Any-Depth Alignment: Unlocking Innate Safety Alignment of LLMs to Any-Depth
作者: Jiawei Zhang, Andrew Estornell, David D. Baek, Bo Li, Xiaojun Xu
分类: cs.LG, cs.AI
发布日期: 2025-10-20
💡 一句话要点
Any-Depth Alignment (ADA)解锁LLM的深度安全对齐,无需模型参数修改。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全对齐 对抗攻击 推理时防御 深度学习
📋 核心要点
- 现有LLM安全对齐存在深度不足的问题,容易受到对抗攻击和有害预填充攻击的影响。
- ADA通过在生成过程中重新引入助手头部token,诱导模型重新评估有害性,从而实现任意深度的安全对齐。
- 实验表明,ADA在多种开源模型上实现了强大的安全性能,有效防御对抗攻击,同时保持了良性任务的效用。
📝 摘要(中文)
大型语言模型(LLM)表现出强大但浅层的对齐:当助手回合一开始就预期拒绝时,它们会直接拒绝有害查询,但一旦有害延续开始(通过对抗性攻击或有害助手预填充攻击),这种保护就会崩溃。这提出了一个根本问题:LLM中固有的浅层对齐能否被解锁,以确保任意生成深度的安全性?为了实现这个目标,我们提出了Any-Depth Alignment (ADA),这是一种有效的推理时防御,开销可忽略不计。ADA建立在我们观察到的对齐集中在助手头部token中的基础上,这些token通过在浅层拒绝训练中重复使用,拥有模型强大的对齐先验。通过在中流重新引入这些token,ADA诱导模型重新评估有害性,并在生成的任何时候恢复拒绝。在不同的开源模型系列(Llama、Gemma、Mistral、Qwen、DeepSeek和gpt-oss)中,ADA实现了强大的安全性能,而无需对基础模型的参数进行任何更改。它确保了近100%的拒绝率,以应对从几十个到几千个token的具有挑战性的对抗性预填充攻击。此外,ADA将突出的对抗性提示攻击(如GCG、AutoDAN、PAIR和TAP)的平均成功率降低到3%以下。所有这些都是在保持良性任务的效用的同时,以最小的过度拒绝完成的。即使在基础模型经过后续的指令微调(良性或对抗性)后,ADA也能保持这种弹性。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的安全对齐通常较为浅层,即模型在对话开始时能够识别并拒绝有害请求,但当有害内容通过对抗性攻击或有害的助手预填充等方式潜入生成过程中时,模型的安全机制往往失效。因此,需要解决的问题是如何提升LLM在任意生成深度上的安全对齐能力,使其能够持续识别并拒绝有害内容。
核心思路:论文的核心思路是利用LLM在浅层拒绝训练中形成的对齐先验知识,这些知识集中体现在助手头部token中。通过在生成过程中周期性地重新引入这些token,可以促使模型重新评估当前生成内容的有害性,从而恢复拒绝有害内容的能力。这种方法无需修改模型参数,仅在推理阶段进行干预。
技术框架:ADA的核心在于推理阶段的token重引入机制。具体流程如下:在LLM生成token的过程中,每隔一定步数,将预先选定的助手头部token重新插入到token序列中。这些token携带了模型在浅层拒绝训练中学习到的安全对齐信息,能够引导模型重新评估当前生成内容的安全性。通过这种方式,ADA可以在任意生成深度上激活模型的安全机制。
关键创新:ADA最重要的创新点在于其无需修改模型参数,仅通过推理时的token操作即可显著提升LLM的深度安全对齐能力。与传统的对抗训练或微调方法相比,ADA具有更高的效率和更低的成本,同时也避免了对模型原有能力的破坏。
关键设计:ADA的关键设计包括:1) 助手头部token的选择:选择在浅层拒绝训练中频繁出现的token,这些token代表了模型对安全对齐的强烈先验。2) 重引入频率:需要根据具体模型和任务调整重引入频率,以在安全性和生成质量之间取得平衡。3) token插入位置:通常选择在生成序列的适当位置插入token,以避免破坏句子的流畅性。
🖼️ 关键图片
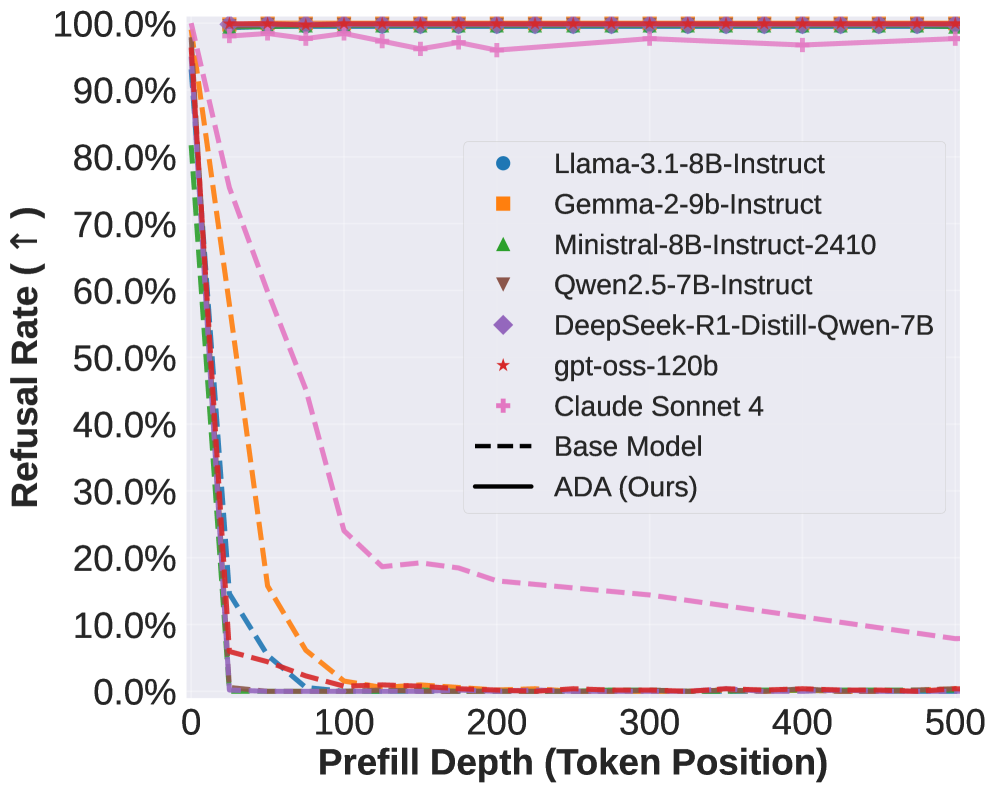


📊 实验亮点
