MEG-GPT: A transformer-based foundation model for magnetoencephalography data
作者: Rukuang Huang, Sungjun Cho, Chetan Gohil, Oiwi Parker Jones, Mark Woolrich
分类: cs.LG
发布日期: 2025-10-20
💡 一句话要点
MEG-GPT:基于Transformer的脑磁图数据基础模型,提升神经解码性能。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑磁图 基础模型 Transformer 时间注意力 神经解码
📋 核心要点
- 传统方法难以捕捉脑磁图(MEG)等模态中复杂的大脑动态时空模式,限制了神经科学研究。
- MEG-GPT利用Transformer架构,结合时间注意力机制和下一时间点预测,构建MEG数据的基础模型。
- 实验表明,MEG-GPT在下游解码任务中表现优异,零样本泛化能力显著提升,并可通过微调进一步提高性能。
📝 摘要(中文)
本文提出MEG-GPT,一个基于Transformer的脑磁图(MEG)数据基础模型,它使用时间注意力机制和下一时间点预测。同时,作者还提出了一种新颖的、数据驱动的tokeniser,用于连续MEG数据,该tokeniser保留了连续MEG信号的高时间分辨率,而没有有损变换。MEG-GPT在一个大规模MEG数据集(N=612,闭眼静息态,Cam-CAN数据)上进行训练,该数据集提取了tokenised的脑区时间序列。实验表明,该模型能够生成具有真实时空谱属性的数据,包括瞬态事件和群体变异性。关键的是,它在下游解码任务中表现良好,改进了下游监督预测任务,在会话间(准确率从0.54提高到0.59)和被试间(准确率从0.41提高到0.49)表现出更好的零样本泛化能力。此外,该模型可以有效地在一个较小的标记数据集上进行微调,以提高跨被试解码场景中的性能。这项工作为脑电生理数据建立了一个强大的基础模型,为计算神经科学和神经解码的应用铺平了道路。
