ActivationReasoning: Logical Reasoning in Latent Activation Spaces
作者: Lukas Helff, Ruben Härle, Wolfgang Stammer, Felix Friedrich, Manuel Brack, Antonia Wüst, Hikaru Shindo, Patrick Schramowski, Kristian Kersting
分类: cs.LG, cs.AI
发布日期: 2025-10-21
💡 一句话要点
提出ActivationReasoning框架,将逻辑推理嵌入LLM的隐空间以提升可控性和可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 逻辑推理 大型语言模型 隐空间表示 稀疏自编码器 可解释性 模型控制 知识表示
📋 核心要点
- 现有LLM推理过程不透明,缺乏可控性,SAE虽能提供一定解释性,但缺乏系统推理机制。
- ActivationReasoning框架通过在LLM隐空间嵌入逻辑推理,实现对模型行为的结构化控制和引导。
- 实验表明,AR在多跳推理、抽象推理和安全性任务中表现出良好的鲁棒性、泛化性和迁移性。
📝 摘要(中文)
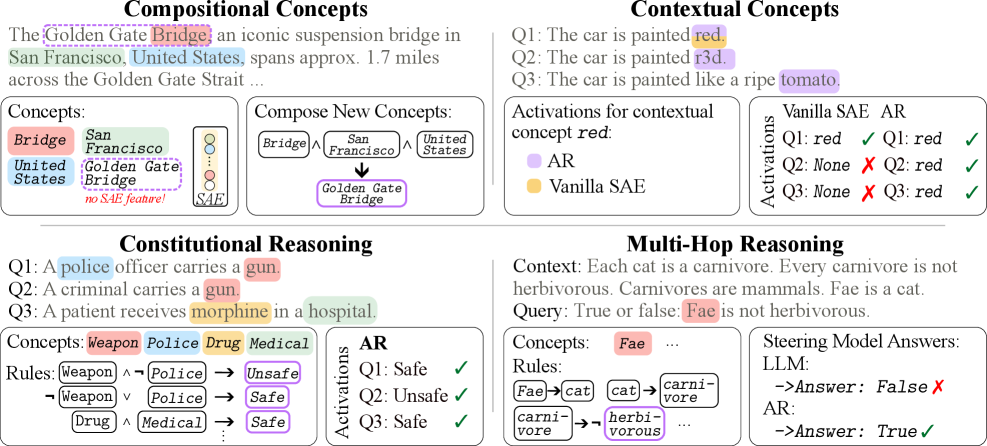
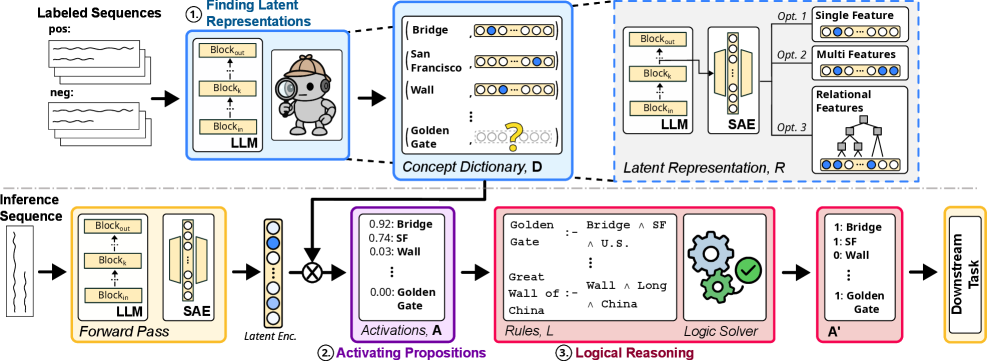
大型语言模型(LLMs)擅长生成流畅的文本,但其内部推理过程不透明且难以控制。稀疏自编码器(SAEs)通过暴露通常与人类概念对齐的潜在特征,使隐藏激活更具可解释性。然而,这些特征是脆弱和被动的,没有提供系统推理或模型控制的机制。为了解决这个问题,我们引入了ActivationReasoning (AR),一个将显式逻辑推理嵌入LLM潜在空间的框架。它分三个阶段进行:(1) 寻找潜在表示,首先识别潜在概念表示(例如,通过SAEs)并组织成字典;(2) 激活命题,在推理时,AR检测激活概念并将它们映射到逻辑命题;(3) 逻辑推理,应用逻辑规则对这些命题进行推理,以推断更高阶的结构,组合新的概念,并引导模型行为。我们在多跳推理(PrOntoQA)、抽象和对间接概念线索的鲁棒性(Rail2Country)、对自然和多样化语言的推理(ProverQA)以及上下文相关的安全性(BeaverTails)上评估了AR。在所有任务中,AR都能随着推理复杂性的增加而稳健地扩展,推广到抽象和上下文相关的任务,并在模型骨干网络之间迁移。这些结果表明,将逻辑结构建立在潜在激活中不仅提高了透明度,而且实现了结构化推理、可靠的控制以及与期望行为的对齐,为更可靠和可审计的AI提供了一条道路。
🔬 方法详解
问题定义:大型语言模型虽然在文本生成方面表现出色,但其内部推理过程复杂且难以理解,导致模型行为不可控。现有的稀疏自编码器等方法虽然可以提取一些可解释的特征,但这些特征是孤立的,缺乏进行系统性推理的能力。因此,如何将显式的逻辑推理能力融入到LLM的隐空间中,从而提高模型的可解释性和可控性,是本文要解决的核心问题。
核心思路:ActivationReasoning的核心思路是将LLM的隐空间与显式的逻辑推理相结合。具体来说,它首先通过稀疏自编码器等方法提取LLM隐空间中与人类概念对齐的潜在特征,然后将这些特征映射为逻辑命题,最后利用逻辑规则对这些命题进行推理,从而实现对模型行为的引导和控制。这种设计思路的优势在于,它既利用了LLM强大的文本生成能力,又引入了显式的逻辑推理机制,从而提高了模型的可解释性和可控性。
技术框架:ActivationReasoning框架主要包含三个阶段:1) 潜在表示发现:利用稀疏自编码器等技术,从LLM的隐空间中提取与人类概念相关的潜在特征,并将这些特征组织成一个字典。2) 命题激活:在推理过程中,检测LLM的激活状态,并将激活的潜在特征映射为逻辑命题。3) 逻辑推理:利用预定义的逻辑规则,对激活的命题进行推理,从而推断出更高阶的结构,组合新的概念,并引导模型行为。
关键创新:ActivationReasoning最重要的创新点在于它将显式的逻辑推理嵌入到LLM的隐空间中。与现有方法相比,它不仅可以提高模型的可解释性,还可以实现对模型行为的结构化控制和引导。此外,该框架具有良好的泛化性和迁移性,可以在不同的任务和模型骨干网络上应用。
