Fine-tuning Flow Matching Generative Models with Intermediate Feedback
作者: Jiajun Fan, Chaoran Cheng, Shuaike Shen, Xiangxin Zhou, Ge Liu
分类: cs.LG, cs.AI
发布日期: 2025-10-20
💡 一句话要点
提出AC-Flow框架,通过中间反馈微调Flow Matching生成模型,提升文图对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Flow Matching 生成模型 文本到图像生成 Actor-Critic 强化学习 中间反馈 奖励塑造
📋 核心要点
- 现有Flow Matching模型微调方法难以有效利用中间反馈,面临信用分配难题和训练不稳定性。
- AC-Flow框架通过奖励塑造、双重稳定性机制和广义评论器加权,实现稳定高效的微调。
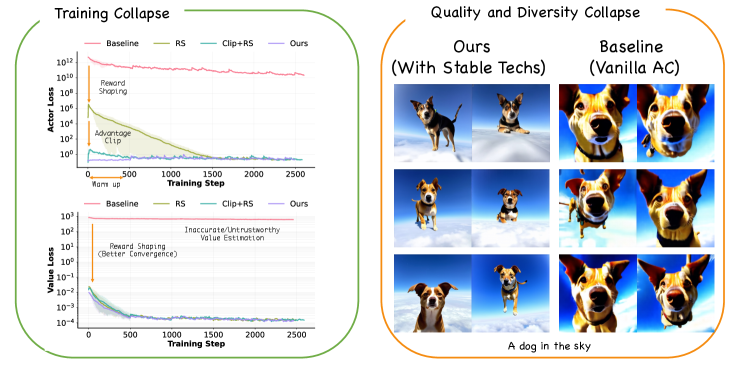
- 实验表明,AC-Flow在文图对齐和泛化能力上优于现有方法,且不影响生成质量和多样性。
📝 摘要(中文)
基于Flow的生成模型在文本到图像生成方面取得了显著成功,但利用中间反馈对其进行微调仍然具有挑战性,特别是对于连续时间Flow Matching模型。现有方法大多仅从最终奖励中学习,难以解决信用分配问题。尝试通过直接回归累积奖励来学习评论器(critic)的方法,在在线设置中经常面临训练不稳定和模型崩溃的问题。本文提出了一个鲁棒的Actor-Critic框架AC-Flow,通过三个关键创新来解决这些挑战:(1)奖励塑造,提供良好归一化的学习信号,以实现稳定的中间值学习和梯度控制;(2)一种新颖的双重稳定性机制,结合了优势裁剪(advantage clipping)以防止破坏性的策略更新,以及一个预热阶段,使评论器在影响Actor之前成熟;(3)一种可扩展的广义评论器加权方案,扩展了传统的奖励加权方法,同时通过Wasserstein正则化保持模型多样性。在Stable Diffusion 3上的大量实验表明,AC-Flow在文本到图像对齐任务和泛化到未见的人类偏好模型方面实现了最先进的性能。结果表明,即使使用计算效率高的评论器模型,我们也可以稳健地微调Flow模型,而不会影响生成质量、多样性或稳定性。
🔬 方法详解
问题定义:论文旨在解决连续时间Flow Matching生成模型在利用中间反馈进行微调时遇到的困难。现有方法主要依赖最终奖励,导致信用分配困难,难以有效利用中间过程的信息。而直接回归累积奖励的评论器训练方法,在在线学习环境中容易出现训练不稳定和模型崩溃的问题。
核心思路:论文的核心思路是设计一个鲁棒的Actor-Critic框架,通过更有效的奖励机制和稳定性控制策略,使Flow Matching模型能够更好地从中间反馈中学习。通过奖励塑造提供更清晰的学习信号,并利用双重稳定性机制防止训练过程中的剧烈波动。
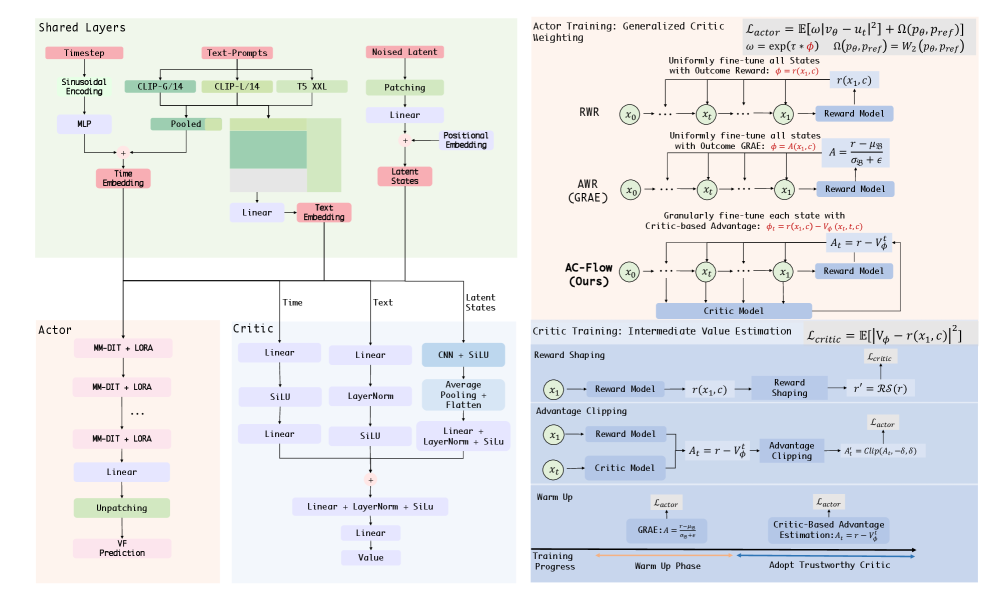
技术框架:AC-Flow框架包含一个Actor(Flow Matching生成模型)和一个Critic(价值函数估计器)。Actor负责生成图像,Critic负责评估生成图像的质量,并给出奖励信号。框架通过以下步骤进行训练:1. Actor生成图像;2. Critic评估图像并给出奖励;3. 奖励经过奖励塑造处理;4. Actor根据奖励更新生成策略;5. Critic更新价值函数。
关键创新:论文的关键创新在于三个方面:1. 奖励塑造:设计了一种奖励塑造方法,将原始奖励转化为更平滑、更易于学习的信号,从而提高训练的稳定性。2. 双重稳定性机制:结合了优势裁剪和预热阶段,防止Actor策略更新过快,并保证Critic在影响Actor之前已经充分训练。3. 广义评论器加权:扩展了传统的奖励加权方法,通过Wasserstein正则化保持模型的多样性。
关键设计:奖励塑造采用归一化和缩放操作,确保奖励信号在合适的范围内。优势裁剪限制了Actor策略更新的幅度。预热阶段允许Critic在Actor更新之前进行充分训练。广义评论器加权使用Wasserstein距离来衡量不同Critic之间的差异,并鼓励模型探索更多样化的生成结果。