🔬 方法详解
问题定义:论文旨在解决脑磁图(MEG)数据分析中,传统方法难以有效捕捉复杂时空动态模式的问题。现有方法通常无法充分利用MEG数据的高时间分辨率和丰富的空间信息,导致在神经解码等任务中性能受限。
核心思路:论文的核心思路是借鉴自然语言处理领域的Transformer模型,构建一个能够学习MEG数据内在表示的基础模型。通过在大规模无标签数据上进行预训练,使模型能够捕捉MEG信号的时空依赖关系,从而提升在下游任务中的泛化能力。
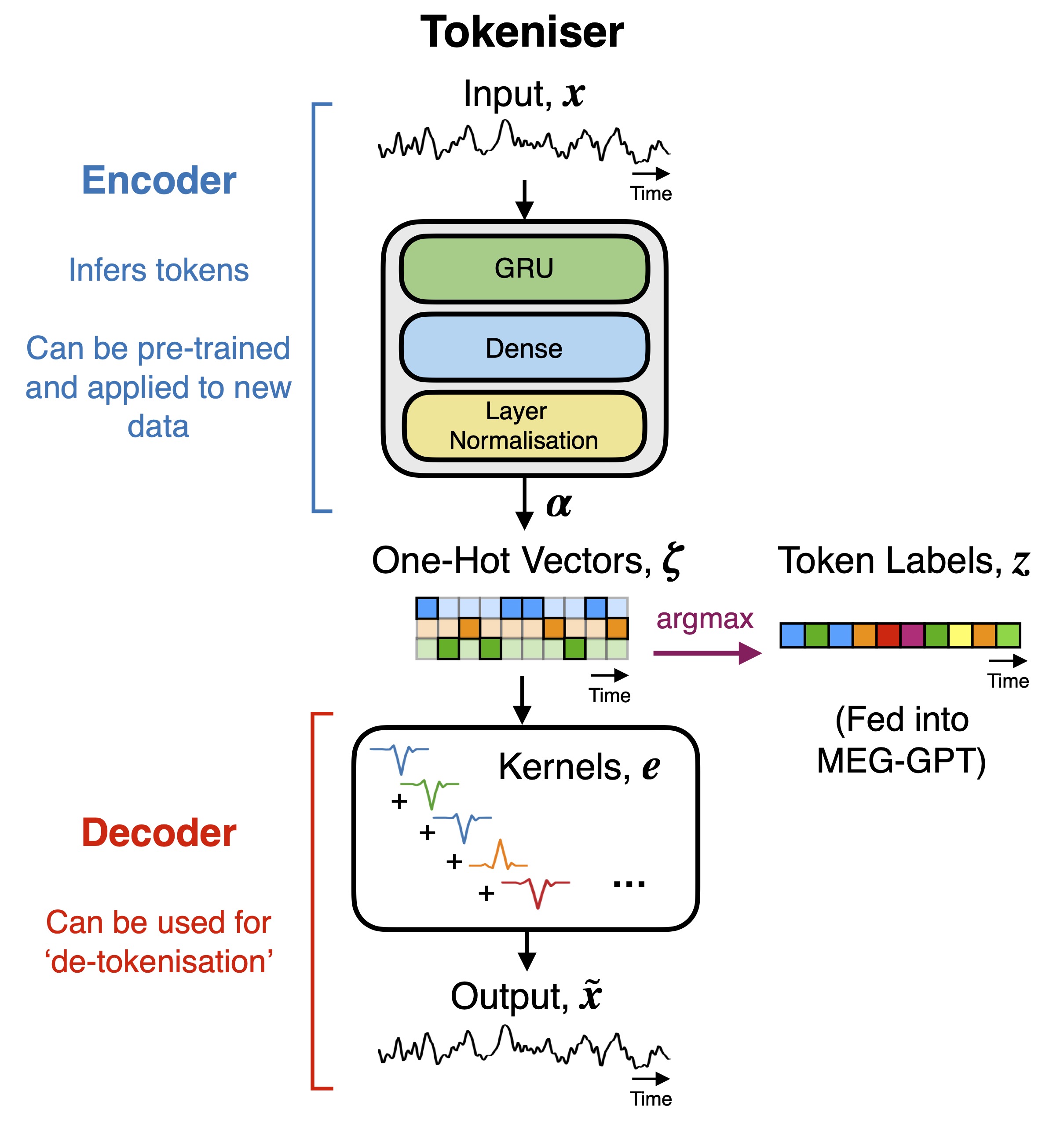
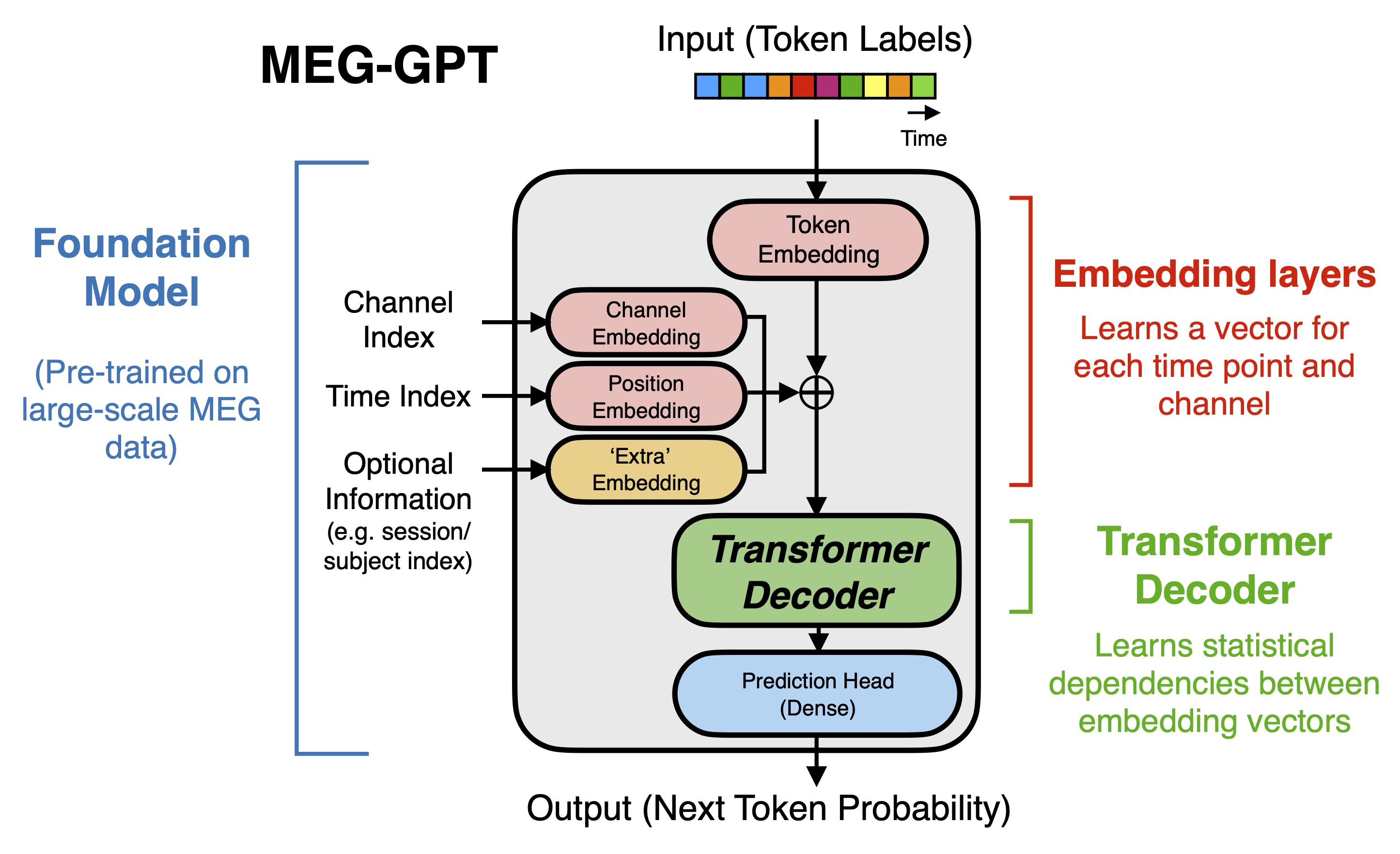
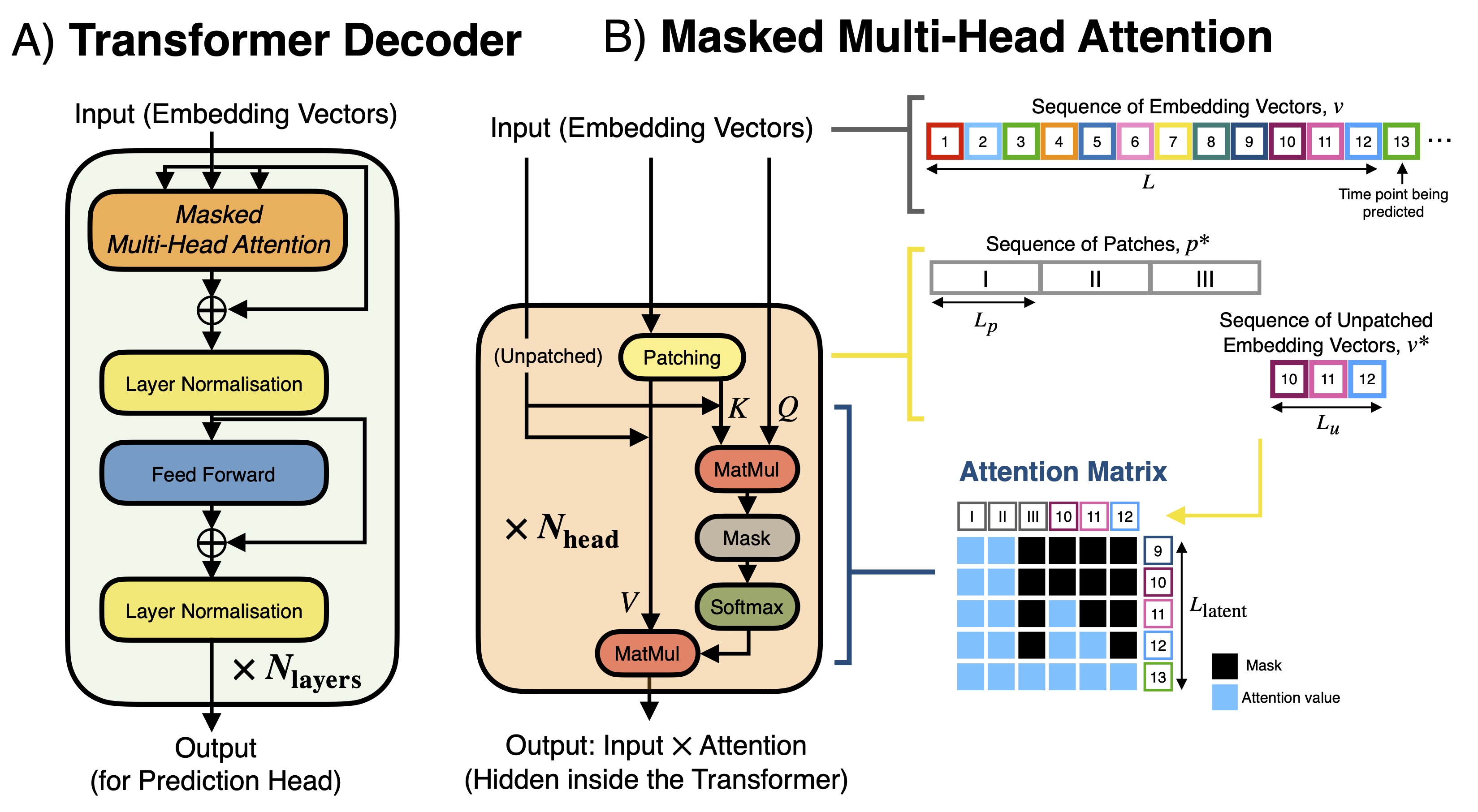
技术框架:MEG-GPT的整体框架包括数据tokenisation、Transformer模型构建和训练、以及下游任务微调三个主要阶段。首先,使用数据驱动的tokeniser将连续MEG信号转换为离散的token序列。然后,构建基于Transformer的模型,利用时间注意力机制学习token序列的表示。最后,在特定下游任务上对预训练模型进行微调,以提升性能。
关键创新:论文的关键创新在于:1) 提出了一种适用于连续MEG数据的tokeniser,能够保留高时间分辨率信息;2) 构建了基于Transformer的MEG数据基础模型,能够有效学习MEG信号的时空依赖关系;3) 验证了该模型在下游解码任务中的有效性,并展示了其零样本泛化能力和微调潜力。
关键设计:MEG-GPT的关键设计包括:1) 数据驱动的tokeniser,通过聚类算法将MEG信号划分为不同的token;2) 基于Transformer的模型架构,采用时间注意力机制捕捉时间依赖关系;3) 下一时间点预测作为预训练目标,鼓励模型学习MEG信号的动态演化规律;4) 实验中使用了大规模的Cam-CAN MEG数据集进行预训练,并选择了多个下游解码任务进行评估。
🖼️ 关键图片
📊 实验亮点