关键设计:在潜在表示发现阶段,可以使用不同的稀疏自编码器技术来提取潜在特征。在命题激活阶段,需要设计合适的阈值来判断潜在特征是否被激活。在逻辑推理阶段,需要定义合适的逻辑规则,并选择合适的推理引擎。此外,还可以引入一些正则化项来约束潜在特征的学习,从而提高模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
ActivationReasoning在多跳推理(PrOntoQA)、抽象推理(Rail2Country)、自然语言推理(ProverQA)和安全性(BeaverTails)等任务上进行了评估。实验结果表明,AR能够随着推理复杂度的增加而稳健扩展,并具有良好的泛化性和迁移性,验证了其有效性。
🎯 应用场景
ActivationReasoning可应用于需要高可靠性和可解释性的领域,如医疗诊断、金融风控、法律咨询等。通过将逻辑推理嵌入LLM,可以提高模型决策的透明度,减少错误风险,并增强用户对AI系统的信任。
📄 摘要(原文)
Large language models (LLMs) excel at generating fluent text, but their internal reasoning remains opaque and difficult to control. Sparse autoencoders (SAEs) make hidden activations more interpretable by exposing latent features that often align with human concepts. Yet, these features are fragile and passive, offering no mechanism for systematic reasoning or model control. To address this, we introduce ActivationReasoning (AR), a framework that embeds explicit logical reasoning into the latent space of LLMs. It proceeds in three stages: (1) Finding latent representations, first latent concept representations are identified (e.g., via SAEs) and organized into a dictionary; (2) Activating propositions, at inference time AR detects activating concepts and maps them to logical propositions; and (3)Logical reasoning, applying logical rules over these propositions to infer higher-order structures, compose new concepts, and steer model behavior. We evaluate AR on multi-hop reasoning (PrOntoQA), abstraction and robustness to indirect concept cues (Rail2Country), reasoning over natural and diverse language (ProverQA), and context-sensitive safety (BeaverTails). Across all tasks, AR scales robustly with reasoning complexity, generalizes to abstract and context-sensitive tasks, and transfers across model backbones. These results demonstrate that grounding logical structure in latent activations not only improves transparency but also enables structured reasoning, reliable control, and alignment with desired behaviors, providing a path toward more reliable and auditable AI.