Quantifying Multimodal Imbalance: A GMM-Guided Adaptive Loss for Audio-Visual Learning
作者: Zhaocheng Liu, Zhiwen Yu, Xiaoqing Liu
分类: cs.LG, cs.AI, cs.SD, eess.AS
发布日期: 2025-10-20 (更新: 2025-10-29)
💡 一句话要点
提出GMM引导的自适应损失,量化多模态不平衡并提升音视频学习性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 模态不平衡 高斯混合模型 自适应损失 音视频融合 定量分析 深度学习
📋 核心要点
- 现有方法在解决多模态学习中的数据不平衡问题时,缺乏对不平衡现象的量化分析和有效利用。
- 论文提出一种基于高斯混合模型(GMM)的自适应损失函数,旨在量化模态间的不平衡程度,并动态调整损失权重。
- 实验结果表明,该方法在CREMA-D、AVE和KineticSound数据集上取得了SOTA性能,验证了其有效性。
📝 摘要(中文)
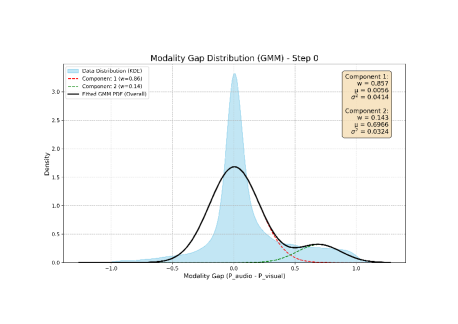
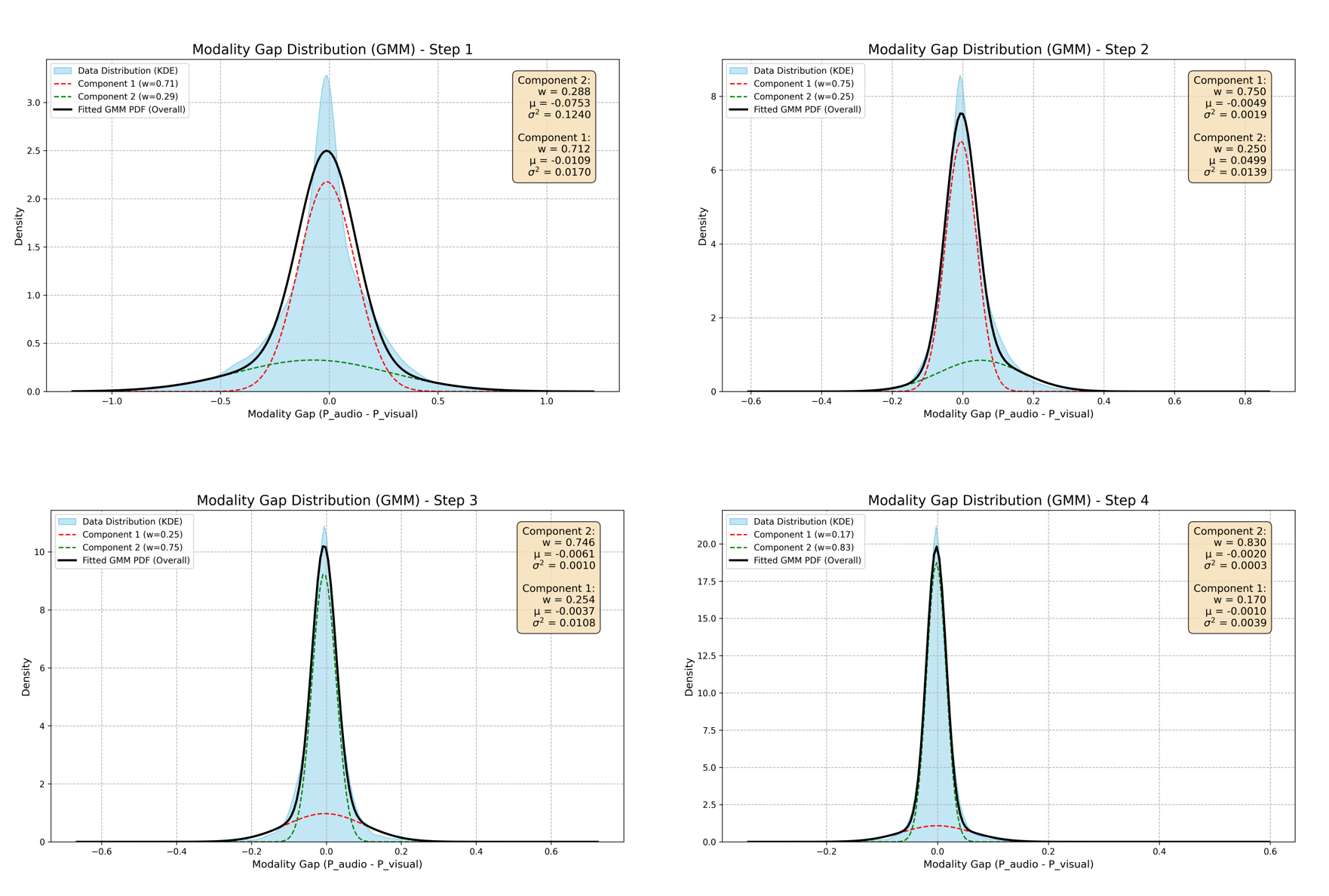
多模态数据的异构性导致不一致和不平衡,使得主导模态能够影响梯度更新。现有解决方案主要集中于优化或数据策略,但很少利用多模态不平衡中固有的信息或进行定量分析。为了解决这个差距,我们提出了一个新颖的多模态不平衡定量分析框架,并设计了一个样本级别的自适应损失函数。我们定义模态差距为正确类别的模态间Softmax得分差异,并使用双峰高斯混合模型(GMM)对其分布进行建模,分别代表平衡和不平衡样本。利用贝叶斯定理,我们估计每个样本属于这两个群体的后验概率。基于此,我们的自适应损失(1)最小化整体模态差距,(2)将不平衡样本与平衡样本对齐,以及(3)根据其不平衡程度自适应地惩罚每个样本。一个两阶段训练策略——预热和自适应阶段,在CREMA-D(80.65%),AVE(70.40%)和KineticSound(72.42%)上产生了最先进的性能。通过GMM识别的高质量样本进行微调进一步提高了结果,突出了它们对于有效多模态融合的价值。
🔬 方法详解
问题定义:多模态学习中,不同模态的数据异质性导致模型训练时出现模态不平衡问题,即某些模态主导梯度更新,影响模型性能。现有方法主要集中于优化策略或数据增强,缺乏对模态不平衡的定量分析和有效利用,导致模型无法充分融合不同模态的信息。