MEG-GPT在下游解码任务中表现出显著的性能提升。在跨会话零样本泛化任务中,准确率从基线的0.54提高到0.59;在跨被试零样本泛化任务中,准确率从0.41提高到0.49。此外,通过在小规模标记数据集上进行微调,MEG-GPT在跨被试解码任务中取得了进一步的性能提升,验证了其作为基础模型的有效性。
🎯 应用场景
MEG-GPT作为脑电生理数据的基础模型,可广泛应用于计算神经科学和神经解码领域。例如,可用于研究大脑动态活动模式、诊断神经系统疾病、开发脑机接口等。该模型有望推动我们对大脑功能的理解,并为相关疾病的治疗提供新的思路。
📄 摘要(原文)
Modelling the complex spatiotemporal patterns of large-scale brain dynamics is crucial for neuroscience, but traditional methods fail to capture the rich structure in modalities such as magnetoencephalography (MEG). Recent advances in deep learning have enabled significant progress in other domains, such as language and vision, by using foundation models at scale. Here, we introduce MEG-GPT, a transformer based foundation model that uses time-attention and next time-point prediction. To facilitate this, we also introduce a novel data-driven tokeniser for continuous MEG data, which preserves the high temporal resolution of continuous MEG signals without lossy transformations. We trained MEG-GPT on tokenised brain region time-courses extracted from a large-scale MEG dataset (N=612, eyes-closed rest, Cam-CAN data), and show that the learnt model can generate data with realistic spatio-spectral properties, including transient events and population variability. Critically, it performs well in downstream decoding tasks, improving downstream supervised prediction task, showing improved zero-shot generalisation across sessions (improving accuracy from 0.54 to 0.59) and subjects (improving accuracy from 0.41 to 0.49) compared to a baseline methods. Furthermore, we show the model can be efficiently fine-tuned on a smaller labelled dataset to boost performance in cross-subject decoding scenarios. This work establishes a powerful foundation model for electrophysiological data, paving the way for applications in computational neuroscience and neural decoding.