An Enhanced Dual Transformer Contrastive Network for Multimodal Sentiment Analysis
作者: Phuong Q. Dao, Mark Roantree, Vuong M. Ngo
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-20
备注: The paper has been accepted for presentation at the MEDES 2025 conference
💡 一句话要点
提出双Transformer对比网络DTCN,用于增强多模态情感分析性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 Transformer 对比学习 早期融合 BERT ViT 跨模态学习
📋 核心要点
- 现有MSA方法在跨模态交互和联合表示学习方面存在不足,难以充分捕捉模态间的复杂关系。
- 论文提出BERT-ViT-EF模型,通过早期融合策略结合BERT和ViT,并进一步提出DTCN,利用对比学习对齐模态特征。
- 实验结果表明,DTCN在TumEmo数据集上取得了最佳性能,并在MVSA-Single数据集上表现出竞争力,验证了方法的有效性。
📝 摘要(中文)
多模态情感分析(MSA)旨在通过联合分析来自多个模态的数据(通常是文本和图像)来理解人类情感,与单模态方法相比,它提供了更丰富和更准确的解释。本文首先提出了BERT-ViT-EF,这是一种新颖的模型,它通过早期融合策略结合了强大的基于Transformer的编码器BERT(用于文本输入)和ViT(用于视觉输入)。这种方法促进了更深入的跨模态交互和更有效的联合表示学习。为了进一步增强模型的能力,我们提出了一个名为双Transformer对比网络(DTCN)的扩展,它建立在BERT-ViT-EF的基础上。DTCN在BERT之后加入了一个额外的Transformer编码器层,以细化文本上下文(在融合之前),并采用对比学习来对齐文本和图像表示,从而促进了鲁棒的多模态特征学习。在两个广泛使用的MSA基准MVSA-Single和TumEmo上的实验结果证明了我们方法的有效性。DTCN在TumEmo上实现了最佳的准确率(78.4%)和F1分数(78.3%),并在MVSA-Single上提供了具有竞争力的性能,准确率为76.6%,F1分数为75.9%。这些改进突出了基于Transformer的多模态情感分析中早期融合和更深层次上下文建模的优势。
🔬 方法详解
问题定义:论文旨在解决多模态情感分析中,如何更有效地融合文本和图像信息,从而提升情感识别的准确率。现有方法在跨模态特征交互和联合表示学习方面存在不足,难以充分利用不同模态之间的互补信息。
核心思路:论文的核心思路是利用Transformer强大的特征提取能力,通过早期融合策略将文本和图像特征进行有效融合,并引入对比学习来对齐不同模态的表示,从而学习到更鲁棒的多模态特征。
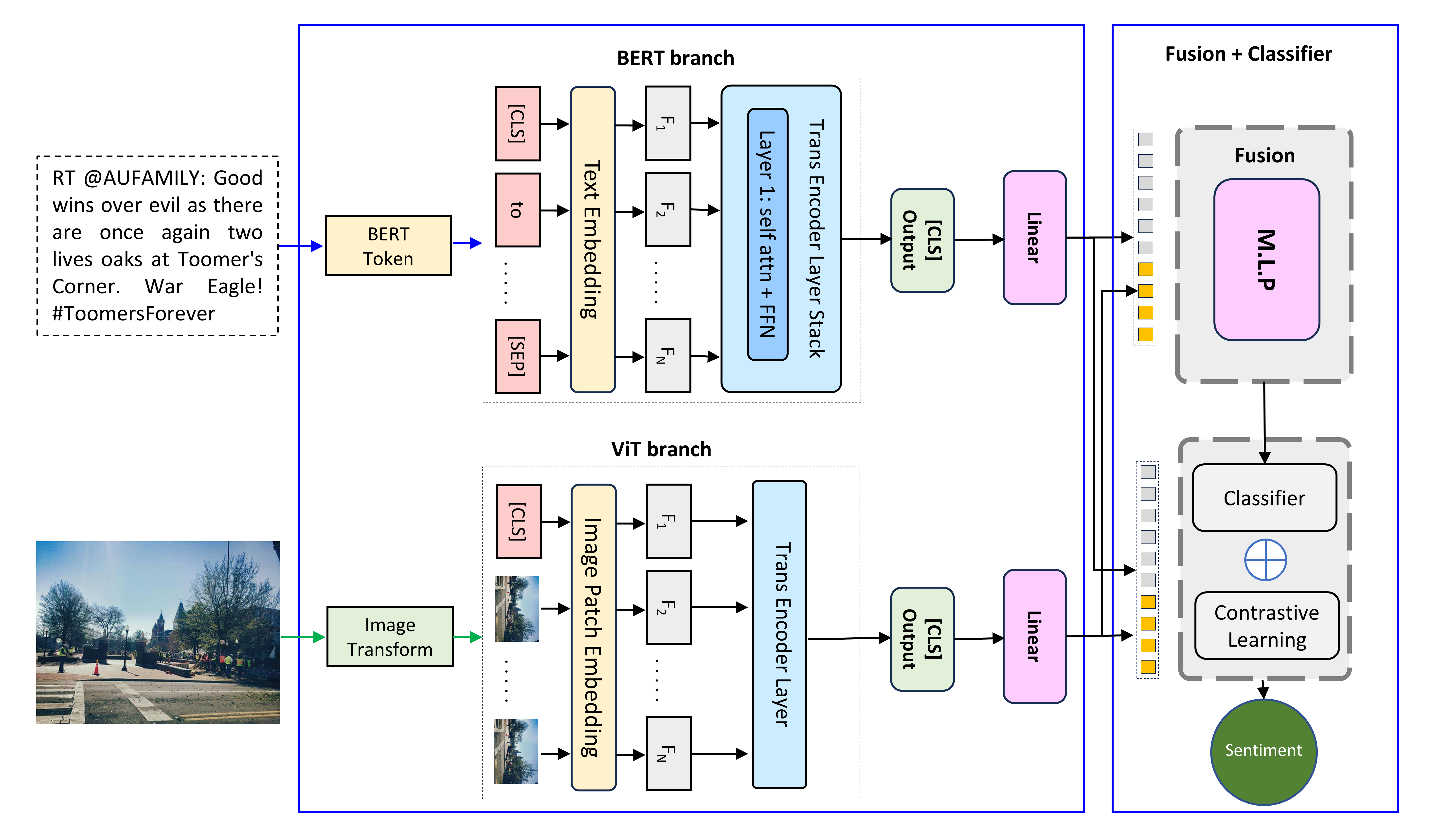
技术框架:整体框架包含以下几个主要模块:1) 文本编码器(BERT):用于提取文本特征。2) 图像编码器(ViT):用于提取图像特征。3) 早期融合层:将文本和图像特征进行融合。4) 额外的Transformer编码器层:用于进一步细化文本上下文。5) 对比学习模块:用于对齐文本和图像表示。整体流程是先分别提取文本和图像特征,然后进行早期融合,再通过额外的Transformer层细化文本信息,最后使用对比学习对齐模态特征。
关键创新:论文的关键创新在于:1) 提出了BERT-ViT-EF模型,将BERT和ViT进行早期融合。2) 引入了额外的Transformer编码器层,用于细化文本上下文。3) 采用了对比学习来对齐文本和图像表示。与现有方法相比,该方法能够更有效地融合不同模态的信息,并学习到更鲁棒的多模态特征。
