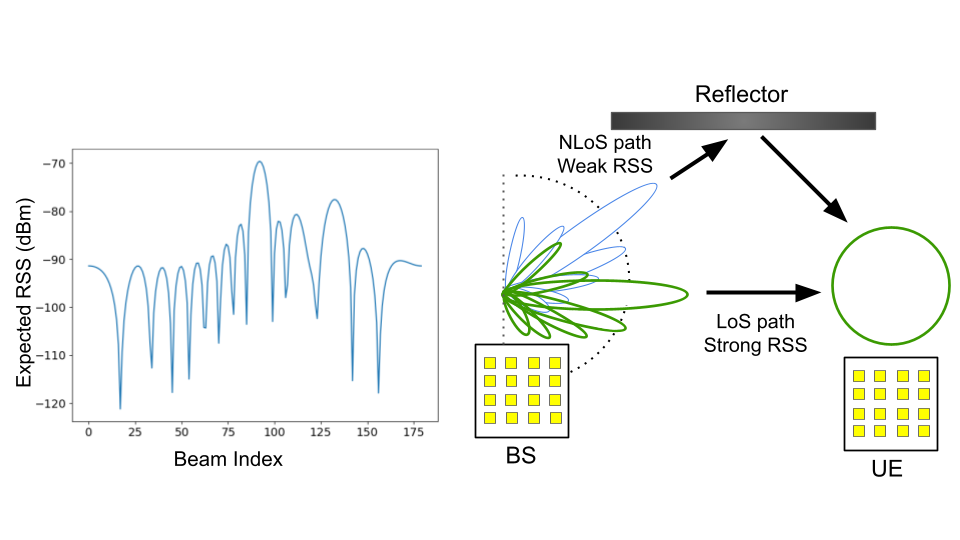
- 传统波束对准算法依赖于奖励函数的单峰或多峰假设,但在实际毫米波通信中这些假设往往不成立,导致性能下降。
- 该论文提出两种物理信息bandit算法,利用毫米波信道的稀疏多径特性,将路径参数视为黑盒进行估计和优化。
- 实验结果表明,所提出的算法在合成和真实数据集上均优于现有方法,展现了良好的通用性和鲁棒性。
📝 摘要(中文)
在毫米波(mmWave)通信中,波束对准和跟踪对于克服显著的路径损耗至关重要。由于扫描整个方向空间效率低下,设计一种高效且鲁棒的方法来识别最佳波束方向至关重要。传统的bandit算法在大波束空间下需要很长时间才能收敛,因此许多现有工作提出了高效的波束对准bandit算法,这些算法依赖于奖励函数结构的单峰或多峰假设。然而,这些假设在实践中通常不成立(或无法严格满足),导致这些算法收敛到选择次优波束。本文提出了两种物理信息bandit算法 extit{pretc}和 extit{prgreedy},它们利用毫米波信道的稀疏多径特性——一个通用但现实的假设——这与相位恢复bandit问题相关。我们的算法将每个路径的参数视为黑盒,并根据采样的历史奖励维护其最佳估计。 extit{pretc}从随机探索阶段开始,然后提交到估计奖励函数下的最佳波束。 extit{prgreedy}以在线方式执行这种估计,并选择当前估计下的最佳波束。我们的算法也可以很容易地适应移动环境中的波束跟踪。通过使用合成的DeepMIMO数据集和真实世界的DeepSense6G数据集进行的实验,我们证明了这两种算法在各种信道环境中的广泛场景中都优于现有方法,显示了它们的通用性和鲁棒性。
🔬 方法详解
问题定义:毫米波通信中,波束对准是关键问题。现有基于bandit算法的方法通常假设奖励函数具有单峰或多峰结构,但实际信道环境复杂,这些假设难以满足,导致算法收敛到次优解。因此,需要一种更鲁棒、更通用的波束对准方法。
核心思路:该论文的核心思路是利用毫米波信道的稀疏多径特性。虽然信道环境复杂,但信号通常只通过少数几条路径传播。算法将每条路径的参数视为黑盒,通过bandit算法学习这些参数,从而估计每个波束方向的奖励值。这种方法不依赖于奖励函数的特定形状假设,更具通用性。
技术框架:算法主要分为两个版本:pretc和prgreedy。pretc算法首先进行随机探索,收集奖励信息,然后根据收集到的信息估计奖励函数,并选择最佳波束。prgreedy算法则以在线方式进行估计和选择,每次迭代都根据当前估计选择最佳波束。两种算法都包含参数估计和波束选择两个主要阶段。
关键创新:该论文的关键创新在于将物理信息(稀疏多径特性)融入到bandit算法中。传统bandit算法通常是无模型的,需要大量采样才能收敛。通过利用物理信息,算法可以更有效地学习奖励函数,从而更快地找到最佳波束。此外,将问题建模为相位恢复bandit问题也是一个创新点。
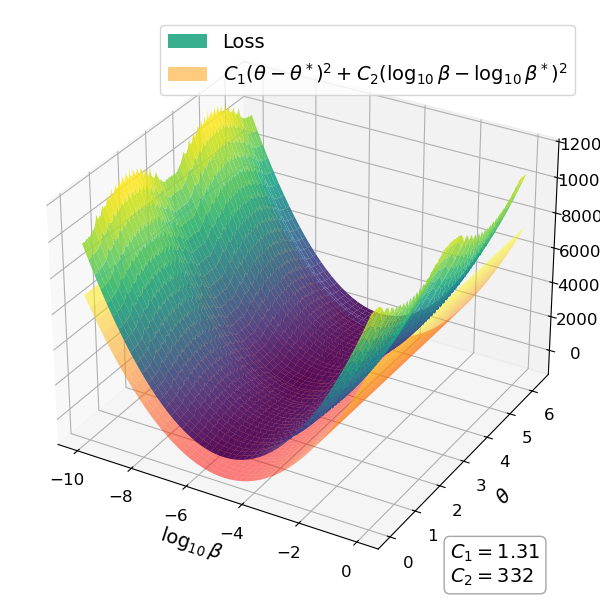
关键设计:算法的关键设计包括:1) 如何有效地估计路径参数;2) 如何平衡探索和利用;3) 如何将算法应用于移动环境中的波束跟踪。具体的技术细节(如参数估计方法、探索策略等)在论文中进行了详细描述。损失函数和网络结构等信息未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的pretc和prgreedy算法在DeepMIMO和DeepSense6G数据集上均优于现有方法。在各种信道环境下,算法都表现出良好的通用性和鲁棒性。具体的性能提升幅度未知,但论文强调了算法在不同场景下的优越性。
🎯 应用场景
该研究成果可应用于各种毫米波通信场景,例如无线回传、5G/6G移动通信、车载通信等。通过提高波束对准的效率和鲁棒性,可以显著提升通信系统的性能,降低功耗,并支持更高的数据传输速率。该方法在移动环境中的应用潜力巨大,有助于实现更可靠的移动通信。
