From Competition to Synergy: Unlocking Reinforcement Learning for Subject-Driven Image Generation
作者: Ziwei Huang, Ying Shu, Hao Fang, Quanyu Long, Wenya Wang, Qiushi Guo, Tiezheng Ge, Leilei Gan
分类: cs.LG, cs.CV, cs.GR
发布日期: 2025-10-21
💡 一句话要点
提出定制化GRPO,解决主体驱动图像生成中保真度和可编辑性的trade-off问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 主体驱动图像生成 强化学习 扩散模型 奖励塑造 时间感知加权
📋 核心要点
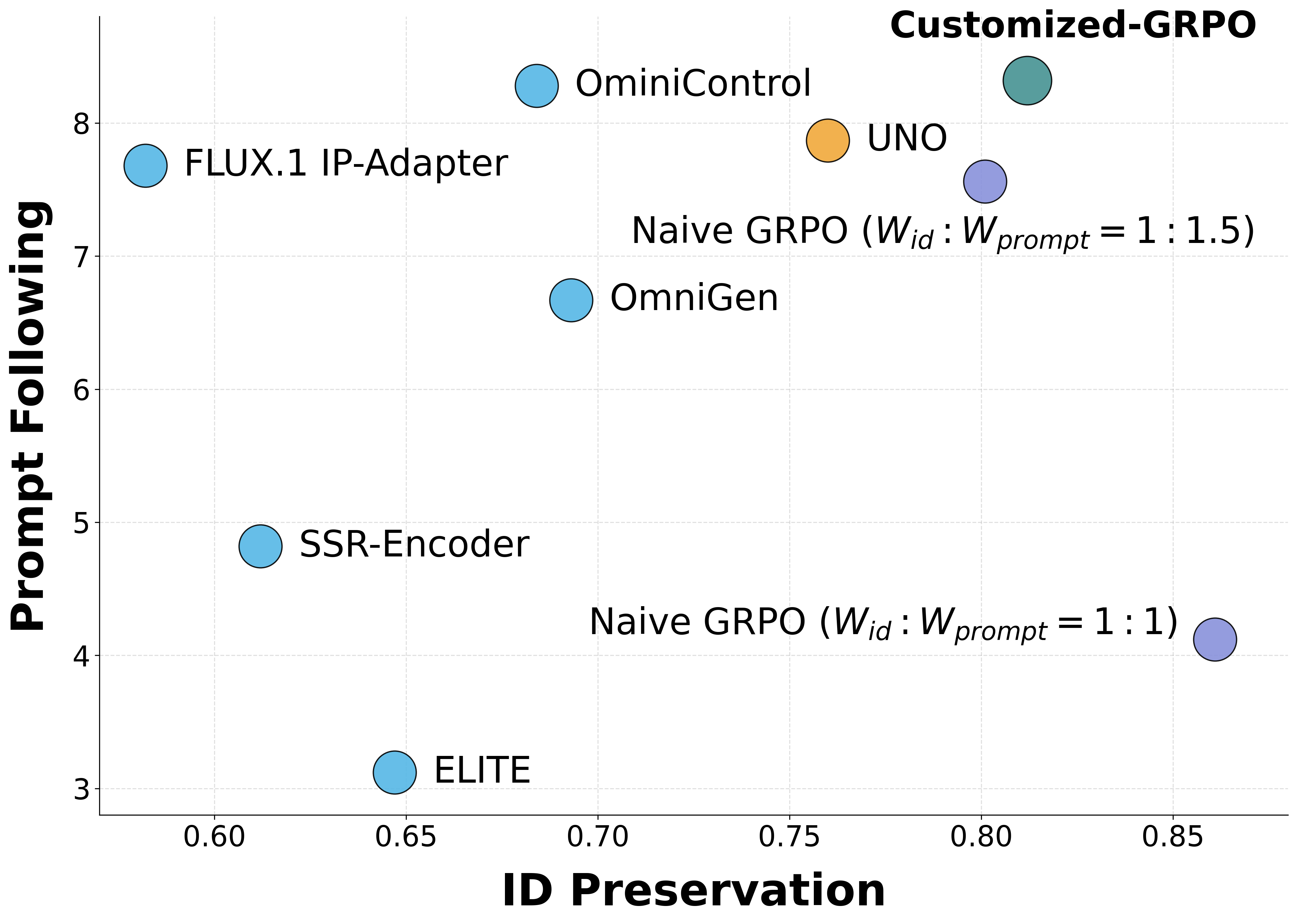
- 主体驱动图像生成需要在身份保持和文本提示的编辑能力之间权衡,现有方法难以兼顾。
- 提出定制化GRPO框架,通过协同感知奖励塑造和时间感知动态加权,优化强化学习过程。
- 实验表明,该方法显著优于现有GRPO基线,在保真度和可编辑性上取得了更好的平衡。
📝 摘要(中文)
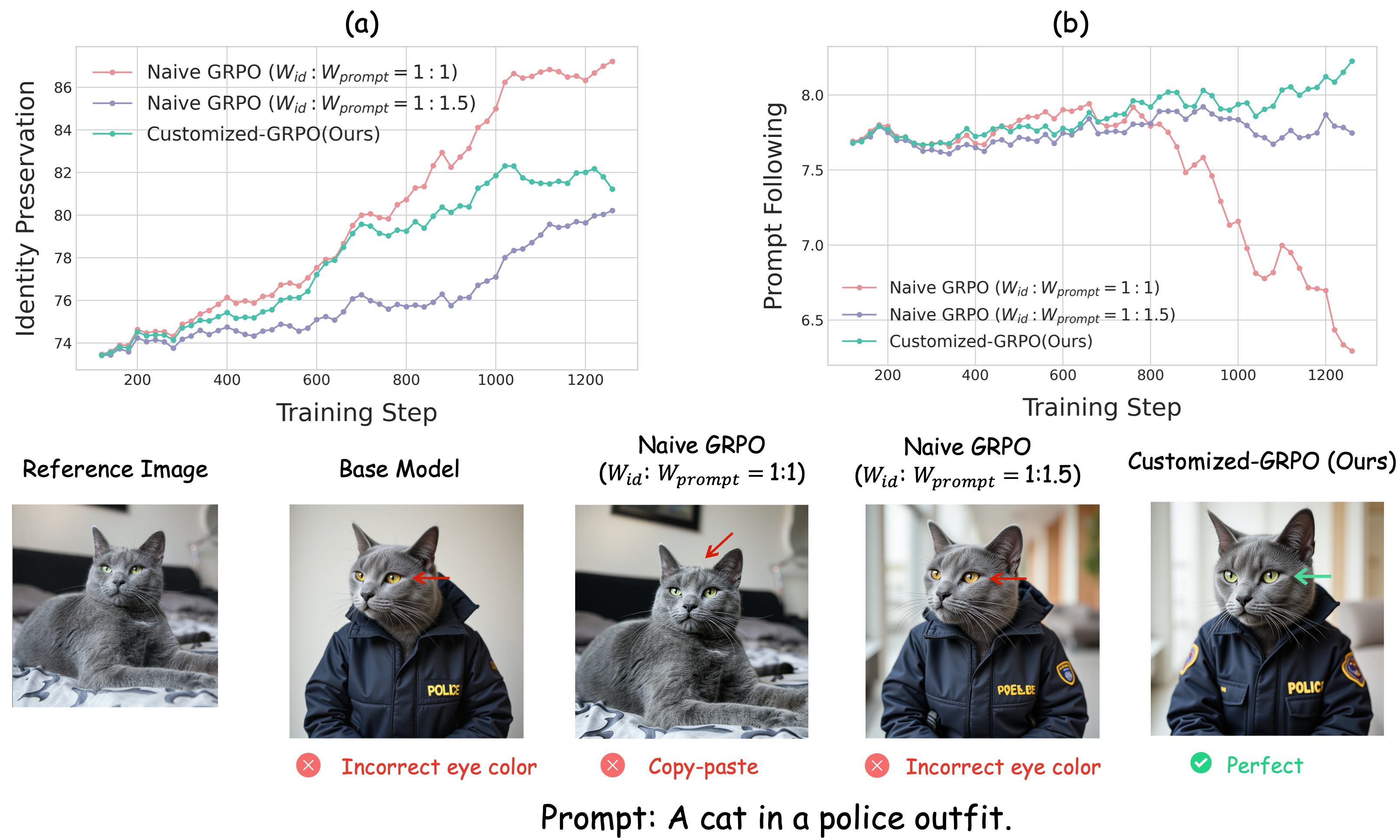
主体驱动的图像生成模型面临着身份保持(保真度)和提示遵循(可编辑性)之间的根本权衡。在线强化学习,特别是GPRO,为此提供了一个有希望的解决方案。然而,我们发现简单地应用GRPO会导致竞争性退化,因为静态权重对奖励进行简单的线性聚合会导致冲突的梯度信号,并与扩散过程的时间动态不一致。为了克服这些限制,我们提出了定制化GRPO(Customized-GRPO),这是一个新颖的框架,包含两个关键创新:(i)协同感知奖励塑造(SARS),一种非线性机制,它明确地惩罚冲突的奖励信号并放大协同的奖励信号,从而提供更清晰和更果断的梯度。(ii)时间感知动态加权(TDW),它通过优先考虑早期阶段的提示遵循和后期阶段的身份保持,使优化压力与模型的时间动态保持一致。大量的实验表明,我们的方法明显优于朴素的GRPO基线,成功地缓解了竞争性退化。我们的模型实现了卓越的平衡,生成既能保留关键身份特征又能准确遵循复杂文本提示的图像。
🔬 方法详解
问题定义:主体驱动图像生成旨在根据给定的主体图像和文本提示生成新的图像。现有方法在身份保持(保真度)和提示遵循(可编辑性)之间存在trade-off。简单地应用在线强化学习方法(如GPRO)会导致梯度冲突,使得模型难以同时优化这两个目标,出现竞争性退化现象。
