Batch Distillation Data for Developing Machine Learning Anomaly Detection Methods
作者: Justus Arweiler, Indra Jungjohann, Aparna Muraleedharan, Heike Leitte, Jakob Burger, Kerstin Münnemann, Fabian Jirasek, Hans Hasse
分类: cs.LG
发布日期: 2025-10-20
💡 一句话要点
构建批量精馏异常检测机器学习方法开发所需的大规模开放实验数据集
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 异常检测 机器学习 化学过程 批量精馏 实验数据 公开数据集 核磁共振光谱 数据标注
📋 核心要点
- 化学过程中异常检测缺乏公开实验数据,阻碍了机器学习方法的发展。
- 构建实验室规模的批量精馏装置,生成包含正常和异常数据的实验数据库。
- 提供传感器数据、浓度曲线、视频音频等多种数据,以及元数据和专家标注。
📝 摘要(中文)
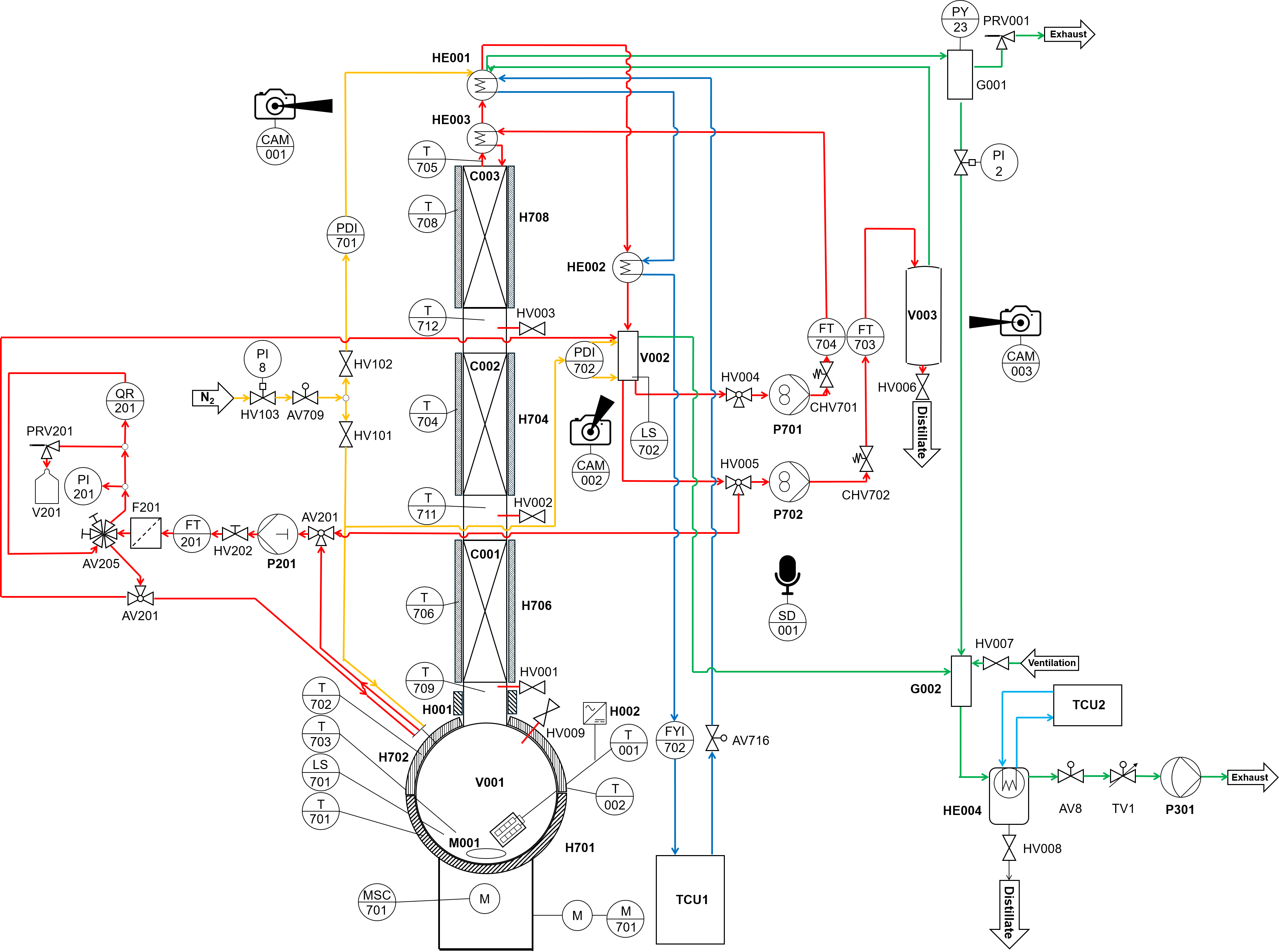
机器学习在推进化学过程中的异常检测方面具有巨大潜力。然而,基于机器学习的方法的开发受到缺乏公开可用的实验数据的阻碍。为了解决这个问题,我们建立了一个实验室规模的批量精馏装置,并运行它以生成一个广泛的实验数据库,该数据库涵盖无故障实验和有意引入异常的实验,用于训练先进的基于机器学习的异常检测方法。总共进行了119次实验,涵盖了广泛的运行条件和混合物。大多数包含异常的实验都与相应的无故障实验配对。我们在此提供的数据包括来自众多传感器和执行器的时间序列数据,以及测量不确定性的估计。此外,还提供了非常规数据源,例如通过在线台式核磁共振光谱法获得的浓度曲线以及视频和音频记录。包括所有实验的广泛元数据和专家注释。异常注释基于本工作中开发的本体。数据以结构化数据库形式组织,并通过doi.org/10.5281/zenodo.17395544免费提供。这个新的数据库为开发先进的基于机器学习的异常检测方法铺平了道路。由于它包含有关异常原因的信息,因此它进一步支持开发可解释和可解释的机器学习方法,以及异常缓解方法。
🔬 方法详解
问题定义:论文旨在解决化学过程中基于机器学习的异常检测方法开发缺乏公开实验数据的问题。现有方法由于缺乏高质量、多样化的实验数据,难以训练出鲁棒性和泛化性强的异常检测模型。
核心思路:论文的核心思路是通过构建一个实验室规模的批量精馏装置,并进行大量的实验,生成一个包含正常和异常数据的实验数据库。该数据库不仅包含传统的传感器数据,还包括非常规数据源,如在线核磁共振光谱数据和音视频数据,从而为机器学习模型的训练提供更丰富的信息。
技术框架:该研究的技术框架主要包括以下几个部分:1) 批量精馏装置的搭建和运行;2) 实验数据的采集,包括传感器数据、在线核磁共振光谱数据、音视频数据等;3) 实验数据的预处理和清洗;4) 异常标注,基于开发的本体进行专家标注;5) 数据库的构建和发布。
关键创新:该研究的关键创新在于构建了一个包含多种数据源的、大规模的、公开可用的化学过程异常检测实验数据库。该数据库不仅包含传统的传感器数据,还包括非常规数据源,如在线核磁共振光谱数据和音视频数据,从而为机器学习模型的训练提供更丰富的信息。此外,该研究还开发了一个用于异常标注的本体,从而提高了标注的准确性和一致性。
关键设计:实验设计涵盖了广泛的运行条件和混合物,进行了119次实验,包括正常实验和有意引入异常的实验。异常标注基于开发的本体,由专家进行标注。数据库以结构化的形式组织,并通过doi.org/10.5281/zenodo.17395544免费提供。
🖼️ 关键图片


📊 实验亮点
该研究构建了一个包含119个批量精馏实验的大规模数据集,涵盖多种运行条件和混合物,并提供传感器数据、在线核磁共振光谱数据、音视频数据等多种数据源。该数据集还包含基于本体的专家异常标注,为开发可解释的异常检测模型提供了基础。该数据集已公开,为机器学习异常检测研究提供了宝贵资源。
