Efficient Long-context Language Model Training by Core Attention Disaggregation
作者: Yonghao Zhuang, Junda Chen, Bo Pang, Yi Gu, Yibo Zhu, Yimin Jiang, Ion Stoica, Eric Xing, Hao Zhang
分类: cs.LG, cs.DC
发布日期: 2025-10-20
💡 一句话要点
提出核心注意力解耦(CAD)技术,高效训练长文本语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本模型 注意力机制 分布式训练 负载均衡 语言模型训练
📋 核心要点
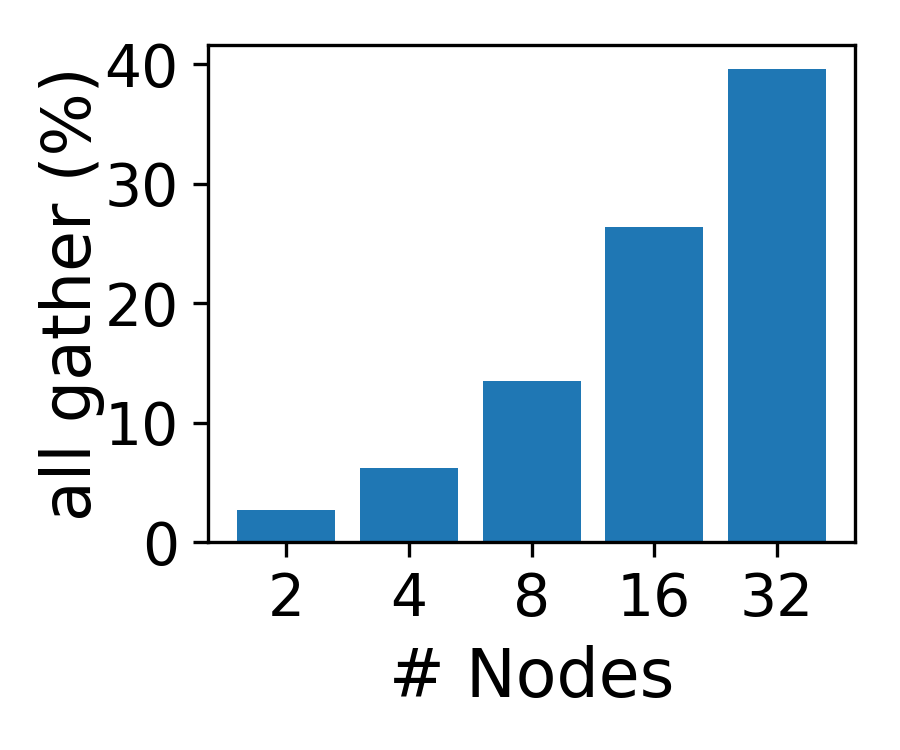
- 现有长文本语言模型训练中,核心注意力计算的二次复杂度导致负载不均衡和训练延迟。
- 核心注意力解耦(CAD)将核心注意力计算分离到专用服务器,动态调度任务以均衡计算负载。
- DistCA系统在512个H200 GPU上,将512k上下文长度的端到端训练吞吐量提高了1.35倍。
📝 摘要(中文)
本文提出核心注意力解耦(CAD)技术,通过将核心注意力计算softmax(QK^T)V从模型的其余部分分离出来,并在独立的设备池上执行,从而改进长上下文大型语言模型的训练。在现有系统中,核心注意力与其他层共置;在长上下文长度下,与其他组件的近线性增长相比,其二次计算增长会导致数据和流水线并行组之间的负载不平衡和延迟。CAD基于两个观察结果。首先,核心注意力是无状态的:它没有可训练的参数,只有最少的瞬态数据,因此平衡简化为调度计算密集型任务。其次,它是可组合的:现代注意力内核在处理具有任意长度的token级分片的融合批次时,仍保持高效率。CAD将核心注意力划分为token级任务,并将它们分派到专用的注意力服务器,这些服务器动态地重新批处理任务以均衡计算,而不会牺牲内核效率。我们在一个名为DistCA的系统中实现了CAD,该系统使用乒乓执行方案来完全重叠通信和计算,并在注意力服务器上进行原地执行以减少内存使用。在512个H200 GPU和高达512k token的上下文长度下,DistCA将端到端训练吞吐量提高了高达1.35倍,消除了数据和流水线并行延迟,并实现了接近完美的计算和内存平衡。
🔬 方法详解
问题定义:现有长文本语言模型训练面临核心注意力计算瓶颈,其复杂度随上下文长度呈二次方增长,导致数据并行和流水线并行训练时出现负载不均衡和训练延迟(stragglers)。现有系统将核心注意力计算与其他层共置,无法有效利用硬件资源,限制了长文本模型的训练效率。
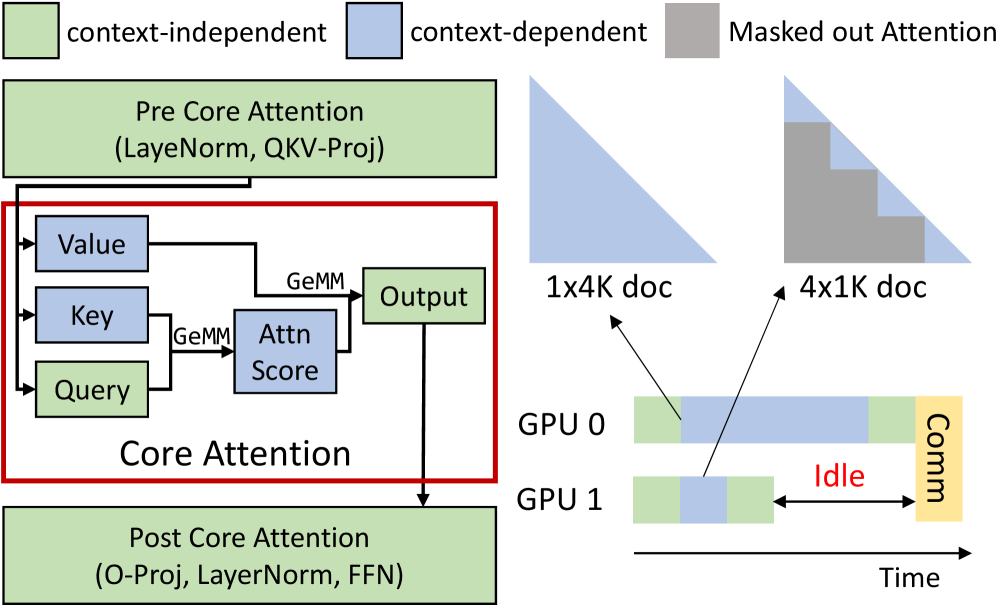