核心思路:论文的核心思路是通过定制化的强化学习框架,解决GPRO在主体驱动图像生成中出现的梯度冲突问题。具体来说,通过协同感知奖励塑造(SARS)来增强协同的奖励信号,抑制冲突的奖励信号,并利用时间感知动态加权(TDW)来调整不同时间步的优化重点,从而更好地平衡身份保持和提示遵循。
技术框架:Customized-GRPO框架主要包含两个核心模块:协同感知奖励塑造(SARS)和时间感知动态加权(TDW)。SARS模块负责对来自不同奖励函数的信号进行非线性处理,增强协同信号,抑制冲突信号。TDW模块则根据扩散过程的时间步,动态调整身份保持和提示遵循的权重。整体流程是,首先使用扩散模型生成图像,然后计算奖励信号,通过SARS进行奖励塑造,再通过TDW进行权重调整,最后利用调整后的奖励信号更新扩散模型。
关键创新:论文的关键创新在于提出了协同感知奖励塑造(SARS)和时间感知动态加权(TDW)两种机制。SARS通过非线性函数来处理奖励信号,能够更有效地识别和放大协同信号,抑制冲突信号,从而避免梯度冲突。TDW则根据扩散过程的时间步,动态调整优化目标,使得模型在早期阶段更关注提示遵循,在后期阶段更关注身份保持。
关键设计:SARS模块使用一个非线性函数来计算最终的奖励信号,该函数的设计目标是:当多个奖励信号一致时,放大奖励;当多个奖励信号冲突时,抑制奖励。TDW模块则使用一个时间相关的权重函数来调整身份保持和提示遵循的权重,该函数的设计目标是:在扩散过程的早期阶段,提示遵循的权重较高;在扩散过程的后期阶段,身份保持的权重较高。具体的函数形式和参数设置需要根据实际情况进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Customized-GRPO在主体驱动图像生成任务上显著优于基线方法。与朴素的GRPO相比,Customized-GRPO在身份保持和提示遵循方面都取得了更好的效果,有效缓解了竞争性退化问题。具体性能提升数据(如FID、CLIP score等)在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于图像编辑、内容创作、虚拟形象生成等领域。例如,用户可以上传一张人脸照片,并输入一段文本描述,即可生成具有该人脸特征且符合文本描述的新图像。该技术在游戏、社交媒体、广告等行业具有广泛的应用前景,能够提升用户体验和内容创作效率。
📄 摘要(原文)
Subject-driven image generation models face a fundamental trade-off between identity preservation (fidelity) and prompt adherence (editability). While online reinforcement learning (RL), specifically GPRO, offers a promising solution, we find that a naive application of GRPO leads to competitive degradation, as the simple linear aggregation of rewards with static weights causes conflicting gradient signals and a misalignment with the temporal dynamics of the diffusion process. To overcome these limitations, we propose Customized-GRPO, a novel framework featuring two key innovations: (i) Synergy-Aware Reward Shaping (SARS), a non-linear mechanism that explicitly penalizes conflicted reward signals and amplifies synergistic ones, providing a sharper and more decisive gradient. (ii) Time-Aware Dynamic Weighting (TDW), which aligns the optimization pressure with the model's temporal dynamics by prioritizing prompt-following in the early, identity preservation in the later. Extensive experiments demonstrate that our method significantly outperforms naive GRPO baselines, successfully mitigating competitive degradation. Our model achieves a superior balance, generating images that both preserve key identity features and accurately adhere to complex textual prompts.