🎯 应用场景
该研究成果可广泛应用于化学过程的异常检测、故障诊断和过程优化。该数据库为开发先进的基于机器学习的异常检测方法提供了数据基础,有助于提高化学过程的安全性和可靠性,降低生产成本,提高产品质量。未来,该数据库可以进一步扩展,包含更多的数据源和实验条件,从而更好地支持机器学习方法在化学过程中的应用。
📄 摘要(原文)
Machine learning (ML) holds great potential to advance anomaly detection (AD) in chemical processes. However, the development of ML-based methods is hindered by the lack of openly available experimental data. To address this gap, we have set up a laboratory-scale batch distillation plant and operated it to generate an extensive experimental database, covering fault-free experiments and experiments in which anomalies were intentionally induced, for training advanced ML-based AD methods. In total, 119 experiments were conducted across a wide range of operating conditions and mixtures. Most experiments containing anomalies were paired with a corresponding fault-free one. The database that we provide here includes time-series data from numerous sensors and actuators, along with estimates of measurement uncertainty. In addition, unconventional data sources -- such as concentration profiles obtained via online benchtop NMR spectroscopy and video and audio recordings -- are provided. Extensive metadata and expert annotations of all experiments are included. The anomaly annotations are based on an ontology developed in this work. The data are organized in a structured database and made freely available via doi.org/10.5281/zenodo.17395544. This new database paves the way for the development of advanced ML-based AD methods. As it includes information on the causes of anomalies, it further enables the development of interpretable and explainable ML approaches, as well as methods for anomaly mitigation.