核心思路:核心注意力解耦(CAD)的核心思想是将核心注意力计算(softmax(QK^T)V)从模型的其他部分分离出来,并将其卸载到一组专用的注意力服务器上。这些服务器负责动态地重新批处理token级别的注意力计算任务,以实现计算负载的均衡。这种解耦允许更有效地利用硬件资源,并减少了训练过程中的延迟。
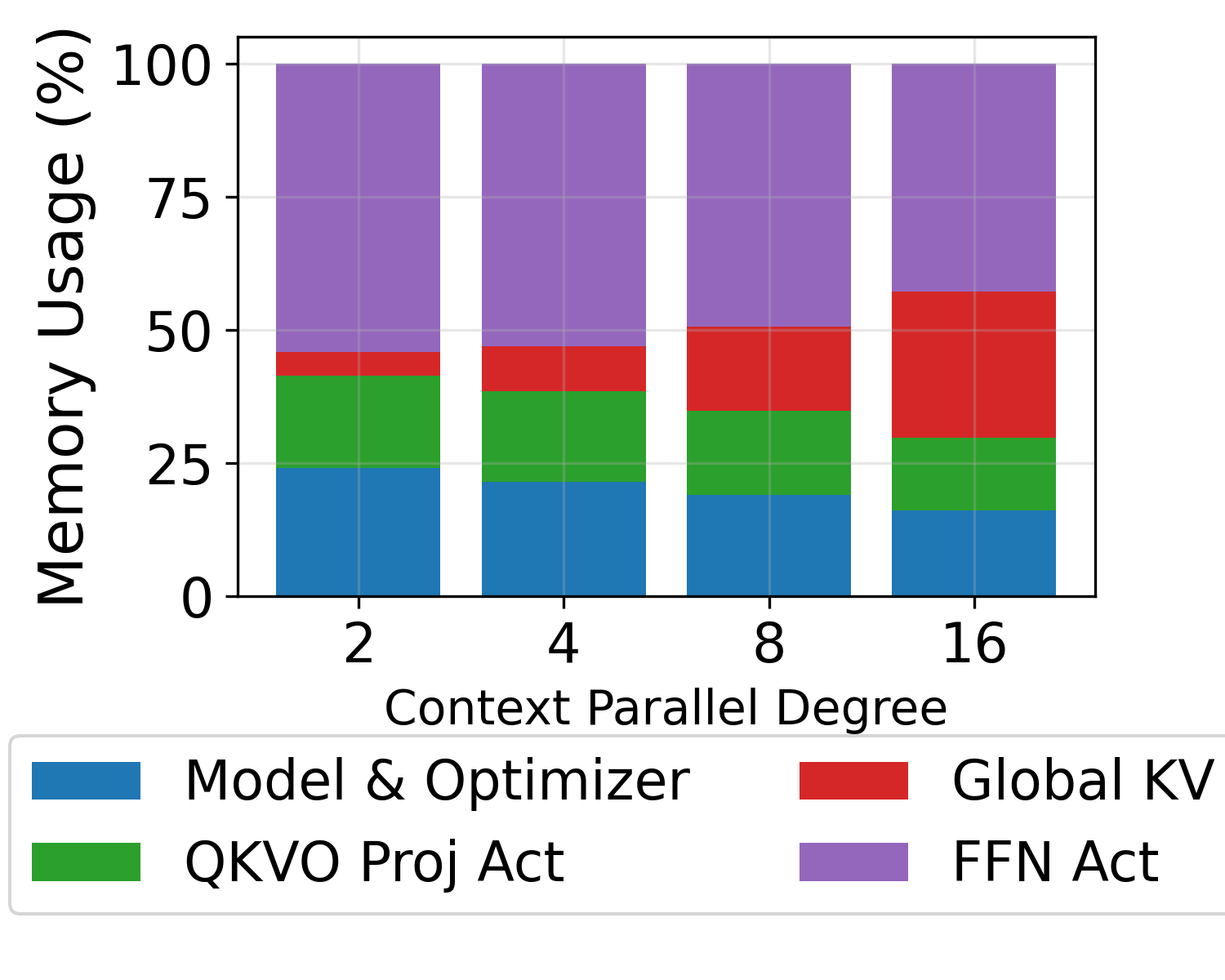
技术框架:DistCA系统实现了CAD技术,采用了一种乒乓执行方案,以完全重叠通信和计算。该系统包括以下主要模块:1)主模型:负责模型的其他层的计算。2)注意力服务器:负责核心注意力计算,动态调度token级别的任务。3)调度器:负责将token级别的注意力计算任务分配给注意力服务器。DistCA利用原地执行(in-place execution)来减少注意力服务器上的内存使用。
关键创新:CAD的关键创新在于将核心注意力计算视为无状态且可组合的任务。无状态性意味着核心注意力计算没有可训练参数,只有最小的瞬态数据,因此负载均衡简化为调度计算密集型任务。可组合性意味着现代注意力内核在处理具有任意长度的token级分片的融合批次时,仍保持高效率。这种解耦和动态调度机制能够有效地解决长文本训练中的负载不均衡问题。
关键设计:DistCA的关键设计包括:1)乒乓执行方案:通过重叠通信和计算来提高效率。2)动态任务调度:根据注意力服务器的负载情况动态地分配token级别的注意力计算任务。3)原地执行:减少注意力服务器上的内存使用。这些设计共同实现了高效的长文本语言模型训练。
🖼️ 关键图片
📊 实验亮点
DistCA系统在512个H200 GPU上,针对高达512k token的上下文长度,实现了高达1.35倍的端到端训练吞吐量提升。该系统有效地消除了数据并行和流水线并行训练中的延迟,并实现了接近完美的计算和内存平衡,证明了CAD技术的有效性。
🎯 应用场景
该研究成果可应用于各种需要处理长文本序列的场景,例如长篇文档摘要、代码生成、复杂问答系统、以及需要理解长期依赖关系的任务。通过提高长文本模型的训练效率,可以降低训练成本,并促进更大规模、更强大的语言模型的开发。
📄 摘要(原文)
We present core attention disaggregation (CAD), a technique that improves long-context large language model training by decoupling the core attention computation, softmax(QK^T)V, from the rest of the model and executing it on a separate pool of devices. In existing systems, core attention is colocated with other layers; at long context lengths, its quadratic compute growth compared to the near-linear growth of other components causes load imbalance and stragglers across data and pipeline parallel groups. CAD is enabled by two observations. First, core attention is stateless: it has no trainable parameters and only minimal transient data, so balancing reduces to scheduling compute-bound tasks. Second, it is composable: modern attention kernels retain high efficiency when processing fused batches of token-level shards with arbitrary lengths. CAD partitions core attention into token-level tasks and dispatches them to dedicated attention servers, which dynamically rebatch tasks to equalize compute without sacrificing kernel efficiency. We implement CAD in a system called DistCA, which uses a ping-pong execution scheme to fully overlap communication with computation and in-place execution on attention servers to reduce memory use. On 512 H200 GPUs and context lengths up to 512k tokens, DistCA improves end-to-end training throughput by up to 1.35x, eliminates data and pipeline parallel stragglers, and achieves near-perfect compute and memory balance.