ADA在多种开源LLM(Llama、Gemma、Mistral等)上实现了显著的安全性能提升。针对对抗性预填充攻击,ADA实现了近100%的拒绝率。对于GCG、AutoDAN等对抗性提示攻击,ADA将攻击成功率降低到3%以下。同时,ADA对良性任务的效用影响很小,过度拒绝率较低。这些实验结果表明,ADA是一种有效且实用的LLM安全防御方法。
🎯 应用场景
ADA技术可广泛应用于各种需要安全保障的LLM应用场景,例如智能客服、内容生成、教育辅导等。通过提升LLM的深度安全对齐能力,可以有效防止模型生成有害、不当或误导性内容,从而降低应用风险,提升用户体验,并促进LLM技术的健康发展。未来,ADA可以与其他安全防御技术相结合,构建更加完善的LLM安全体系。
📄 摘要(原文)
Large Language Models (LLMs) exhibit strong but shallow alignment: they directly refuse harmful queries when a refusal is expected at the very start of an assistant turn, yet this protection collapses once a harmful continuation is underway (either through the adversarial attacks or via harmful assistant-prefill attacks). This raises a fundamental question: Can the innate shallow alignment in LLMs be unlocked to ensure safety at arbitrary generation depths? To achieve this goal, we propose Any-Depth Alignment (ADA), an effective inference-time defense with negligible overhead. ADA is built based on our observation that alignment is concentrated in the assistant header tokens through repeated use in shallow-refusal training, and these tokens possess the model's strong alignment priors. By reintroducing these tokens mid-stream, ADA induces the model to reassess harmfulness and recover refusals at any point in generation. Across diverse open-source model families (Llama, Gemma, Mistral, Qwen, DeepSeek, and gpt-oss), ADA achieves robust safety performance without requiring any changes to the base model's parameters. It secures a near-100% refusal rate against challenging adversarial prefill attacks ranging from dozens to thousands of tokens. Furthermore, ADA reduces the average success rate of prominent adversarial prompt attacks (such as GCG, AutoDAN, PAIR, and TAP) to below 3%. This is all accomplished while preserving utility on benign tasks with minimal over-refusal. ADA maintains this resilience even after the base model undergoes subsequent instruction tuning (benign or adversarial).