📄 摘要(原文)
In millimeter wave (mmWave) communications, beam alignment and tracking are crucial to combat the significant path loss. As scanning the entire directional space is inefficient, designing an efficient and robust method to identify the optimal beam directions is essential. Since traditional bandit algorithms require a long time horizon to converge under large beam spaces, many existing works propose efficient bandit algorithms for beam alignment by relying on unimodality or multimodality assumptions on the reward function's structure. However, such assumptions often do not hold (or cannot be strictly satisfied) in practice, which causes such algorithms to converge to choosing suboptimal beams. In this work, we propose two physics-informed bandit algorithms \textit{pretc} and \textit{prgreedy} that exploit the sparse multipath property of mmWave channels - a generic but realistic assumption - which is connected to the Phase Retrieval Bandit problem. Our algorithms treat the parameters of each path as black boxes and maintain optimal estimates of them based on sampled historical rewards. \textit{pretc} starts with a random exploration phase and then commits to the optimal beam under the estimated reward function. \textit{prgreedy} performs such estimation in an online manner and chooses the best beam under current estimates. Our algorithms can also be easily adapted to beam tracking in the mobile setting. Through experiments using both the synthetic DeepMIMO dataset and the real-world DeepSense6G dataset, we demonstrate that both algorithms outperform existing approaches in a wide range of scenarios across diverse channel environments, showing their generalizability and robustness.