Towards Fast LLM Fine-tuning through Zeroth-Order Optimization with Projected Gradient-Aligned Perturbations
作者: Zhendong Mi, Qitao Tan, Grace Li Zhang, Zhaozhuo Xu, Geng Yuan, Shaoyi Huang
分类: cs.LG
发布日期: 2025-10-21
备注: 10 pages, 5 figures
💡 一句话要点
提出P-GAP:通过梯度对齐扰动的零阶优化加速LLM微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 零阶优化 微调 梯度对齐 低维空间
📋 核心要点
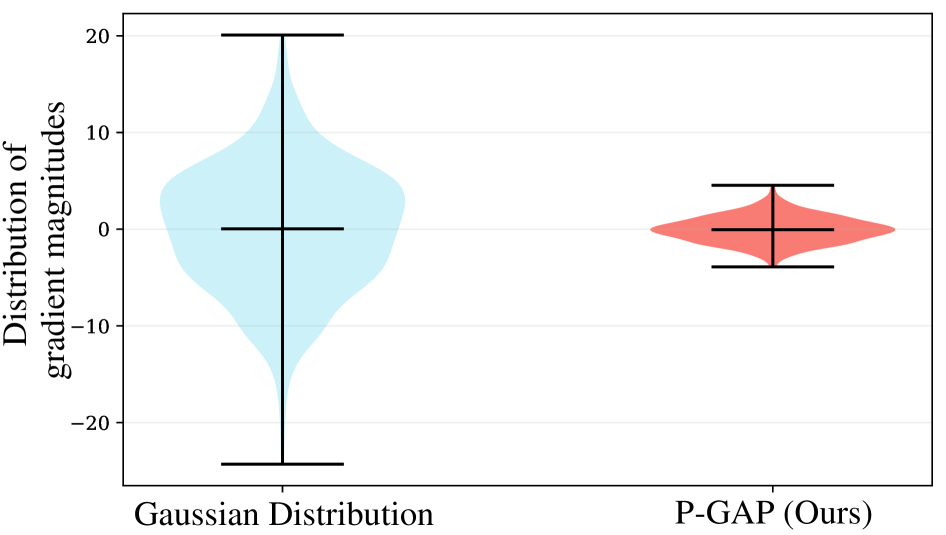
- 现有零阶优化方法微调LLM时,梯度估计方差大,导致收敛慢,性能受限。
- P-GAP通过估计低维梯度空间,并在该空间内对齐扰动,降低方差,加速收敛。
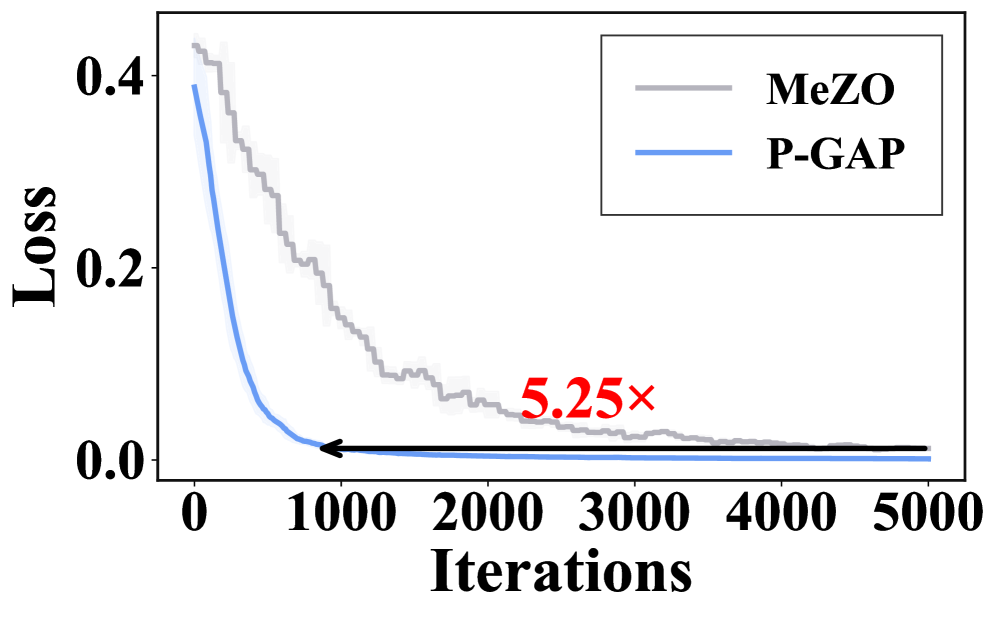
- 实验表明,P-GAP在分类和生成任务上均显著优于基线,并大幅减少了训练时间和资源消耗。
📝 摘要(中文)
本文提出了一种名为P-GAP的快速LLM微调方法,该方法通过带有投影梯度对齐扰动的零阶优化来实现。由于内存占用少,使用零阶(ZO)优化微调大型语言模型(LLM)已成为传统基于梯度方法的有希望的替代方案。然而,现有的ZO方法存在梯度估计方差大的问题,导致收敛速度慢,并且在大规模模型上的性能欠佳。P-GAP首先估计一个低维梯度空间,然后在该空间内沿投影梯度的方向对齐扰动。这种方法减少了扰动参数的数量并降低了方差,从而加速了LLM微调的收敛。在LLM上的实验表明,P-GAP始终优于基线方法,在分类任务上实现了高达6%的准确率提升,在生成任务上实现了高达12%的准确率提升,同时减少了约81%的训练迭代次数和70%的GPU使用时间。这些结果表明,P-GAP能够实现快速、可扩展且资源高效的ZO LLM微调。
🔬 方法详解
问题定义:论文旨在解决使用零阶优化方法微调大型语言模型时,由于梯度估计方差过大导致的收敛速度慢和性能不佳的问题。现有的零阶优化方法需要大量的样本来估计梯度,这使得它们在计算资源有限的情况下难以应用到大型模型上。
核心思路:论文的核心思路是利用一个低维的梯度空间来约束扰动方向,从而降低梯度估计的方差。通过将扰动限制在与梯度对齐的方向上,可以更有效地利用每次迭代的信息,加速收敛。
技术框架:P-GAP方法主要包含两个阶段:1) 梯度空间估计:使用少量样本估计一个低维的梯度空间。2) 梯度对齐扰动:在每次迭代中,将扰动投影到估计的梯度空间中,并沿着投影梯度的方向进行更新。整体流程是在零阶优化的框架下,通过梯度空间约束来提高梯度估计的效率。
关键创新:P-GAP的关键创新在于提出了投影梯度对齐扰动(Projected Gradient-Aligned Perturbations)的概念。与传统的零阶优化方法随机扰动参数不同,P-GAP将扰动限制在一个低维的梯度空间中,从而降低了梯度估计的方差,提高了收敛速度。
