MARS-M: When Variance Reduction Meets Matrices
作者: Yifeng Liu, Angela Yuan, Quanquan Gu
分类: cs.LG, math.OC, stat.ML
发布日期: 2025-10-20 (更新: 2026-01-29)
🔗 代码/项目: GITHUB
💡 一句话要点
提出MARS-M优化器以提升大规模神经网络训练效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 优化器 方差减少 矩阵运算 大规模神经网络 训练效率 自然语言处理 计算机视觉
📋 核心要点
- 现有的优化器在训练大规模神经网络时效率不足,尤其是在处理方差时表现不佳。
- MARS-M优化器结合了方差减少技术与矩阵基础的Muons,旨在提高收敛速度和训练效率。
- 实验结果显示,MARS-M在多个下游基准测试中均表现出更低的损失和更优的性能,超越了传统优化器。
📝 摘要(中文)
矩阵基础的预条件优化器,如Muon,已被证明在训练大规模神经网络(包括大型语言模型)时比标量基础的优化器更高效。近期的基准研究显示,采用方差减少技术的优化器(如MARS)能显著加速训练。本文提出MARS-M,一种将MARS风格的方差减少与Muon相结合的新优化器。在标准正则条件下,我们证明MARS-M以$ ilde{ ext{O}}(T^{-1/3})$的速率收敛,优于Muon的$ ilde{ ext{O}}(T^{-1/4})$速率。实验证明,MARS-M在语言建模和计算机视觉任务中均表现出更低的损失和更好的性能。
🔬 方法详解
问题定义:本文旨在解决现有优化器在大规模神经网络训练中效率不足的问题,尤其是在方差处理方面的挑战。现有的Muons优化器在收敛速率上存在局限性。
核心思路:MARS-M优化器通过将MARS风格的方差减少技术与Muons相结合,设计出一种新的优化策略,以提高收敛速度和训练效率。这样的设计旨在充分利用矩阵优化的优势,同时减少训练过程中的方差。
技术框架:MARS-M的整体架构包括方差减少模块和矩阵优化模块。方差减少模块负责降低训练过程中的方差,而矩阵优化模块则利用矩阵运算加速优化过程。整体流程包括初始化参数、迭代更新和收敛检测等阶段。
关键创新:MARS-M的主要创新在于其收敛速率的提升,从$ ilde{ ext{O}}(T^{-1/4})$提高到$ ilde{ ext{O}}(T^{-1/3})$,这在理论上和实践中均显著优于现有的Muons优化器。
关键设计:MARS-M的设计中,关键参数设置包括学习率的动态调整和方差估计的优化。此外,损失函数的选择和网络结构的设计也经过精心调整,以确保优化过程的高效性和稳定性。
🖼️ 关键图片


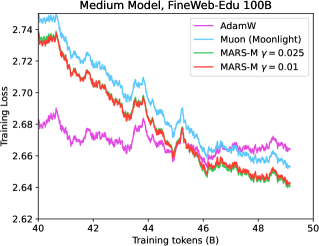
📊 实验亮点
实验结果表明,MARS-M在语言建模和计算机视觉任务中均实现了显著的性能提升。具体而言,与传统优化器相比,MARS-M在多个基准测试中降低了损失,并提高了模型的准确性,展示了其在实际应用中的有效性。
🎯 应用场景
MARS-M优化器在大规模神经网络的训练中具有广泛的应用潜力,尤其是在自然语言处理和计算机视觉等领域。其高效的收敛特性能够显著缩短训练时间,提高模型的实际应用价值。未来,MARS-M有望在更多复杂任务中展现出优越的性能,推动相关技术的发展。
📄 摘要(原文)
Matrix-based preconditioned optimizers, such as Muon, have recently been shown to be more efficient than scalar-based optimizers for training large-scale neural networks, including large language models (LLMs). Recent benchmark studies of LLM pretraining optimizers have demonstrated that variance-reduction techniques such as MARS can substantially speed up training compared with standard optimizers that do not employ variance reduction. In this paper, we introduce MARS-M, a new optimizer that integrates MARS-style variance reduction with Muon. Under standard regularity conditions, we prove that MARS-M converges to a first-order stationary point at a rate of $\tilde{\mathcal{O}}(T^{-1/3})$, improving upon the $\tilde{\mathcal{O}}(T^{-1/4})$ rate attained by Muon. Empirical results on language modeling and computer vision tasks demonstrate that MARS-M consistently yields lower losses and improved performance across various downstream benchmarks. The implementation of MARS-M is available at https://github.com/AGI-Arena/MARS/tree/main/MARS_M.