关键设计:论文的关键设计包括:1) 使用BERT和ViT作为文本和图像编码器,利用其强大的特征提取能力。2) 在BERT之后添加额外的Transformer层,以增强文本的上下文理解。3) 使用对比损失函数来对齐文本和图像表示,促使模型学习到模态不变的特征。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DTCN在TumEmo数据集上取得了最佳的准确率(78.4%)和F1分数(78.3%),相较于现有方法有显著提升。在MVSA-Single数据集上,DTCN也取得了具有竞争力的性能,准确率为76.6%,F1分数为75.9%。这些结果验证了早期融合和更深层次上下文建模在多模态情感分析中的有效性。
🎯 应用场景
该研究成果可应用于情感识别、舆情分析、智能客服、人机交互等领域。通过更准确地理解用户的情感,可以提升用户体验,优化产品设计,并为决策提供更可靠的依据。未来,该方法有望扩展到更多模态的数据融合,例如语音、视频等,从而实现更全面、更精准的情感分析。
📄 摘要(原文)
Multimodal Sentiment Analysis (MSA) seeks to understand human emotions by jointly analyzing data from multiple modalities typically text and images offering a richer and more accurate interpretation than unimodal approaches. In this paper, we first propose BERT-ViT-EF, a novel model that combines powerful Transformer-based encoders BERT for textual input and ViT for visual input through an early fusion strategy. This approach facilitates deeper cross-modal interactions and more effective joint representation learning. To further enhance the model's capability, we propose an extension called the Dual Transformer Contrastive Network (DTCN), which builds upon BERT-ViT-EF. DTCN incorporates an additional Transformer encoder layer after BERT to refine textual context (before fusion) and employs contrastive learning to align text and image representations, fostering robust multimodal feature learning. Empirical results on two widely used MSA benchmarks MVSA-Single and TumEmo demonstrate the effectiveness of our approach. DTCN achieves best accuracy (78.4%) and F1-score (78.3%) on TumEmo, and delivers competitive performance on MVSA-Single, with 76.6% accuracy and 75.9% F1-score. These improvements highlight the benefits of early fusion and deeper contextual modeling in Transformer-based multimodal sentiment analysis.