关键设计:梯度空间的估计可以使用多种方法,例如随机梯度下降或主成分分析。扰动的大小和方向需要仔细调整,以平衡探索和利用之间的关系。损失函数的选择取决于具体的任务,可以使用交叉熵损失或生成任务中的负对数似然损失等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,P-GAP在LLM微调任务上显著优于基线方法。在分类任务上,P-GAP的准确率提升高达6%,在生成任务上,准确率提升高达12%。同时,P-GAP还大幅减少了训练迭代次数(约81%)和GPU使用时间(约70%)。这些结果充分证明了P-GAP在加速LLM微调方面的有效性和资源效率。
🎯 应用场景
P-GAP方法可应用于各种需要微调大型语言模型的场景,尤其是在计算资源有限的情况下。例如,在边缘设备上部署LLM,或者在数据隐私要求较高的情况下进行联邦学习。该方法能够降低微调成本,加速模型迭代,并提高模型在特定任务上的性能。未来,P-GAP可以进一步扩展到其他类型的模型和任务中。
📄 摘要(原文)
Fine-tuning large language models (LLMs) using zeroth-order (ZO) optimization has emerged as a promising alternative to traditional gradient-based methods due to its reduced memory footprint requirement. However, existing ZO methods suffer from high variance in gradient estimation, leading to slow convergence and suboptimal performance on large-scale models. In this work, we propose P-GAP, a fast LLM fine-tuning approach through zeroth-order optimization with Projected Gradient-Aligned Perturbations. Specifically, we first estimate a low-dimensional gradient space and then align perturbations in projected gradients' direction within the space. This approach enables reduced the number of perturbed parameters and decreased variance, therefore accelerated convergence for LLM fine-tuning. Experiments on LLMs show that P-GAP consistently surpasses the baselines, achieving up to 6% increase in accuracy on classification tasks and up to 12% higher accuracy on generation tasks, with up to about 81% less training iterations and 70% less GPU hours. These results demonstrate that P-GAP enables fast, scalable, and resource-efficient ZO LLM fine-tuning.