🖼️ 关键图片

📊 实验亮点
AC-Flow在Stable Diffusion 3上进行了实验,结果表明,在文本到图像对齐任务上,AC-Flow取得了state-of-the-art的性能。同时,AC-Flow在泛化到未见的人类偏好模型方面也表现出色,证明了其鲁棒性和泛化能力。实验结果还表明,即使使用计算效率高的评论器模型,AC-Flow也能稳健地微调Flow模型,而不会影响生成质量、多样性或稳定性。
🎯 应用场景
该研究成果可应用于各种需要根据人类反馈进行图像生成的场景,例如个性化图像生成、图像编辑、以及AI辅助设计等。通过更有效地利用中间反馈,可以生成更符合人类偏好和需求的图像,提高用户体验和工作效率。未来,该方法有望扩展到其他生成模型和模态,例如视频生成和3D内容生成。
📄 摘要(原文)
Flow-based generative models have shown remarkable success in text-to-image generation, yet fine-tuning them with intermediate feedback remains challenging, especially for continuous-time flow matching models. Most existing approaches solely learn from outcome rewards, struggling with the credit assignment problem. Alternative methods that attempt to learn a critic via direct regression on cumulative rewards often face training instabilities and model collapse in online settings. We present AC-Flow, a robust actor-critic framework that addresses these challenges through three key innovations: (1) reward shaping that provides well-normalized learning signals to enable stable intermediate value learning and gradient control, (2) a novel dual-stability mechanism that combines advantage clipping to prevent destructive policy updates with a warm-up phase that allows the critic to mature before influencing the actor, and (3) a scalable generalized critic weighting scheme that extends traditional reward-weighted methods while preserving model diversity through Wasserstein regularization. Through extensive experiments on Stable Diffusion 3, we demonstrate that AC-Flow achieves state-of-the-art performance in text-to-image alignment tasks and generalization to unseen human preference models. Our results demonstrate that even with a computationally efficient critic model, we can robustly finetune flow models without compromising generative quality, diversity, or stability.