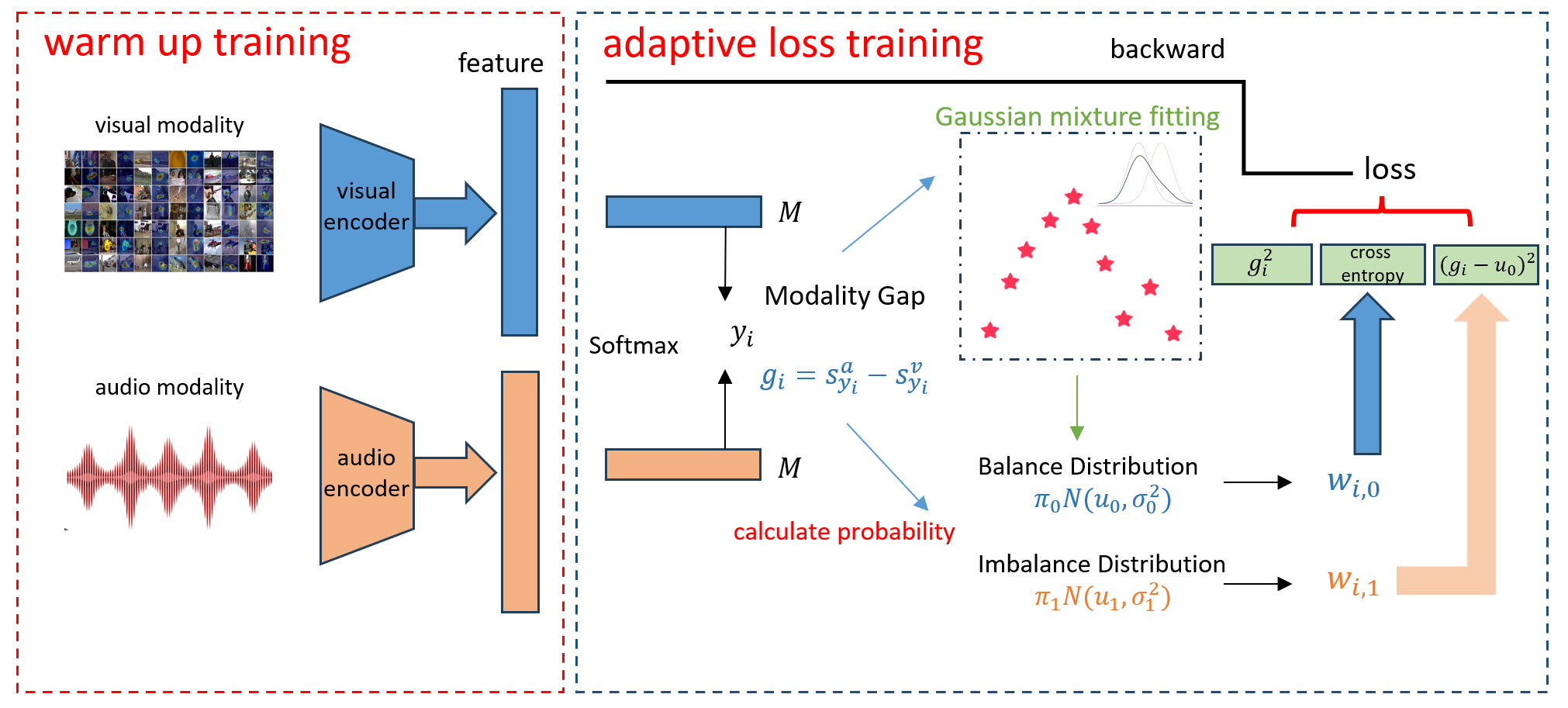
核心思路:论文的核心思路是量化多模态数据的不平衡程度,并根据不平衡程度自适应地调整损失函数。通过计算模态间的Softmax得分差异(模态差距),并使用高斯混合模型(GMM)对模态差距的分布进行建模,区分平衡和不平衡样本。然后,根据样本属于平衡或不平衡群体的后验概率,自适应地调整损失权重,从而缓解模态不平衡问题。
技术框架:整体框架包含两个阶段:预热阶段和自适应阶段。在预热阶段,使用标准的交叉熵损失进行训练,为后续的GMM建模提供基础。在自适应阶段,首先计算每个样本的模态差距,然后使用GMM对模态差距的分布进行建模,估计每个样本属于平衡或不平衡群体的后验概率。最后,根据后验概率自适应地调整损失权重,并使用调整后的损失函数进行训练。
关键创新:最重要的创新点在于提出了一个量化多模态不平衡程度的框架,并设计了一个样本级别的自适应损失函数。与现有方法相比,该方法能够更精确地识别不平衡样本,并根据其不平衡程度动态地调整损失权重,从而更有效地缓解模态不平衡问题。
关键设计:关键设计包括:1) 使用Softmax得分差异(模态差距)来量化模态不平衡程度;2) 使用双峰GMM对模态差距的分布进行建模,区分平衡和不平衡样本;3) 使用贝叶斯定理估计每个样本属于平衡或不平衡群体的后验概率;4) 根据后验概率自适应地调整损失权重,具体来说,对于不平衡样本,增加其损失权重,使其更关注平衡样本,从而缓解模态不平衡问题。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在CREMA-D、AVE和KineticSound数据集上取得了显著的性能提升,分别达到了80.65%、70.40%和72.42%的准确率,超越了现有的SOTA方法。此外,通过GMM识别的高质量样本进行微调,进一步提高了模型性能,验证了GMM在多模态融合中的价值。
🎯 应用场景
该研究成果可广泛应用于音视频分析、情感识别、多模态内容理解等领域。例如,在视频监控中,可以利用音频和视频信息进行异常事件检测;在人机交互中,可以结合语音和面部表情进行情感识别。该方法能够提升多模态融合模型的性能和鲁棒性,具有重要的实际应用价值。
📄 摘要(原文)
The heterogeneity of multimodal data leads to inconsistencies and imbalance, allowing a dominant modality to steer gradient updates. Existing solutions mainly focus on optimization- or data-based strategies but rarely exploit the information inherent in multimodal imbalance or conduct its quantitative analysis. To address this gap, we propose a novel quantitative analysis framework for Multimodal Imbalance and design a sample-level adaptive loss function. We define the Modality Gap as the Softmax score difference between modalities for the correct class and model its distribution using a bimodal Gaussian Mixture Model(GMM), representing balanced and imbalanced samples. Using Bayes' theorem, we estimate each sample's posterior probability of belonging to these two groups. Based on this, our adaptive loss (1) minimizes the overall Modality Gap, (2) aligns imbalanced samples with balanced ones, and (3) adaptively penalizes each according to its imbalance degree. A two-stage training strategy-warm-up and adaptive phases,yields state-of-the-art performance on CREMA-D (80.65%), AVE (70.40%), and KineticSound (72.42%). Fine-tuning with high-quality samples identified by the GMM further improves results, highlighting their value for effective multimodal fusion.